
A brand new buzzword is making waves within the tech world, and it goes by a number of names: massive language mannequin optimization (LLMO), generative engine optimization (GEO) or generative AI optimization (GAIO).
At its core, GEO is about optimizing how generative AI functions current your merchandise, manufacturers, or web site content material of their outcomes. For simplicity, I’ll consult with this idea as GEO all through this text.
I’ve beforehand explored whether or not it’s potential to form the outputs of generative AI programs. That dialogue was my preliminary foray into the subject of GEO.
Since then, the panorama has developed quickly, with new generative AI functions capturing important consideration. It’s time to delve deeper into this fascinating space.
Platforms like ChatGPT, Google AI Overviews, Microsoft Copilot and Perplexity are revolutionizing how customers search and eat info and reworking how companies and types can acquire visibility in AI-generated content material.
A fast disclaimer: no confirmed strategies exist but on this subject.
It’s nonetheless too new, harking back to the early days of website positioning when search engine rating components had been unknown and progress relied on testing, analysis and a deep technological understanding of knowledge retrieval and search engines like google and yahoo.
Understanding the panorama of generative AI
Understanding how pure language processing (NLP) and massive language fashions (LLMs) operate is essential on this early stage.
A strong grasp of those applied sciences is crucial for figuring out future potential in website positioning, digital model constructing and content material methods.
The approaches outlined listed below are based mostly on my analysis of scientific literature, generative AI patents and over a decade of expertise working with semantic search.
How massive language fashions work
Core performance of LLMs
Earlier than partaking with GEO, it’s important to have a fundamental understanding of the expertise behind LLMs.
Very similar to search engines like google and yahoo, understanding the underlying mechanisms helps keep away from chasing ineffective hacks or false suggestions.
Investing just a few hours to understand these ideas can save sources by steering away from pointless measures.
What makes LLMs revolutionary
LLMs, similar to GPT fashions, Claude or LLaMA, signify a transformative leap in search expertise and generative AI.
They alter how search engines like google and yahoo and AI assistants course of and reply to queries by transferring past easy textual content matching to ship nuanced, contextually wealthy solutions.
LLMs reveal exceptional capabilities in language comprehension and reasoning that transcend easy textual content matching to supply extra nuanced and contextual responses, per analysis like Microsoft’s “Giant Search Mannequin: Redefining Search Stack within the Period of LLMs.”
Core performance in search
The core performance of LLMs in search is to course of queries and produce pure language summaries.
As an alternative of simply extracting info from present paperwork, these fashions can generate complete solutions whereas sustaining accuracy and relevance.
That is achieved by a unified framework that treats all (search-related) duties as textual content era issues.
What makes this method significantly highly effective is its potential to customise solutions by pure language prompts. The system first generates an preliminary set of question outcomes, which the LLM refines and improves.
If further info is required, the LLM can generate supplementary queries to gather extra complete knowledge.
The underlying processes of encoding and decoding are key to their performance.
The encoding course of
Encoding entails processing and structuring coaching knowledge into tokens, that are elementary models utilized by language fashions.
Tokens can signify phrases, n-grams, entities, pictures, movies or complete paperwork, relying on the appliance.
It’s necessary to notice, nevertheless, that LLMs don’t “perceive” within the human sense – they course of knowledge statistically fairly than comprehending it.
Remodeling tokens into vectors
Within the subsequent step, tokens are reworked into vectors, forming the inspiration of Google’s transformer expertise and transformer-based language fashions.
This breakthrough was a recreation changer in AI and is a key issue within the widespread adoption of AI fashions at this time.
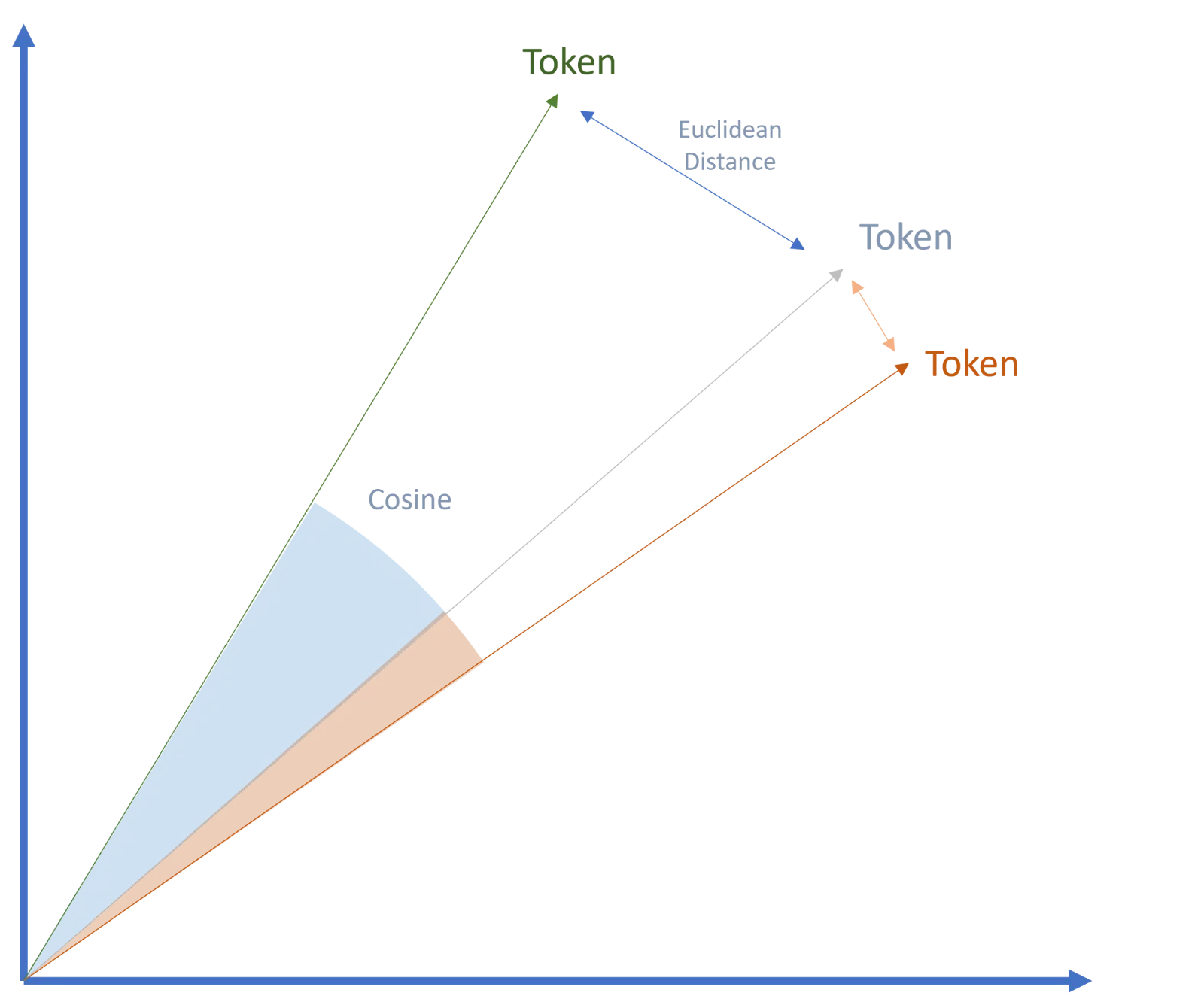
Vectors are numerical representations of tokens, with the numbers capturing particular attributes that describe the properties of every token.
