

The flexibility of LLMs to execute instructions via plain language (e.g. English) has enabled agentic methods that may full a person question by orchestrating the best set of instruments (e.g. ToolFormer, Gorilla). This, together with the current multi-modal efforts such because the GPT-4o or Gemini-1.5 mannequin, has expanded the realm of prospects with AI brokers. Whereas that is fairly thrilling, the big mannequin measurement and computational necessities of those fashions typically requires their inference to be carried out on the cloud. This could create a number of challenges for his or her widespread adoption. Initially, importing knowledge comparable to video, audio, or textual content paperwork to a 3rd social gathering vendor on the cloud, can lead to privateness points. Second, this requires cloud/Wi-Fi connectivity which isn’t at all times attainable. As an illustration, a robotic deployed in the true world could not at all times have a steady connection. Moreover that, latency is also a problem as importing massive quantities of information to the cloud and ready for the response may decelerate response time, leading to unacceptable time-to-solution. These challenges might be solved if we deploy the LLM fashions domestically on the edge.
Nevertheless, present LLMs like GPT-4o or Gemini-1.5 are too massive for native deployment. One contributing issue is that a variety of the mannequin measurement finally ends up memorizing basic details about the world into its parametric reminiscence which is probably not crucial for a specialised downstream utility. As an illustration, should you ask a basic factual query from these fashions like a historic occasion or well-known figures, they will produce the outcomes utilizing their parametric reminiscence, even with out having further context of their immediate. Nevertheless, it looks as if this implicit memorization of coaching knowledge into the parametric reminiscence is correlated with “emergent” phenomena in LLMs comparable to in-context studying and sophisticated reasoning, which has been the driving power behind scaling the mannequin measurement.
Nevertheless, this results in an intriguing analysis query:
Can a smaller language mannequin with considerably much less parametric reminiscence emulate such emergent skill of those bigger language fashions?
Attaining this could considerably cut back the computational footprint of agentic methods and thus allow environment friendly and privacy-preserving edge deployment. Our research demonstrates that that is possible for small language fashions via coaching with specialised, high-quality knowledge that doesn’t require recalling generic world information.
Such a system may significantly be helpful for semantic methods the place the AI agent’s function is to know the person question in pure language and, as a substitute of responding with a ChatGPT-type query reply response, orchestrate the best set of instruments and APIs to perform the person’s command. For instance, in a Siri-like utility, a person could ask a language mannequin to create a calendar invite with specific attendees. If a predefined script for creating calendar objects already exists, the LLM merely must learn to invoke this script with the proper enter arguments (comparable to attendees’ e-mail addresses, occasion title, and time). This course of doesn’t require recalling/memorization of world information from sources like Wikipedia, however somewhat requires reasoning and studying to name the best features and to appropriately orchestrate them.
Our aim is to develop Small Language Fashions (SLM) which can be able to complicated reasoning that might be deployed securely and privately on the edge. Right here we are going to talk about the analysis instructions that we’re pursuing to that finish. First, we talk about how we are able to allow small open-source fashions to carry out correct perform calling, which is a key element of agentic methods. It seems that off-the-shelf small fashions have very low perform calling capabilities. We talk about how we tackle this by systematically curating high-quality knowledge for perform calling, utilizing a specialised Mac assistant agent as our driving utility. We then present that fine-tuning the mannequin on this prime quality curated dataset, can allow SLMs to even exceed GPT-4-Turbo’s perform calling efficiency. We then present that this might be additional improved and made environment friendly via a brand new Software RAG methodology. Lastly, we present how the ultimate fashions might be deployed effectively on the edge with actual time responses.
