
Velocity, scale, and collaboration are important for AI groups — however restricted structured knowledge, compute sources, and centralized workflows usually stand in the best way.
Whether or not you’re a DataRobot buyer or an AI practitioner on the lookout for smarter methods to organize and mannequin giant datasets, new instruments like incremental studying, optical character recognition (OCR), and enhanced knowledge preparation will eradicate roadblocks, serving to you construct extra correct fashions in much less time.
Right here’s what’s new within the DataRobot Workbench expertise:
- Incremental studying: Effectively mannequin giant knowledge volumes with higher transparency and management.
- Optical character recognition (OCR): Immediately convert unstructured scanned PDFs into usable knowledge for predictive and generative AI take advantage of circumstances.
- Simpler collaboration: Work along with your workforce in a unified house with shared entry to knowledge prep, generative AI improvement, and predictive modeling instruments.
Mannequin effectively on giant knowledge volumes with incremental studying
Constructing fashions with giant datasets usually results in shock compute prices, inefficiencies, and runaway bills. Incremental studying removes these limitations, permitting you to mannequin on giant knowledge volumes with precision and management.
As an alternative of processing a whole dataset without delay, incremental studying runs successive iterations in your coaching knowledge, utilizing solely as a lot knowledge as wanted to realize optimum accuracy.
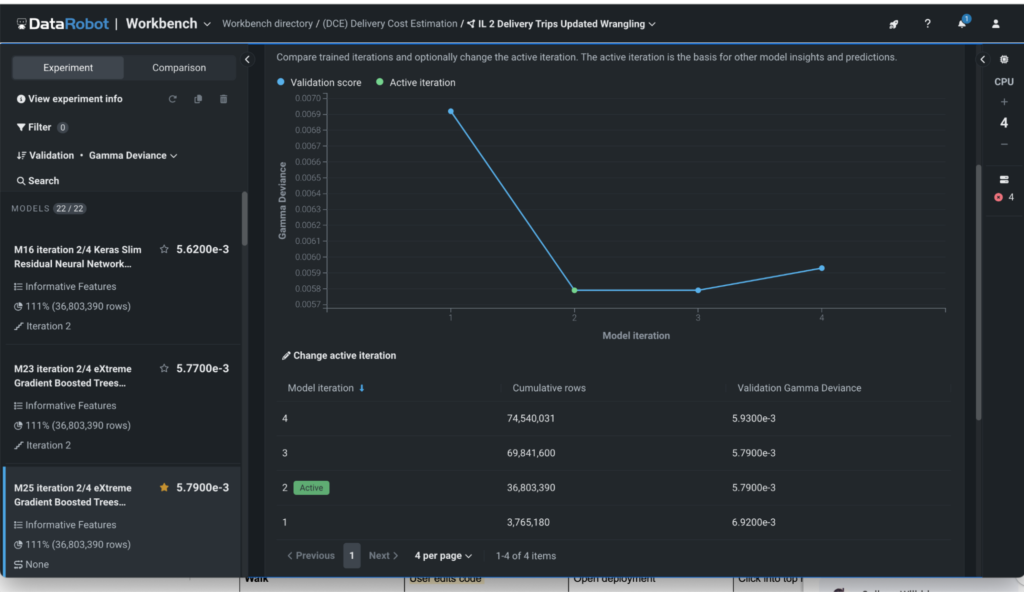
Every iteration is visualized on a graph (see Determine 1), the place you possibly can monitor the variety of rows processed and accuracy gained — all based mostly on the metric you select.
Key benefits of incremental studying:
- Solely course of the information that drives outcomes.
Incremental studying stops jobs mechanically when diminishing returns are detected, making certain you utilize simply sufficient knowledge to realize optimum accuracy. In DataRobot, every iteration is tracked, so that you’ll clearly see how a lot knowledge yields the strongest outcomes. You’re at all times in management and may customise and run extra iterations to get it excellent.
- Prepare on simply the correct quantity of information
Incremental studying prevents overfitting by iterating on smaller samples, so your mannequin learns patterns — not simply the coaching knowledge.
- Automate complicated workflows:
Guarantee this knowledge provisioning is quick and error free. Superior code-first customers can go one step additional and streamline retraining through the use of saved weights to course of solely new knowledge. This avoids the necessity to rerun the complete dataset from scratch, lowering errors from handbook setup.
When to finest leverage incremental studying
There are two key situations the place incremental studying drives effectivity and management:
- One-time modeling jobs
You’ll be able to customise early stopping on giant datasets to keep away from pointless processing, forestall overfitting, and guarantee knowledge transparency.
- Dynamic, often up to date fashions
For fashions that react to new data, superior code-first customers can construct pipelines that add new knowledge to coaching units and not using a full rerun.
Not like different AI platforms, incremental studying offers you management over giant knowledge jobs, making them sooner, extra environment friendly, and more cost effective.