These properties enable vectors to be categorised inside semantic areas and associated to different vectors, a course of generally known as embeddings.
The semantic similarity and relationships between vectors can then be measured utilizing strategies like cosine similarity or Euclidean distance.
The decoding course of
Decoding is about deciphering the chances that the mannequin calculates for every potential subsequent token (phrase or image).
The purpose is to create essentially the most wise or pure sequence. Totally different strategies, similar to high Okay sampling or high P sampling, can be utilized when decoding.
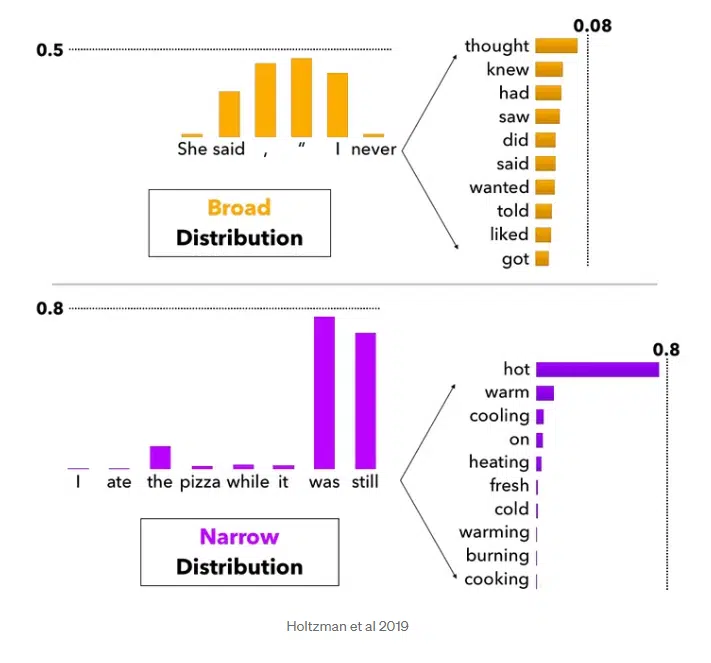
Probably, subsequent phrases are evaluated with a likelihood rating. Relying on how excessive the “creativity scope” of the mannequin is, the highest Okay phrases are thought of as potential subsequent phrases.
In fashions with a broader interpretation, the next phrases may also be taken under consideration along with the High 1 likelihood and thus be extra inventive within the output.
This additionally explains potential completely different outcomes for a similar immediate. With fashions which might be “strictly” designed, you’ll at all times get comparable outcomes.
Past textual content: The multimedia capabilities of generative AI
The encoding and decoding processes in generative AI depend on pure language processing.
Through the use of NLP, the context window will be expanded to account for grammatical sentence construction, enabling the identification of essential and secondary entities throughout pure language understanding.
Generative AI extends past textual content to incorporate multimedia codecs like audio and, sometimes, visuals.
Nonetheless, these codecs are sometimes reworked into textual content tokens throughout the encoding course of for additional processing. (This dialogue focuses on text-based generative AI, which is essentially the most related for GEO functions.)
Dig deeper: The right way to win with generative engine optimization whereas holding website positioning top-tier
Challenges and developments in generative AI
Main challenges for generative AI embody guaranteeing info stays up-to-date, avoiding hallucinations, and delivering detailed insights on particular subjects.
Primary LLMs are sometimes educated on superficial info, which might result in generic or inaccurate responses to particular queries.
To handle this, retrieval-augmented era has change into a broadly used technique.
Retrieval-augmented era: An answer to info challenges
RAG provides LLMs with further topic-specific knowledge, serving to them overcome these challenges extra successfully.
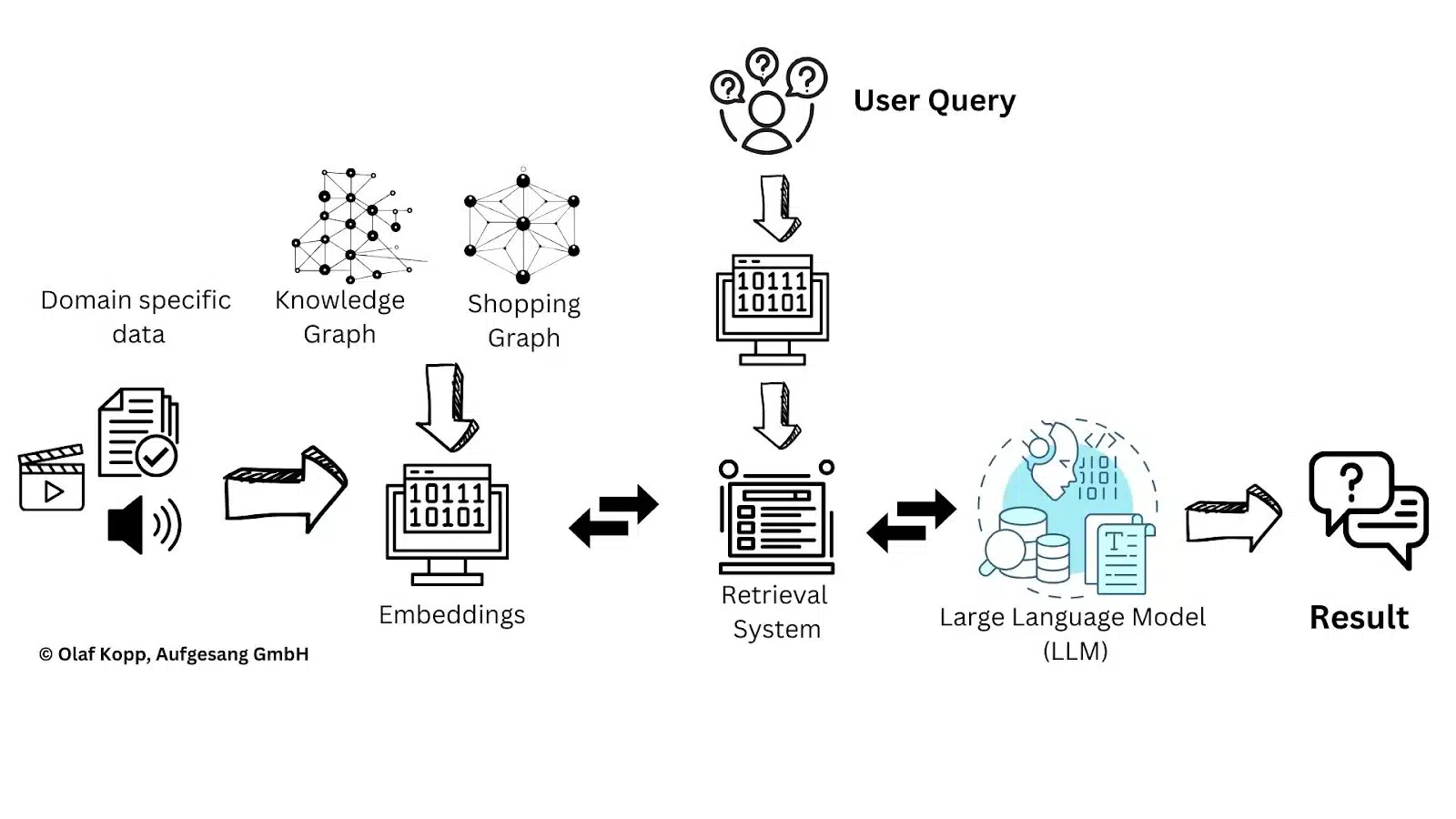
Along with paperwork, topic-specific info may also be built-in utilizing data graphs or entity nodes reworked into vectors.