Demo of TinyAgent-1B together with Whisper-v3 working domestically deployed domestically on a Macbook M3 Professional. The framework is open sourced and accessible at https://github.com/SqueezeAILab/TinyAgent
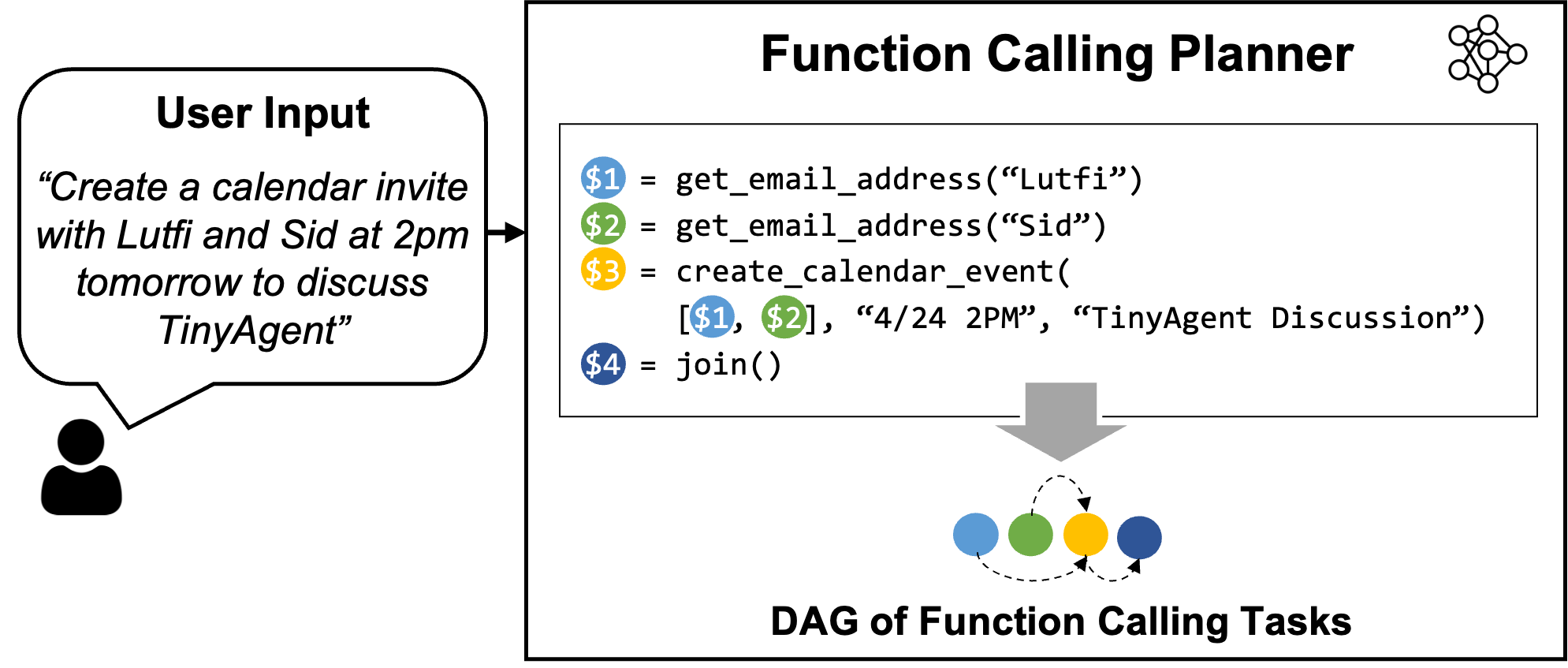
Determine 1: Overview of the LLMCompiler Perform Calling Planner. The Planner understands the person question and generates a sequence of duties with their inter-dependencies. These duties are then dispatched by the LLMCompiler framework to perform the person command. On this instance, Job $1 and $2 are fetched collectively to retrieve the e-mail addresses of Sid and Lutfi independently. After every activity is carried out, the outcomes are forwarded to Job $3 which creates the calendar occasion. Earlier than executing Job $3, LLMCompiler replaces the placeholder variables (e.g., the variable $1 and $2 in Job $3) with precise values.
As talked about above, our principal curiosity is purposes the place the AI agent interprets the person question right into a sequence of perform calls to finish the duties. In such purposes, the mannequin doesn’t want to put in writing the perform definition itself because the features (or APIs) are principally pre-defined and already accessible. Subsequently, what the mannequin must do is to find out (i) which features to name, (ii) the corresponding enter arguments, and (iii) the best order of calling these features (i.e. perform orchestration) primarily based on the required interdependency throughout the perform calls.
