
Introduction
The bin packing drawback is a basic optimization problem that has far-reaching implications for enterprise organizations throughout industries. At its core, the issue focuses on discovering probably the most environment friendly approach to pack a set of objects right into a finite variety of containers or “bins”, with the objective of minimizing wasted area.
This problem is pervasive in real-world functions, from optimizing delivery and logistics to effectively allocating sources in information facilities and cloud computing environments. With organizations typically coping with massive numbers of things and containers, discovering optimum packing options can result in vital value financial savings and operational efficiencies.
For a number one $10B industrial tools producer, bin packing is an integral a part of their provide chain. It’s common for this firm to ship containers to distributors to fill with bought elements which are then used within the manufacturing means of heavy tools and automobiles. With the rising complexity of provide chains and variable manufacturing targets, the packaging engineering crew wanted to make sure meeting strains have the fitting variety of elements obtainable whereas effectively utilizing area.
For instance, an meeting line wants adequate metal bolts on-hand so manufacturing by no means slows, however it’s a waste of manufacturing facility flooring area to have a delivery container filled with them when just a few dozen are wanted per day. Step one in fixing this drawback is bin packing, or modeling how hundreds of elements slot in all of the attainable containers, so engineers can then automate the method of container choice for improved productiveness.
| Problem ❗Wasted area in packaging containers ❗Extreme truck loading & carbon footprint |
Goal ✅ Decrease empty area in packaging container ✅ Maximize truck loading capability to scale back carbon footprint |
|---|---|
 |
 |
Technical Challenges
Whereas the bin packing drawback has been extensively studied in a tutorial setting, effectively simulating and fixing it throughout advanced real-world datasets and at scale has remained a problem for a lot of organizations.
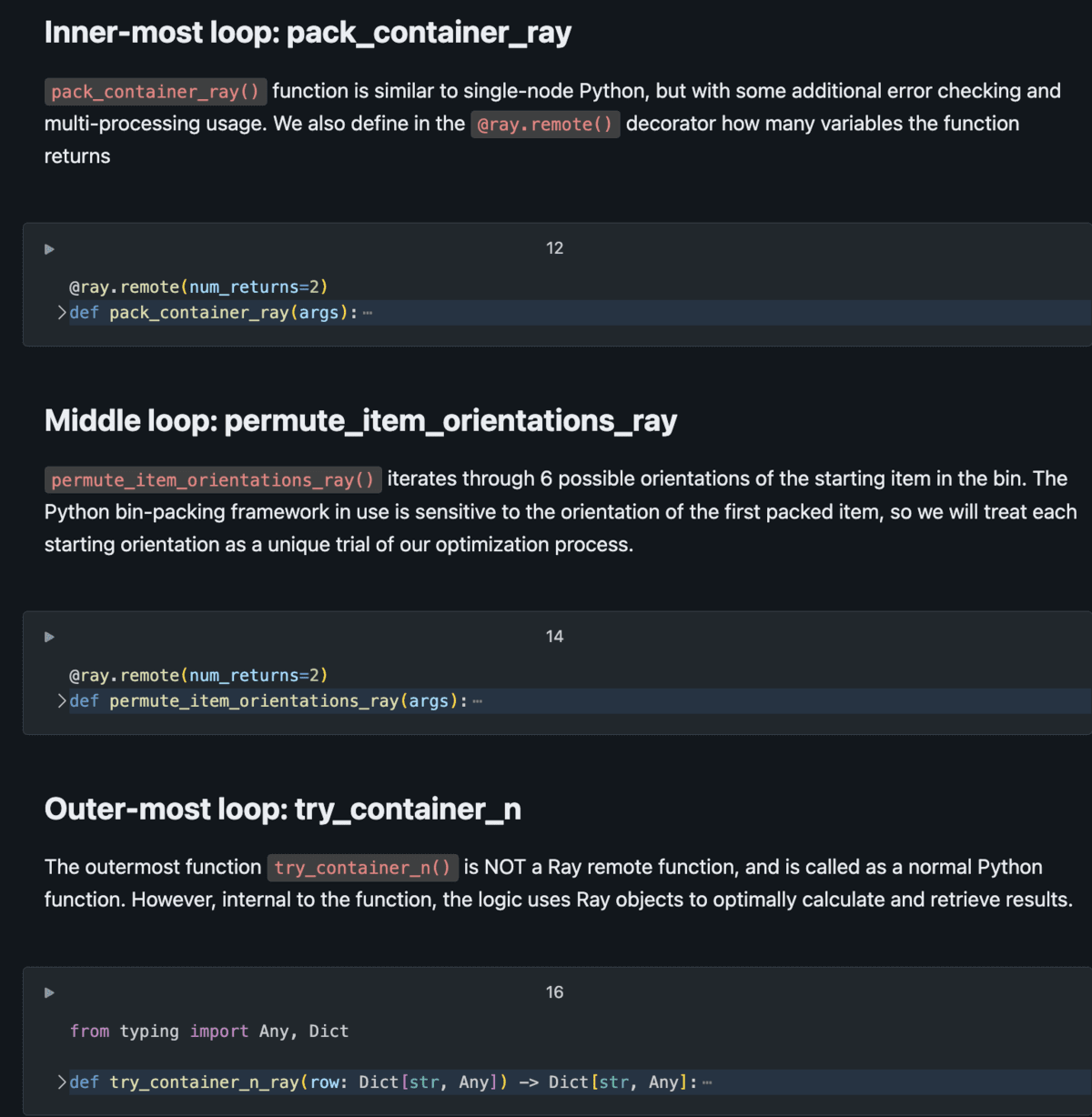
In some sense, this drawback is straightforward sufficient for anybody to know: put issues in a field till full. However as with most large information issues, challenges come up due to the sheer scale of the computations to be carried out. For this Databricks buyer’s bin packing simulation, we are able to use a easy psychological mannequin for the optimization process. Utilizing pseudocode:
For (i in objects): The method wants to run for each merchandise in stock (~1,000’s)
↳ For (c in containers): Attempt the match for each sort of container (~10’s)
↳ For (o in orientations): The beginning orientations of the first merchandise should every be modeled (==6)
↳ Pack_container Lastly, attempt filling a container with objects with a beginning orientationWhat if we had been to run this looping course of sequentially utilizing single-node Python? If we now have hundreds of thousands of iterations (e.g. 20,000 objects x 20 containers x 6 beginning orientations = 2.4M combos), this might take tons of of hours to compute (e.g. 2.4M combos x 1 second every / 3600 seconds per hour = ~660 hours = 27 days). Ready for practically a month for these outcomes, that are themselves an enter to a later modeling step, is untenable: we should provide you with a extra environment friendly approach to compute fairly than a serial/sequential course of.