This permits the inclusion of ontological details about relationships between entities, transferring nearer to true semantic understanding.
RAG provides potential beginning factors for GEO. Whereas figuring out or influencing the sources within the preliminary coaching knowledge will be difficult, GEO permits for a extra focused concentrate on most popular topic-specific sources.
The important thing query is how completely different platforms choose these sources, which relies on whether or not their functions have entry to a retrieval system able to evaluating and choosing sources based mostly on relevance and high quality.
The essential position of retrieval fashions
Retrieval fashions play a vital position within the RAG structure by appearing as info gatekeepers.
They search by massive datasets to determine related info for textual content era, functioning like specialised librarians who know precisely which “books” to retrieve on a given subject.
These fashions use algorithms to judge and choose essentially the most pertinent knowledge, enabling the mixing of exterior data into textual content era. This enhances context-rich language output and expands the capabilities of conventional language fashions.
Retrieval programs will be carried out by numerous mechanisms, together with:
- Vector embeddings and vector search.
- Doc index databases utilizing strategies like BM25 and TF-IDF.
Retrieval approaches of main AI platforms
Not all programs have entry to such retrieval programs, which presents challenges for RAG.
This limitation might clarify why Meta is now working by itself search engine, which might enable it to leverage RAG inside its LLaMA fashions utilizing a proprietary retrieval system.
Perplexity claims to make use of its personal index and rating programs, although there are accusations that it scrapes or copies search outcomes from different engines like Google.
Claude’s method stays unclear concerning whether or not it makes use of RAG alongside its personal index and user-provided info.
Gemini, Copilot and ChatGPT differ barely. Microsoft and Google leverage their very own search engines like google and yahoo for RAG or domain-specific coaching.
ChatGPT has traditionally used Bing search, however with the introduction of SearchGPT, it’s unsure if OpenAI operates its personal retrieval system.
OpenAI has said that SearchGPT employs a mixture of search engine applied sciences, together with Microsoft Bing.
“The search mannequin is a fine-tuned model of GPT-4o, post-trained utilizing novel artificial knowledge era strategies, together with distilling outputs from OpenAI o1-preview. ChatGPT search leverages third-party search suppliers, in addition to content material offered immediately by our companions, to supply the knowledge customers are searching for.”
Microsoft is considered one of ChatGPT’s companions.
When ChatGPT is requested about one of the best trainers, there may be some overlap between the top-ranking pages in Bing search outcomes and the sources utilized in its solutions, although the overlap is considerably lower than 100%.
Evaluating the retrieval-augmented era course of
Different components might affect the analysis of the RAG pipeline.
- Faithfulness: Measures the factual consistency of generated solutions towards the given context.
- Reply relevancy: Evaluates how pertinent the generated reply is to the given immediate.
- Context precision: Assesses whether or not related objects within the contexts are ranked appropriately, with scores from 0-1.
- Facet critique:Evaluates submissions based mostly on predefined elements like harmlessness and correctness, with potential to outline customized analysis standards.
- Groundedness: Measures how properly solutions align with and will be verified towards supply info, guaranteeing claims are substantiated by the context.
- Supply references: Having citations and hyperlinks to authentic sources permits verification and helps determine retrieval points.
- Distribution and protection: Making certain balanced illustration throughout completely different supply paperwork and sections by managed sampling.
- Correctness/Factual accuracy: Whether or not generated content material accommodates correct information.
- Imply common precision (MAP): Evaluates the general precision of retrieval throughout a number of queries, contemplating each precision and doc rating. It calculates the imply of common precision scores for every question, the place precision is computed at every place within the ranked outcomes. The next MAP signifies higher retrieval efficiency, with related paperwork showing larger in search outcomes.
- Imply reciprocal rank (MRR): Measures how rapidly the primary related doc seems in search outcomes. It’s calculated by taking the reciprocal of the rank place of the primary related doc for every question, then averaging these values throughout all queries. For instance, if the primary related doc seems at place 4, the reciprocal rank could be 1/4. MRR is especially helpful when the place of the primary right outcome issues most.
- Stand-alone high quality: Evaluates how context-independent and self-contained the content material is, scored 1-5 the place 5 means the content material makes full sense by itself with out requiring further context.
Immediate vs. question
A immediate is extra complicated and aligned with pure language than typical search queries, which are sometimes only a collection of key phrases.
Prompts are sometimes framed with specific questions or coherent sentences, offering higher context and enabling extra exact solutions.
You will need to distinguish between optimizing for AI Overviews and AI assistant outcomes.
- AI Overviews, a Google SERP function, are usually triggered by search queries.
- Whereas AI assistants depend on extra complicated pure language prompts.
To bridge this hole, the RAG course of should convert the immediate right into a search question within the background, preserving essential context to successfully determine appropriate sources.
Objectives and techniques of GEO
The targets of GEO are usually not at all times clearly outlined in discussions.
Some concentrate on having their very own content material cited in referenced supply hyperlinks, whereas others goal to have their title, model or merchandise talked about immediately within the output of generative AI.
Each targets are legitimate however require completely different methods.
- Being cited in supply hyperlinks entails guaranteeing your content material is referenced.
- Whereas mentions in AI output depend on rising the probability of your entity – whether or not an individual, group or product – being included in related contexts.
A foundational step for each targets is to determine a presence amongst most popular or steadily chosen sources, as it is a prerequisite for reaching both purpose.
Do we have to concentrate on all LLMs?
The various outcomes of AI functions reveal that every platform makes use of its personal processes and standards for recommending named entities and choosing sources.
Sooner or later, it can seemingly be essential to work with a number of massive language fashions or AI assistants and perceive their distinctive functionalities. For SEOs accustomed to Google’s dominance, this can require an adjustment.
Over the approaching years, it will likely be important to watch which functions acquire traction in particular markets and industries and to know how every selects its sources.
Why are sure individuals, manufacturers or merchandise cited by generative AI?
Within the coming years, extra individuals will depend on AI functions to seek for services.