The primary query is to seek out an efficient method to equip SLMs to carry out perform calling. Giant fashions comparable to GPT-4 are in a position to carry out perform calling, however how can this be achieved with open supply fashions? LLMCompiler is a current framework from our group that permits this by instructing the LLM to output a perform calling plan that features the set of features that it must name together with the enter arguments and their dependencies (see the instance in Determine 1). As soon as this perform calling plan is generated, we are able to parse it and name every perform primarily based on the dependencies.
The essential half right here is to show the mannequin to create this perform calling plan with the best syntax and dependency. The unique LLMCompiler paper solely thought of massive fashions, comparable to LLaMA-2 70B, which have complicated reasoning capabilities to create the plan when supplied with enough directions of their prompts. Nevertheless, can smaller fashions be prompted the identical method to output the proper perform calling plan? Sadly, our experiments confirmed that off-the-shelf small fashions comparable to TinyLLaMA-1.1B (and even the bigger Wizard-2-7B mannequin) usually are not in a position to output the proper plans. The errors ranged from issues comparable to utilizing the mistaken set of features, hallucinated names, mistaken dependencies, inconsistent syntax, and so forth.
That is somewhat anticipated as a result of these small fashions have been educated on generic datasets and primarily focused to attain good accuracy on basic benchmarks which principally take a look at the mannequin’s world information and basic reasoning or primary instruction following functionality. To deal with this, we explored if fine-tuning these fashions on a high-quality dataset specifically curated for perform calling and planning can enhance the accuracy of those small language fashions for a focused activity, doubtlessly outperforming bigger fashions. Subsequent, we first talk about how we generated such a dataset, after which talk about the high quality tuning method.
Determine 2: TinyAgent is an assistant that may work together with varied MacOS purposes to help the person. The instructions may be given to it via both textual content via a highlight enter, or via voice.
As a driving utility, we contemplate an area agentic system for Apple’s Macbook that solves person’s day-to-day duties, as proven in Determine 2. Significantly, the agent is provided with 16 totally different features that may work together with totally different purposes on Mac, which incorporates:
- Electronic mail: Compose a brand new e-mail or reply to/ahead emails
- Contacts: Retrieve cellphone numbers or e-mail addresses from the contacts database
- SMS: Ship textual content messages to contact(s)
- Calendar: Create calendar occasions with particulars comparable to title, time, attendees, and so forth.
- Notes: Create, open, or append content material to notes in varied folders
- Reminder: Set reminders for varied actions and duties
- File administration: Open, learn, or summarize paperwork in varied file paths
- Zoom conferences: Schedule and set up Zoom conferences
Predefined Apple scripts exist for every of those features/instruments, and all that the mannequin must do is to benefit from the predefined APIs and decide the best perform calling plan to perform a given activity, comparable to in Determine 1. However as mentioned beforehand, we want some knowledge for evaluating and coaching small language fashions since their off-the-shelf perform calling functionality is subpar.
Creating handcrafted knowledge with numerous perform calling plans is each difficult and never scalable. Nevertheless, we are able to curate artificial knowledge utilizing an LLM like GPT-4-Turbo. Such an method is changing into a typical methodology the place a succesful LLM is instructed to generate knowledge much like a given set of pattern examples or templates (see LLM2LLM and Self-Instruct). In our work, we used the same method, however as a substitute of offering the LLM with generic person queries as templates, we offer it with varied units of features and instruct it to generate life like person queries that require these features to perform the duty, together with the related perform calling plan and enter arguments, like the instance proven in Determine 1. To confirm the validity of the generated knowledge, we included sanity checks on the perform calling plan to ensure that they kind a possible graph, and that the perform names and enter argument sorts are right. With this method, we created 80K coaching knowledge, 1K validation knowledge, and 1K testing knowledge, with a complete value of solely ~$500.