Scientific Computing With Ray
As a computing platform, Databricks has all the time offered help for these scientific computing use-cases, however scaling them poses a problem: most optimization and simulation libraries are written assuming a single-node processing surroundings, and scaling them with Spark requires expertise with instruments corresponding to Pandas UDFs.
With Ray’s normal availability on Databricks in early 2024, prospects have a brand new software of their scientific computing toolbox to scale advanced optimization issues. Whereas additionally supporting superior AI capabilities like reinforcement studying and distributed ML, this weblog focuses on Ray Core to reinforce customized Python workflows that require nesting, advanced orchestration, and communication between duties.
Modeling a Bin Packing Downside
To successfully use Ray to scale scientific computing, the issue have to be logically parallelizable. That’s, when you can mannequin an issue as a sequence of concurrent simulations or trials to run, Ray may help scale it. Bin packing is a good match for this, as one can check totally different objects in several containers in several orientations all on the similar time. With Ray, this bin packing drawback may be modeled as a set of nested distant capabilities, permitting hundreds of concurrent trials to run concurrently, with the diploma of parallelism restricted by the variety of cores in a cluster.
The diagram beneath demonstrates the essential setup of this modeling drawback.

The Python script consists of nested duties, the place outer duties name the internal duties a number of occasions per iteration. Utilizing distant duties (as a substitute of regular Python capabilities), we now have the power to massively distribute these duties throughout the cluster with Ray Core managing the execution graph and returning outcomes effectively. See the Databricks Answer Accelerator scientific-computing-ray-on-spark for full implementation particulars.
Efficiency & Outcomes
With the strategies described on this weblog and demonstrated within the related Github repo, this buyer was in a position to:
- Scale back container choice time: The adoption of the 3D bin packing algorithm marks a big development, providing an answer that isn’t solely extra correct but in addition significantly quicker, lowering the time required for container choice by an element of 40x as in comparison with legacy processes.
- Scale the method linearly: with Ray, the time to complete the modeling course of may be linearly scaled with the variety of cores in our cluster. Taking the instance with 2.4 million combos from the highest (that may have taken 660 hours to finish on a single thread): if we wish the method to run in a single day in 12 hours, we want: 2.4M / (12hr x 3600sec) = 56 cores; to finish in 3 hours, we would want 220 cores. On Databricks, that is simply managed through a cluster configuration.
- Considerably cut back code complexity: Ray streamlines code complexity, providing a extra intuitive various to the unique optimization process constructed with Python’s multiprocessing and threading libraries. The earlier implementation required intricate information of those libraries resulting from nested logic constructions. In distinction, Ray’s strategy simplifies the codebase, making it extra accessible to information crew members. The ensuing code is just not solely simpler to grasp but in addition aligns extra intently with idiomatic Python practices, enhancing general maintainability and effectivity.
Extensibility for Scientific Computing
The mix of automation, batch processing, and optimized container choice has led to measurable enhancements for this industrial producer, together with a big discount in delivery and packaging prices, and a dramatic enhance in course of effectivity. With the bin packing drawback dealt with, information crew members are shifting on to different domains of scientific computing for his or her enterprise, together with optimization and linear-programming targeted challenges. The capabilities offered by the Databricks Lakehouse platform provide a chance to not solely mannequin new enterprise issues for the primary time, but in addition dramatically enhance legacy scientific computing strategies which were in use for years.
In tandem with Spark, the de facto commonplace for information parallel duties, Ray may help make any “logic-parallel” drawback extra environment friendly. Modeling processes which are purely depending on the quantity of compute obtainable are a robust software for companies to create data-driven companies.
See the Databricks Answer Accelerator scientific-computing-ray-on-spark.