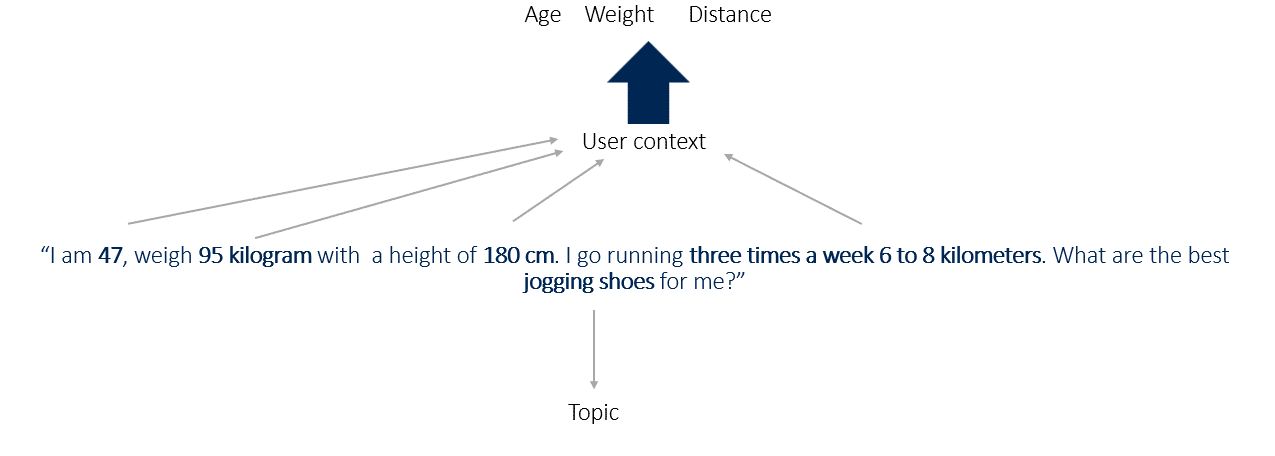
For instance, a immediate like:
- “I’m 47, weigh 95 kilograms, and am 180 cm tall. I’m going operating thrice per week, 6 to eight kilometers. What are one of the best jogging sneakers for me?”
This immediate supplies key contextual info, together with age, weight, top and distance as attributes, with jogging sneakers as the principle entity.
Merchandise steadily related to such contexts have the next probability of being talked about by generative AI.
Testing platforms like Gemini, Copilot, ChatGPT and Perplexity can reveal which contexts these programs contemplate.
Based mostly on the headings of the cited sources, all 4 programs seem to have deduced from the attributes that I’m chubby, producing info from posts with headings like:
- Greatest Operating Footwear for Heavy Runners (August 2024)
- 7 Greatest Operating Footwear For Heavy Males in 2024
- Greatest Operating Footwear for Heavy Males in 2024
- Greatest trainers for heavy feminine runners
- 7 Greatest Lengthy Distance Operating Footwear in 2024
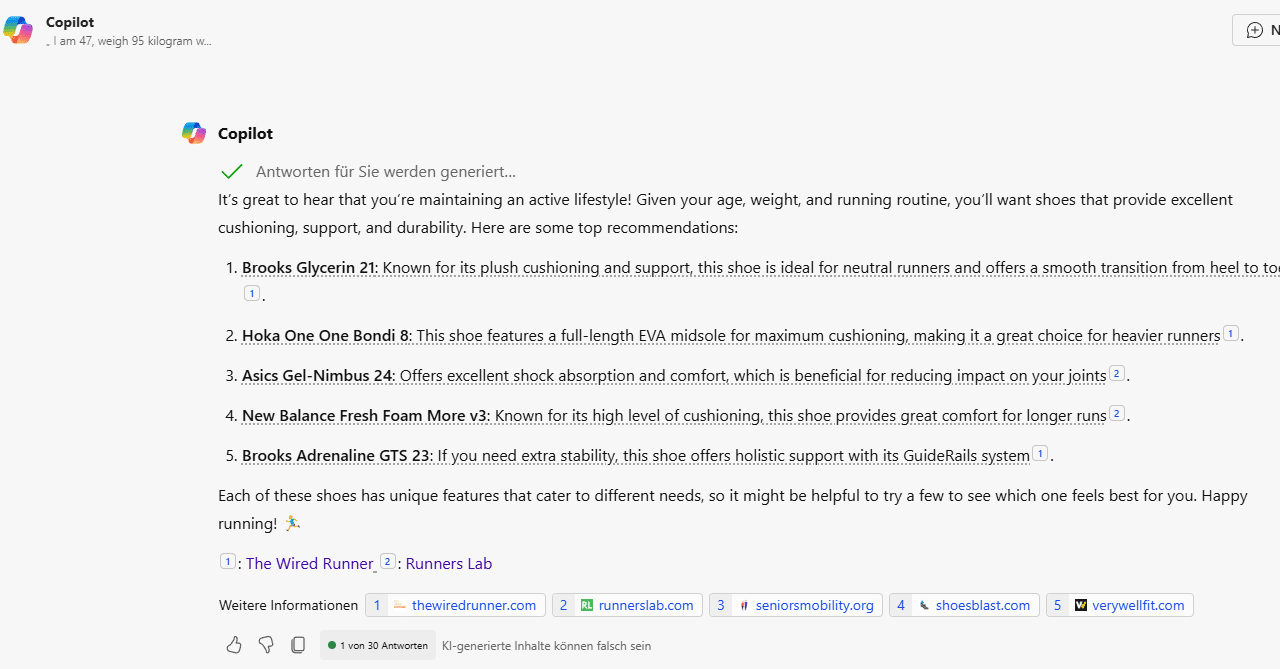
Copilot
Copilot considers attributes similar to age and weight.
Based mostly on the referenced sources, it identifies an chubby context from this info.
All cited sources are informational content material, similar to assessments, opinions and listicles, fairly than ecommerce class or product element pages.
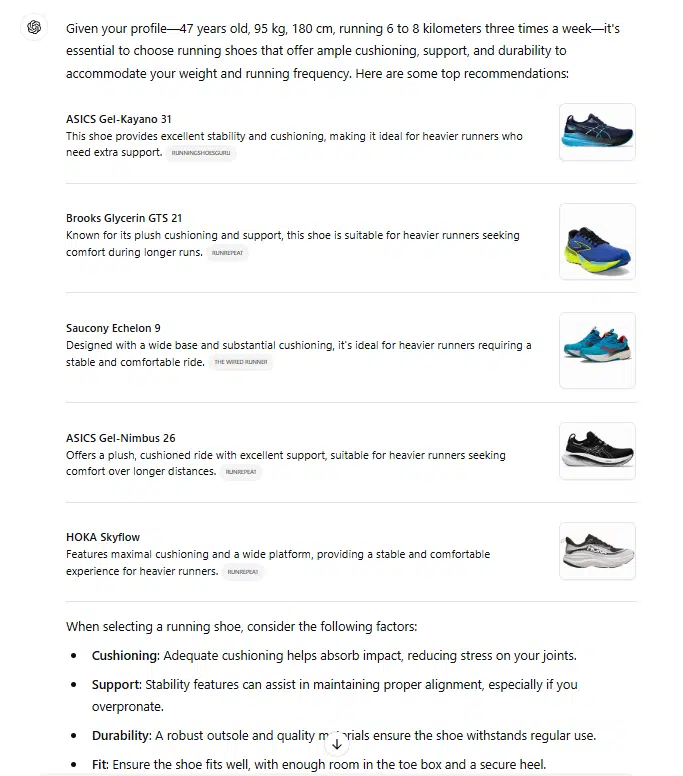
ChatGPT
ChatGPT takes attributes like distance and weight under consideration. From the referenced sources, it derives an chubby and long-distance context.