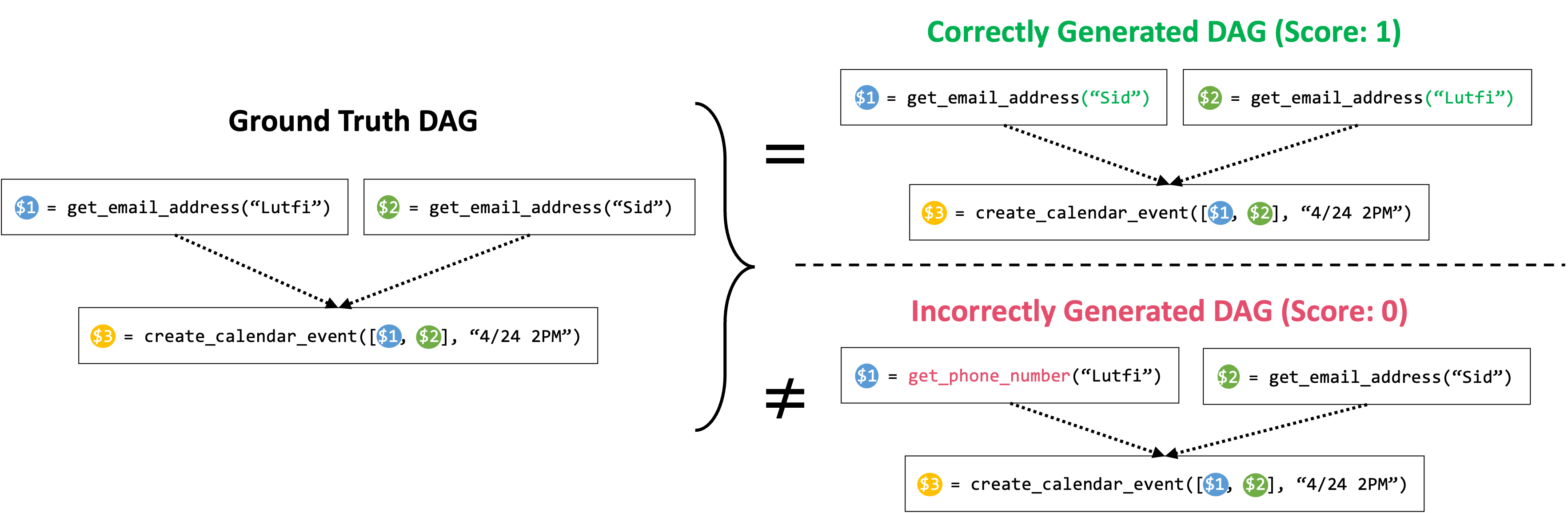
Determine 3: Graph Isomorphism Success Fee. The mannequin scores a hit price of 1 provided that the DAG of its generated plan is isomorphic to the DAG of the bottom fact plan; and 0 in any other case. In above instance, for the highest case, though the order of the get_email_address calls are totally different from the bottom fact plan (the bottom fact plan will get the e-mail tackle of Lutfi earlier than Sid, and the generated plan will get the e-mail tackle of Sid earlier than Lutfi), because the two DAGs are isomorphic to one another, the plan will get 1 success price. For the underside case, because the predicted DAG accommodates a mistaken node, similar to a mistaken perform name, the plan will get 0 success price.
With our dataset in place, we are able to now proceed to fine-tune off-the-shelf SLMs to boost their perform calling functionality. We began with two base small fashions: TinyLlama-1.1B (instruct-32k model) and Wizard-2-7B. For fine-tuning these fashions, we first have to outline a metric to guage their efficiency. Our goal is for these fashions to precisely generate the best plan, which includes not solely deciding on the best set of features, but in addition appropriately orchestrating them in the best order. Subsequently, we outline a hit price metric that assigns 1 if each standards are met, and 0 in any other case. Checking whether or not the mannequin has chosen the best set perform calls is simple. To moreover be certain that the orchestration of those features is right, we assemble a Directed Acyclic Graph (DAG) of the perform calls primarily based on the dependencies, as proven in Determine 3, the place every node represents a perform name and a directed edge from node A to B represents their interdependency (i.e. perform B can solely be executed after the execution of perform A). Then we evaluate if this DAG is equivalent to that of the bottom fact plan to confirm the accuracy of the dependencies.