How optical character recognition (OCR) prepares unstructured knowledge for AI
Accessing giant portions of usable knowledge could be a barrier to constructing correct predictive fashions and powering retrieval-augmented era (RAG) chatbots. That is very true as a result of 80-90% firm knowledge is unstructured knowledge, which may be difficult to course of. OCR removes that barrier by turning scanned PDFs right into a usable, searchable format for predictive and generative AI.
The way it works
OCR is a code-first functionality inside DataRobot. By calling the API, you possibly can rework a ZIP file of scanned PDFs right into a dataset of text-embedded PDFs. The extracted textual content is embedded immediately into the PDF doc, able to be accessed by doc AI options.

How OCR can energy multimodal AI
Our new OCR performance isn’t only for generative AI or vector databases. It additionally simplifies the preparation of AI-ready knowledge for multimodal predictive fashions, enabling richer insights from numerous knowledge sources.
Multimodal predictive AI knowledge prep
Quickly flip scanned paperwork right into a dataset of PDFs with embedded textual content. This lets you extract key data and construct options of your predictive fashions utilizing doc AI capabilities.
For instance, say you wish to predict working bills however solely have entry to scanned invoices. By combining OCR, doc textual content extraction, and an integration with Apache Airflow, you possibly can flip these invoices into a strong knowledge supply in your mannequin.
Powering RAG LLMs with vector databases
Giant vector databases help extra correct retrieval-augmented era (RAG) for LLMs, particularly when supported by bigger, richer datasets. OCR performs a key function by turning scanned PDFs into text-embedded PDFs, making that textual content usable as vectors to energy extra exact LLM responses.
Sensible use case
Think about constructing a RAG chatbot that solutions complicated worker questions. Worker advantages paperwork are sometimes dense and tough to look. Through the use of OCR to organize these paperwork for generative AI, you possibly can enrich an LLM, enabling staff to get quick, correct solutions in a self-service format.
WorkBench migrations that enhance collaboration
Collaboration may be one of many greatest blockers to quick AI supply, particularly when groups are pressured to work throughout a number of instruments and knowledge sources. DataRobot’s NextGen WorkBench solves this by unifying key predictive and generative modeling workflows in a single shared setting.
This migration means you could construct each predictive and generative fashions utilizing each graphical person interface (GUI) and code based mostly notebooks and codespaces — all in a single workspace. It additionally brings highly effective knowledge preparation capabilities into the identical setting, so groups can collaborate on end-to-end AI workflows with out switching instruments.
Speed up knowledge preparation the place you develop fashions
Knowledge preparation usually takes as much as 80% of a knowledge scientist’s time. The NextGen WorkBench streamlines this course of with:
- Knowledge high quality detection and automatic knowledge therapeutic: Determine and resolve points like lacking values, outliers, and format errors mechanically.
- Automated function detection and discount: Robotically determine key options and take away low-impact ones, lowering the necessity for handbook function engineering.
- Out-of-the-box visualizations of information evaluation: Immediately generate interactive visualizations to discover datasets and spot developments.
Enhance knowledge high quality and visualize points immediately
Knowledge high quality points like lacking values, outliers, and format errors can decelerate AI improvement. The NextGen WorkBench addresses this with automated scans and visible insights that save time and scale back handbook effort.
Now, once you add a dataset, computerized scans test for key knowledge high quality points, together with:
- Outliers
- Multicategorical format errors
- Inliers
- Extra zeros
- Disguised lacking values
- Goal leakage
- Lacking pictures (in picture datasets solely)
- PII
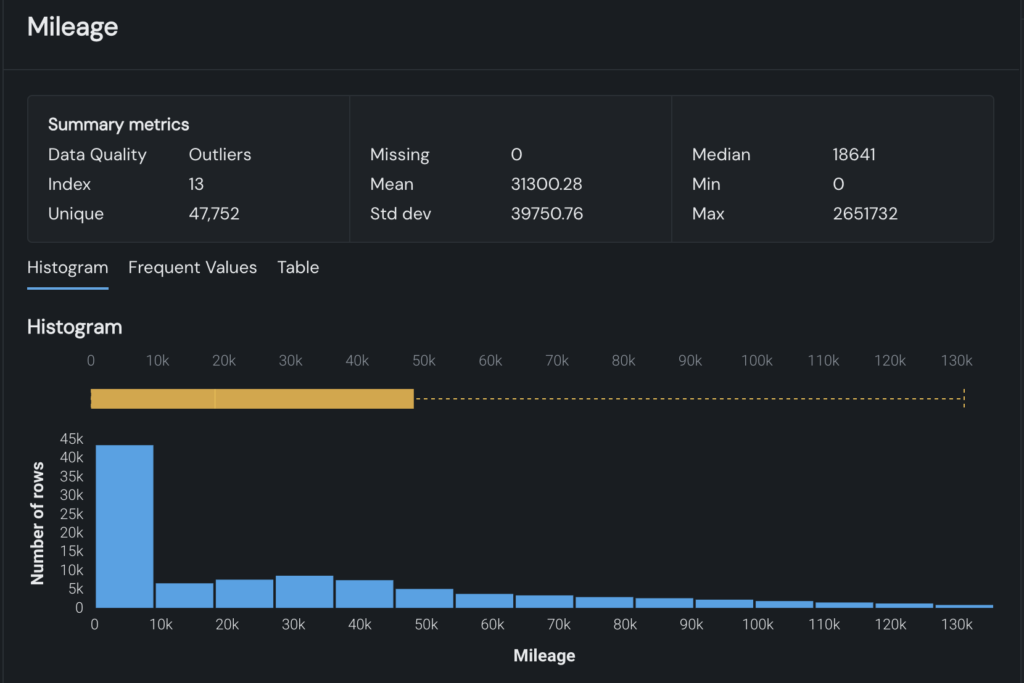
These knowledge high quality checks are paired with out-of-the-box EDA (exploratory knowledge evaluation) visualizations. New datasets are mechanically visualized in interactive graphs, supplying you with on the spot visibility into knowledge developments and potential points, with out having to construct charts your self. Determine 3 beneath demonstrates how high quality points are highlighted immediately inside the graph.