All cited sources are informational content material, similar to assessments, opinions and listicles, fairly than typical store pages like class or product element pages.
Perplexity
Perplexity considers the load attribute and derives an chubby context from the referenced sources.
The sources embody informational content material, similar to assessments, opinions, listicles and typical store pages.
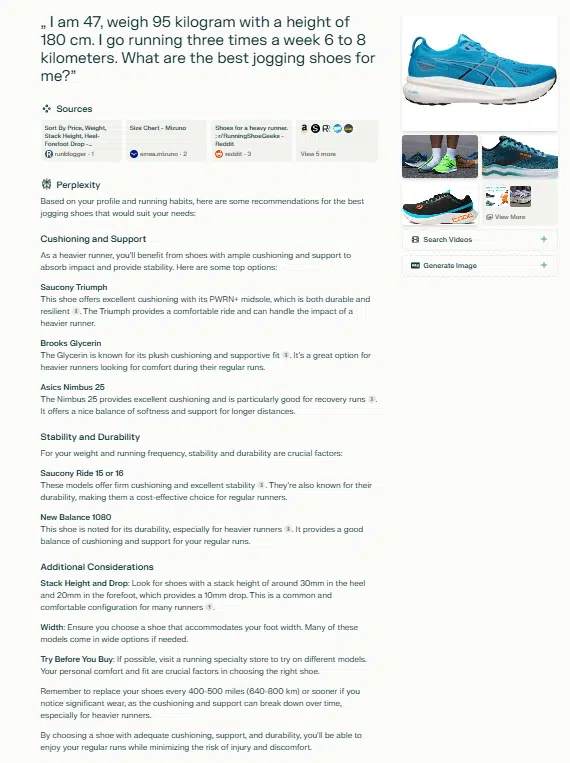
Gemini
Gemini doesn’t immediately present sources within the output. Nonetheless, additional investigation reveals that it additionally processes the contexts of age and weight.

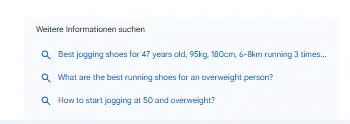
Every main LLM lists completely different merchandise, with just one shoe persistently advisable by all 4 examined AI programs.

All of the programs exhibit a level of creativity, suggesting various merchandise throughout completely different periods.
Notably, Copilot, Perplexity and ChatGPT primarily reference non-commercial sources, similar to store web sites or product element pages, aligning with the immediate’s function.
Claude was not examined additional. Whereas it additionally suggests shoe fashions, its suggestions are based mostly solely on preliminary coaching knowledge with out entry to real-time knowledge or its personal retrieval system.

As you possibly can see from the completely different outcomes, every LLM may have its personal course of of choosing sources and content material, making the GEO problem even higher.
The suggestions are influenced by co-occurrences, co-mentions and context.
The extra steadily particular tokens are talked about collectively, the extra seemingly they’re to be contextually associated.
In easy phrases, this will increase the likelihood rating throughout decoding.
Dig deeper: The right way to acquire visibility in generative AI solutions: GEO for Perplexity and ChatGPT
Get the e-newsletter search entrepreneurs depend on.
Supply and knowledge choice for retrieval-augmented era
GEO focuses on positioning merchandise, manufacturers and content material inside the coaching knowledge of LLMs. Understanding the coaching means of LLMs is essential for figuring out potential alternatives for inclusion.
The next insights are drawn from research, patents, scientific paperwork, analysis on E-E-A-T and private evaluation. The central questions are:
- How huge the affect of the retrieval programs is within the RAG course of.
- How necessary the preliminary coaching knowledge is.
- What different components can play a task.
Current research, significantly on supply choice for AI Overviews, Perplexity and Copilot, recommend overlaps in chosen sources.
For instance, Google AI Overviews present about 50% overlap in supply choice, as evidenced by research from Wealthy Sanger and Authoritas and Surfer.
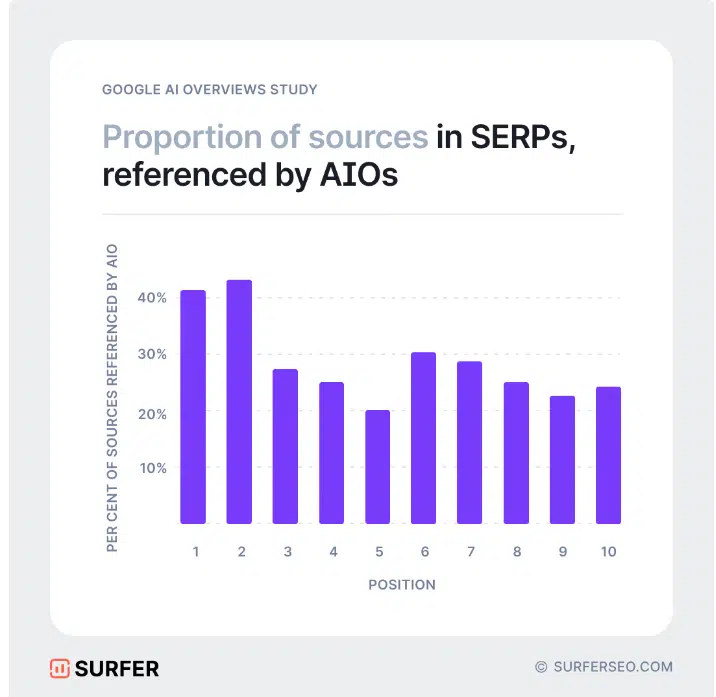
The fluctuation vary may be very excessive. The overlap in research from the start of 2024 was nonetheless round 15%. Nonetheless, some research discovered a 99% overlap.
The retrieval system seems to affect roughly 50% of the AI Overviews’ outcomes, suggesting ongoing experimentation to enhance efficiency. This aligns with justified criticism concerning the standard of AI Overview outputs.
The choice of referenced sources in AI solutions highlights the place it’s helpful to place manufacturers or merchandise in a contextually applicable approach.
It’s necessary to distinguish between sources used throughout the preliminary coaching of fashions and people added on a topic-specific foundation throughout the RAG course of.
Inspecting the mannequin coaching course of supplies readability. As an illustration, Google’s Gemini – a multimodal massive language mannequin – processes numerous knowledge varieties, together with textual content, pictures, audio, video and code.