After defining our analysis metric, we utilized LoRA to fine-tune the fashions for 3 epochs utilizing a studying price of 7e-5 over the 80K coaching examples, and chosen the most effective checkpoint primarily based on validation efficiency. For fine-tuning, our immediate included not solely the descriptions of the bottom fact features (i.e. features used within the floor fact plan) but in addition different irrelevant features as detrimental samples. We discovered the detrimental samples to be significantly efficient for instructing the mannequin easy methods to choose acceptable instruments for a given question, therefore bettering the post-training efficiency. Moreover, we additionally embody a number of in-context examples demonstrating how queries are translated right into a perform calling plans. These in-context examples are chosen via a Retrieval Augmented Era (RAG) course of primarily based on the person question from the info within the coaching dataset.
Utilizing the above settings, we fine-tuned TinyLlama-1.1B/Wizard-2-7B fashions. After fine-tuning, the 1.1B mannequin improved the success price from 12.71% to 78.89%, and the 7B mannequin efficiency improved from 41.25% to 83.09%, which is ~4% increased than GPT-4-Turbo.
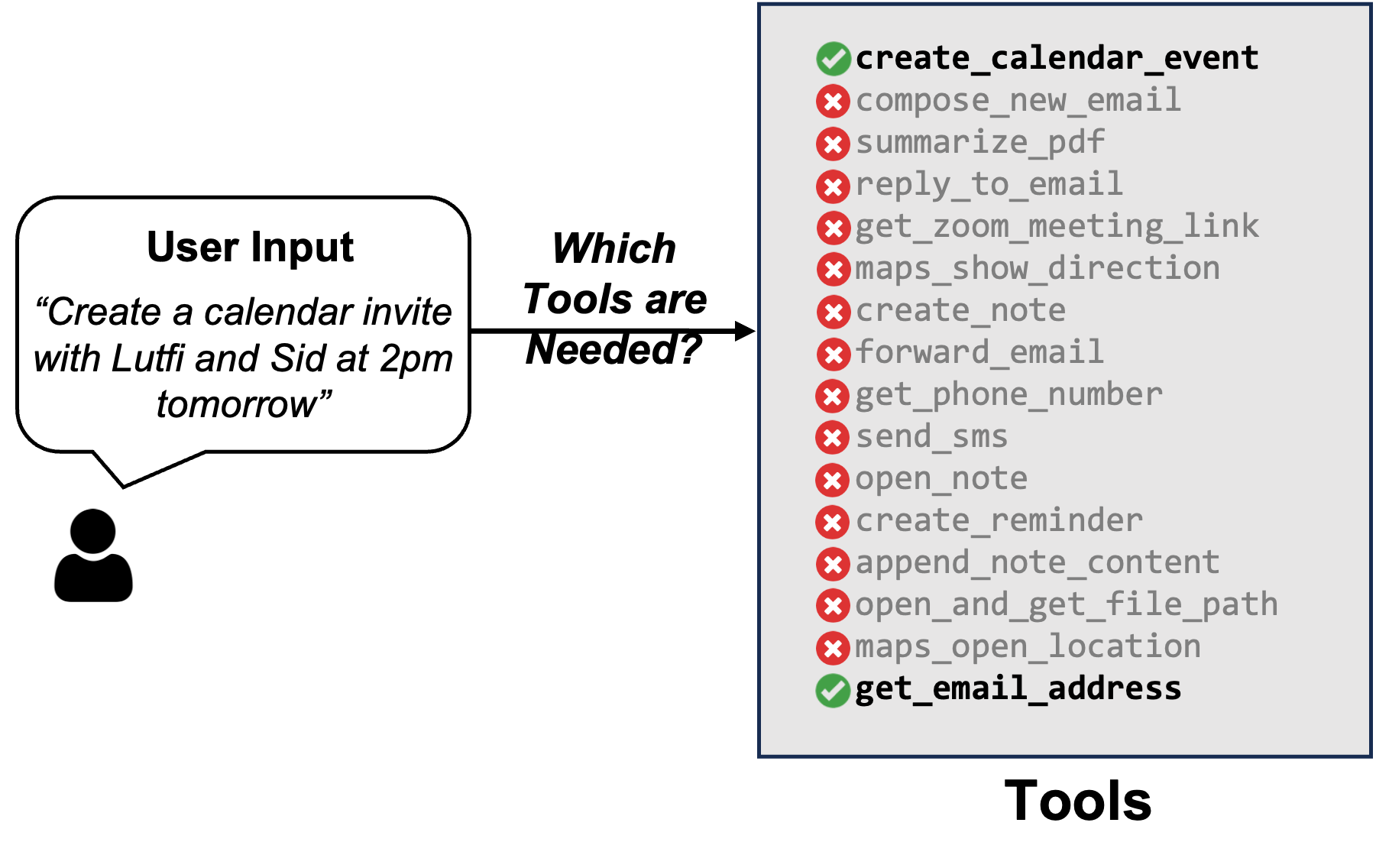
Determine 4: Environment friendly Software Choice Primarily based on Consumer Enter. Not all person inputs require all accessible instruments; therefore, it’s crucial to pick out the best set of instruments to reduce the immediate measurement and improve efficiency. On this case, the LLM solely wants the features that get e-mail addresses and create a calendar occasion in its immediate to perform its activity.
Our main aim is to have the ability to deploy the TinyAgent mannequin domestically on a Macbook, which has restricted computational and reminiscence assets accessible as in comparison with the GPUs that closed-source fashions like GPT are deployed on. To realize environment friendly efficiency with low latency we have to be certain that not solely the mannequin measurement is small, however that the enter immediate is as concise as attainable. The latter is a crucial contributor to latency and computational useful resource consumption as a result of quadratic complexity of consideration on sequence size.