Automate function detection and scale back complexity
Automated function detection helps you simplify function engineering, making it simpler to hitch secondary datasets, detect key options, and take away low-impact ones.
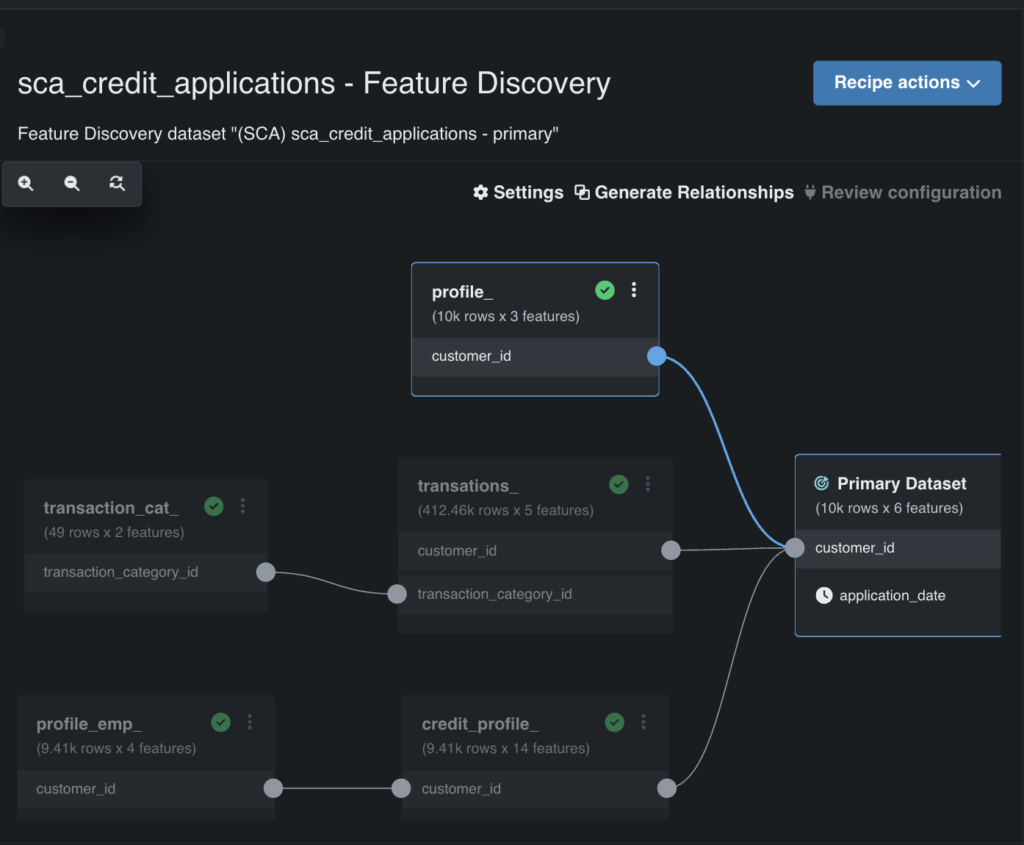
This functionality scans all of your secondary datasets to seek out similarities — like buyer IDs (see Determine 4) — and lets you mechanically be a part of them right into a coaching dataset. It additionally identifies and removes low-impact options, lowering pointless complexity.
You preserve full management, with the flexibility to evaluation and customise which options are included or excluded.
Don’t let sluggish workflows sluggish you down
Knowledge prep doesn’t should take 80% of your time. Disconnected instruments don’t should sluggish your progress. And unstructured knowledge doesn’t should be out of attain.
With NextGen WorkBench, you have got the instruments to maneuver sooner, simplify workflows, and construct with much less handbook effort. These options are already out there to you — it’s only a matter of placing them to work.
For those who’re able to see what’s attainable, discover the NextGen expertise in a free trial.
In regards to the creator