Its coaching knowledge includes internet paperwork, books, code and multimedia, enabling it to carry out complicated duties effectively.
Research on AI Overviews and their most steadily referenced sources provide insights into which sources Google makes use of for its indices and data graph throughout pre-training, offering alternatives to align content material for inclusion.
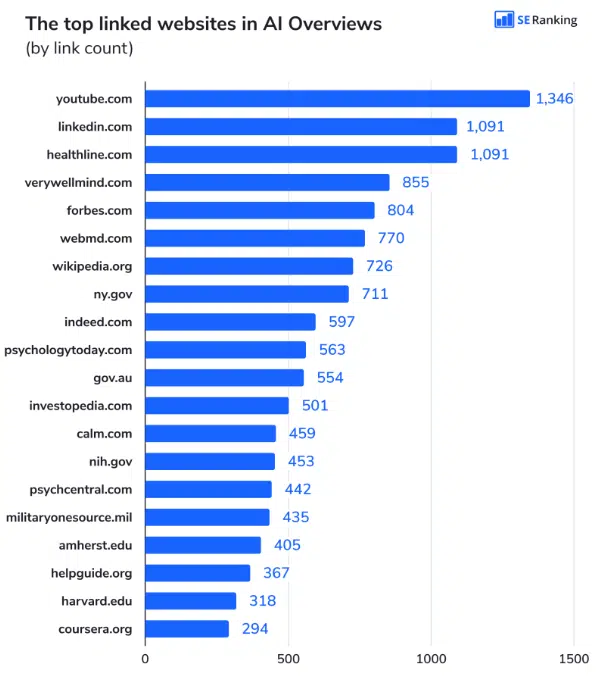
Within the RAG course of, domain-specific sources are included to reinforce contextual relevance.
A key function of Gemini is its use of a Combination of Specialists (MoE) structure.
In contrast to conventional Transformers, which function as a single massive neural community, an MoE mannequin is split into smaller “knowledgeable” networks.
The mannequin selectively prompts essentially the most related knowledgeable paths based mostly on the enter sort, considerably enhancing effectivity and efficiency.
The RAG course of is probably going built-in into this structure.
Gemini is developed by Google by a number of coaching phases, using publicly accessible knowledge and specialised strategies to maximise the relevance and precision of its generated content material:
Pre-training
- Much like different massive language fashions (LLMs), Gemini is first pre-trained on numerous public knowledge sources. Google applies numerous filters to make sure knowledge high quality and keep away from problematic content material.
- The coaching considers a versatile choice of seemingly phrases, permitting for extra inventive and contextually applicable responses.
Supervised fine-tuning (SFT)
- After pre-training, the mannequin is optimized utilizing high-quality examples both created by specialists or generated by fashions after which reviewed by specialists.
- This course of is much like studying good textual content construction and content material by seeing examples of well-written texts.
Reinforcement studying from human suggestions (RLHF)
- The mannequin is additional developed based mostly on human evaluations. A reward mannequin based mostly on consumer preferences helps Gemini acknowledge and be taught most popular response types and content material.
Extensions and retrieval augmentation
- Gemini can search exterior knowledge sources similar to Google Search, Maps, YouTube or particular extensions to supply contextual details about the response.
- For instance, when requested about present climate situations or information, Gemini might entry Google Search immediately to search out well timed, dependable knowledge and incorporate it into the response.
- Gemini performs search outcomes filtering to pick essentially the most related info for the reply. The mannequin takes under consideration the contextuality of the question and filters the information in order that it matches the query as carefully as potential.
- An instance of this may be a posh technical query the place the mannequin selects outcomes which might be scientific or technical in nature fairly than utilizing common internet content material.
- Gemini combines the knowledge retrieved from exterior sources with the mannequin output.
- This course of entails creating an optimized draft response that attracts on each the mannequin’s prior data and knowledge from the retrieved knowledge sources.
- The mannequin constructions the reply in order that the knowledge is logically introduced collectively and offered in a readable method.
- Every reply undergoes further overview to make sure that it meets Google’s high quality requirements and doesn’t comprise problematic or inappropriate content material.
- This safety verify is complemented by a rating that favors the very best quality variations of the reply. The mannequin then presents the highest-ranked reply to the consumer.
Consumer suggestions and steady optimization
- Google repeatedly integrates suggestions from customers and specialists to adapt the mannequin and repair any weak factors.
One risk is that AI functions entry present retrieval programs and use their search outcomes.
Research recommend {that a} robust rating within the respective search engine will increase the probability of being cited as a supply in linked AI functions.
Nonetheless, as famous, the overlaps don’t but present a transparent correlation between high rankings and referenced sources.
One other criterion seems to affect supply choice.
Google’s method, for instance, emphasizes adherence to high quality requirements when selecting sources for pre-training and RAG.
Using classifiers can be talked about as an element on this course of.

When naming classifiers, a bridge will be made to E-E-A-T, the place high quality classifiers are additionally used.
Data from Google concerning post-training additionally references utilizing E-E-A-T in classifying sources in keeping with high quality.

The reference to evaluators connects to the position of high quality raters in assessing E-E-A-T.

Rankings in most search engines like google and yahoo are influenced by relevance and high quality on the doc, area and creator or supply entity ranges.
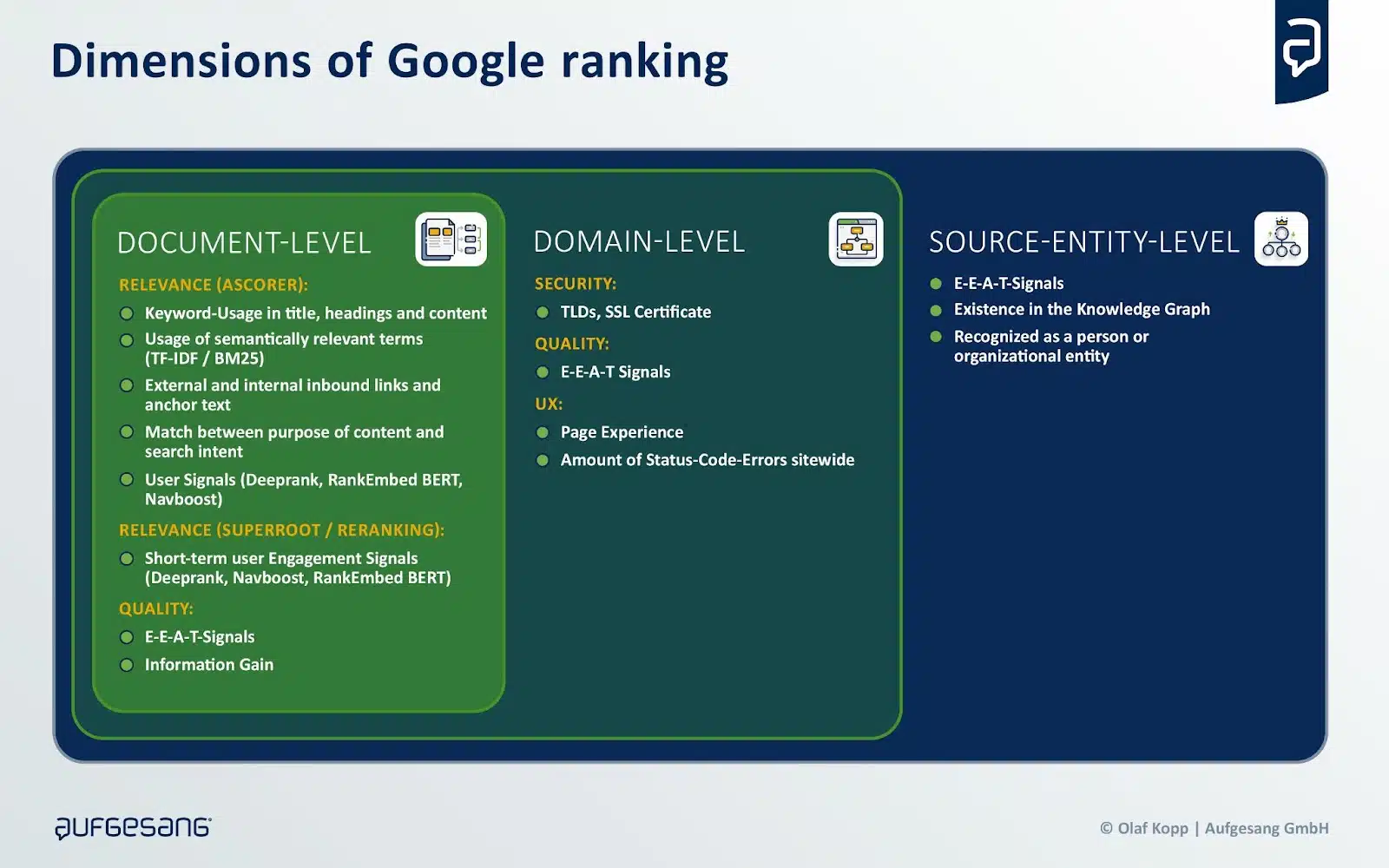
Sources could also be chosen much less for relevance and extra for high quality on the area and supply entity stage.
This could additionally make sense, as extra complicated prompts need to be rewritten within the background in order that applicable search queries are created to question the rankings.
Whereas relevance is query-dependent, high quality stays constant.
This distinction helps clarify the weak correlation between rankings and sources referenced by generative AI and why lower-ranking sources are generally included.
To evaluate high quality, search engines like google and yahoo like Google and Bing depend on classifiers, together with Google’s E-E-A-T framework.
Google has emphasised that E-E-A-T varies by topic space, necessitating topic-specific methods, significantly in GEO methods.
Referenced area sources differ by {industry} or subject, with platforms like Wikipedia, Reddit and Amazon taking part in various roles, in keeping with a BrightEdge research.
Thus, industry- and topic-specific components should be built-in into positioning methods.
Dig deeper: The right way to implement generative engine optimization (GEO) methods
Tactical and strategic approaches for LLMO / GEO
As beforehand famous, there are not any confirmed success tales but for influencing the outcomes of generative AI.
Platform operators themselves appear unsure about the way to qualify the sources chosen throughout the RAG course of.
These factors underscore the significance of figuring out the place optimization efforts ought to focus – particularly, figuring out which sources are sufficiently reliable and related to prioritize.
The following problem is knowing the way to set up your self as a type of sources.
The analysis paper “GEO: Generative Engine Optimization” launched the idea of GEO, exploring how generative AI outputs will be influenced and figuring out the components chargeable for this.
Based on the research, the visibility and effectiveness of GEO will be enhanced by the next components:
- Authority in writing: Improves efficiency, significantly on debate questions and queries in historic contexts, as extra persuasive writing is more likely to have extra worth in debate-like contexts.
- Citations (cite sources): Significantly helpful for factual questions, as they supply a supply of verification for the information offered, thereby rising the credibility of the reply.
- Statistical addition: Significantly efficient in fields similar to Legislation, Authorities and Opinion, the place incorporating related statistics into webpage content material can improve visibility in particular contexts.
- Citation addition: Most impactful in areas like Individuals and Society, Explanations and Historical past, seemingly as a result of these subjects usually contain private narratives or historic occasions the place direct quotes add authenticity and depth.
These components range in effectiveness relying on the area, suggesting that incorporating domain-specific, focused customizations into internet pages is crucial for elevated visibility.
The next tactical dos for GEO and LLMO will be derived from the paper:
- Use citable sources: Incorporate citable sources into your content material to extend credibility and authenticity, particularly factual ones
- Insert statistics: Add related statistics to strengthen your arguments, particularly in areas like Legislation and Authorities and opinion questions.
- Add quotes: Use quotes to counterpoint content material in areas similar to Individuals and Society, Explanations and Historical past as they add authenticity and depth.
- Area-specific optimization: Take into account the specifics of your area when optimizing, because the effectiveness of GEO strategies varies relying on the world.
- Deal with content material high quality: Deal with creating high-quality, related and informative content material that gives worth to customers.
Moreover, tactical don’ts may also be recognized:
- Keep away from key phrase stuffing: Conventional key phrase stuffing exhibits little to no enchancment in generative search engine responses and must be prevented.
- Don’t ignore the context: Keep away from producing content material that’s unrelated to the subject or doesn’t present any added worth for the consumer.
- Don’t overlook consumer intent: Don’t neglect the intent behind search queries. Be sure that your content material really solutions customers’ questions.
BrightEdge has outlined the next strategic issues based mostly on the aforementioned analysis:
Totally different impacts of backlinks and co-citations
- AI Overviews and Perplexity favor distinct area units relying on the {industry}.
- In healthcare and schooling, each platforms prioritize trusted sources like mayoclinic.org and coursera.com, making these or comparable domains key targets for efficient website positioning methods.
- Conversely, in sectors like ecommerce and finance, Perplexity exhibits a desire for domains similar to reddit.com, yahoo.com, and marketwatch.com.
- Tailoring website positioning efforts to those preferences by leveraging backlinks and co-citations can considerably improve efficiency.
Tailor-made methods for AI-powered search
- AI-powered search approaches should be personalized for every {industry}.
- As an illustration, Perplexity’s desire for reddit.com underscores the significance of group insights in ecommerce, whereas AI Overviews leans towards established overview and Q&A websites like consumerreports.org and quora.com.
- Entrepreneurs and SEOs ought to align their content material methods with these tendencies by creating detailed product opinions or fostering Q&A boards to help ecommerce manufacturers.
Anticipate adjustments within the quotation panorama
- SEOs should carefully monitor Perplexity’s most popular domains, particularly the platform’s reliance on reddit.com for community-driven content material.
- Google’s partnership with Reddit might affect Perplexity’s algorithms to prioritize Reddit’s content material additional. This development signifies a rising emphasis on user-generated content material.
- SEOs ought to stay proactive and adaptable, refining methods to align with Perplexity’s evolving quotation preferences to take care of relevance and effectiveness.
Beneath are industry-specific tactical and strategic measures for GEO.
B2B tech
- Set up a presence on authoritative tech domains, significantly techtarget.com, ibm.com, microsoft.com and cloudflare.com, that are acknowledged as trusted sources by each platforms.
- Leverage content material syndication on these established platforms to get cited as a trusted supply sooner.
- In the long run, construct your personal area authority by high-quality content material, as competitors for syndication spots will enhance.
- Enter into partnerships with main tech platforms and actively contribute content material there.
- Reveal experience by credentials, certifications and knowledgeable opinions to sign trustworthiness.
Ecommerce
- Set up a powerful presence on Amazon, as Perplexity’s platform is broadly used as a supply.
- Actively promote product opinions and user-generated content material on Amazon and different related platforms.
- Distribute product info through established vendor platforms and comparability websites
- Syndicate content material and associate with trusted domains.
- Keep detailed and up-to-date product descriptions on all gross sales platforms.
- Become involved on related specialist portals and group platforms similar to Reddit.
- Pursue a balanced advertising technique that depends on each exterior platforms and your personal area authority.
Persevering with schooling
- Construct reliable sources and collaborate with authoritative domains similar to coursera.org, usnews.com and bestcolleges.com, as these are thought of related by each programs.
- Create up-to-date, high-quality content material that AI programs classify as reliable. The content material must be clearly structured and supported by knowledgeable data.
- Construct an energetic presence on related platforms like Reddit as community-driven content material turns into more and more necessary.
- Optimize your personal content material for AI programs by clear structuring, clear headings and concise solutions to frequent consumer questions.
- Clearly spotlight high quality options similar to certifications and accreditations, as these enhance credibility.
Finance
- Construct a presence on reliable monetary portals similar to yahoo.com and marketwatch.com, as these are most popular sources by AI programs.
- Keep present and correct firm info on main platforms similar to Yahoo Finance.
- Create high-quality, factually right content material and help it with references to acknowledged sources.
- Construct an energetic presence in related Reddit communities as Reddit positive aspects traction as a supply for AI programs.
- Enter into partnerships with established monetary media to extend your personal visibility and credibility.
- Reveal experience by specialist data, certifications and knowledgeable opinions.
Well being
- Hyperlink and reference content material to trusted sources similar to mayoclinic.org, nih.gov and medlineplus.gov.
- Incorporate present medical analysis and developments into the content material.
- Present complete and well-researched medical info backed by official establishments.
- Depend on credibility and experience by certifications and {qualifications}.
- Conduct common content material updates with new medical findings.
- Pursue a balanced content material technique that each builds your personal area authority and leverages established healthcare platforms.
Insurance coverage
- Use reliable sources: Place content material on acknowledged domains similar to forbes.com and official authorities web sites (.gov), as these are thought of significantly credible by AI search engines like google and yahoo.
- Present present and correct info: Insurance coverage info should at all times be present and factually right. This significantly applies to product and repair descriptions.
- Content material syndication: Publish content material on authoritative platforms similar to Forbes or acknowledged specialist portals with the intention to be cited as a reliable supply extra rapidly.
- Emphasize native relevance: Content material must be tailored to regional markets and take native insurance coverage laws under consideration.
Eating places
- Construct and preserve a powerful presence on key overview platforms similar to Yelp, TripAdvisor, OpenTable and GrubHub.
- Actively promote and accumulate constructive rankings and opinions from friends.
- Present full and up-to-date info on these platforms (menus, opening occasions, photographs, and many others.).
- Work together with meals communities and specialised gastro platforms similar to Eater.com.
- Carry out native website positioning optimization as AI searches place a powerful emphasis on native relevance.
- Create and replace complete and well-maintained Wikipedia entries.
- Supply a seamless on-line reservation course of through related platforms.
- Present high-quality content material in regards to the restaurant on numerous channels.
Tourism / Journey
- Optimize presence on key journey platforms similar to TripAdvisor, Expedia, Kayak, Resorts.com and Reserving.com, as they’re seen as trusted sources by AI search engines like google and yahoo.
- Create complete content material with journey guides, ideas and genuine opinions.
- Optimize the reserving course of and make it user-friendly.
- Carry out native website positioning since AI searches are sometimes location-based.
- Be energetic on related platforms and encourage opinions.
- Offering high-quality content material with added worth for the consumer.
- Collaborate with trusted domains and companions.
The way forward for GEO and what it means for manufacturers
The importance of GEO for corporations hinges on whether or not future generations will adapt their search habits and shift from Google to different platforms.
Rising developments on this space ought to change into obvious within the coming years, doubtlessly affecting the search market share.
As an illustration, ChatGPT Search depends closely on Microsoft Bing’s search expertise.
If ChatGPT establishes itself as a dominant generative AI utility, rating properly on Microsoft Bing might change into essential for corporations aiming to affect AI-driven functions.
This improvement might provide Microsoft Bing a chance to achieve market share not directly.
Whether or not LLMO or GEO will evolve right into a viable technique for steering LLMs towards particular targets stays unsure.
Nonetheless, if it does, reaching the next targets might be important:
- Establishing owned media as a supply for LLM coaching knowledge by E-E-A-T rules.
- Producing mentions of the model and its merchandise in respected media.
- Creating co-occurrences of the model with related entities and attributes in authoritative media.
- Producing high-quality content material that ranks properly and is taken into account in RAG processes.
- Making certain inclusion in established graph databases just like the Information Graph or Procuring Graph.
The success of LLM optimization correlates with market dimension. In area of interest markets, it’s simpler to place a model inside its thematic context attributable to lowered competitors.
Fewer co-occurrences in certified media are required to affiliate the model with related attributes and entities in LLMs.
Conversely, in bigger markets, reaching this is tougher as a result of rivals usually have in depth PR and advertising sources and a well-established presence.
Implementing GEO or LLMO calls for considerably higher sources than conventional website positioning, because it entails influencing public notion at scale.
Firms should strategically put together for these shifts, which is the place frameworks like digital authority administration come into play. This idea helps organizations align structurally and operationally to achieve an AI-driven future.
Sooner or later, massive manufacturers are more likely to maintain substantial benefits in search engine rankings and generative AI outputs attributable to their superior PR and advertising sources.
Nonetheless, conventional website positioning can nonetheless play a task in coaching LLMs by leveraging high-ranking content material.
The extent of this affect relies on how retrieval programs weigh content material within the coaching course of.
Finally, corporations ought to prioritize the co-occurrence of their manufacturers/merchandise with related attributes and entities whereas optimizing for these relationships in certified media.
Dig deeper: 5 GEO developments shaping the way forward for search
Contributing authors are invited to create content material for Search Engine Land and are chosen for his or her experience and contribution to the search group. Our contributors work beneath the oversight of the editorial employees and contributions are checked for high quality and relevance to our readers. The opinions they categorical are their very own.