The fine-tuned TinyAgent mannequin mentioned beforehand was fine-tuned with the outline of all accessible instruments in its immediate. Nevertheless, that is fairly inefficient. We will considerably cut back the immediate measurement by solely together with the outline of related instruments primarily based on the person question. As an illustration, contemplate the instance proven in Determine 4 above, the place the person is asking to create a calendar invite with two individuals. On this case, the LLM solely wants the features that get e-mail addresses and create a calendar occasion in its immediate.
To benefit from this commentary, we have to decide which features are required to perform the person’s command, which we consult with as Software RAG given its similarity with how Retrieval Augmented Era (RAG) works. Nevertheless, there is a crucial subtlety. If we use a primary RAG methodology the place we compute the embedding of the person question and use that to retrieve the related instruments, we get very low efficiency. It’s because finishing a person’s question typically requires utilizing a number of auxiliary instruments which can be missed with a easy RAG methodology if the embedding of the auxiliary device isn’t much like the person question. As an illustration, the instance proven in Determine 4 requires calling get_email_address perform regardless that the person question is simply asking about making a calendar invitation.
This may be addressed by treating the issue as a classification of which instruments are wanted. To that finish, we fine-tuned a DeBERTa-v3-small mannequin on the coaching knowledge to carry out a 16-way classification as proven in Determine 5. The person question is given as an enter to this mannequin, after which we move the CLS token on the finish via a easy absolutely linked layer of measurement 768×16 to remodel it right into a 16 dimensional vector (which is the whole measurement of our instruments). The output of this layer is handed via a sigmoid layer to supply the likelihood of choosing every device. Throughout inference, we choose the instruments which have most likely increased than 50%, and in that case, we embody their description within the immediate. On common we observed that solely 3.97 instruments are retrieved with a recall of 0.998, whereas the essential RAG requires utilizing the highest 6 instruments to attain a device recall of 0.968.
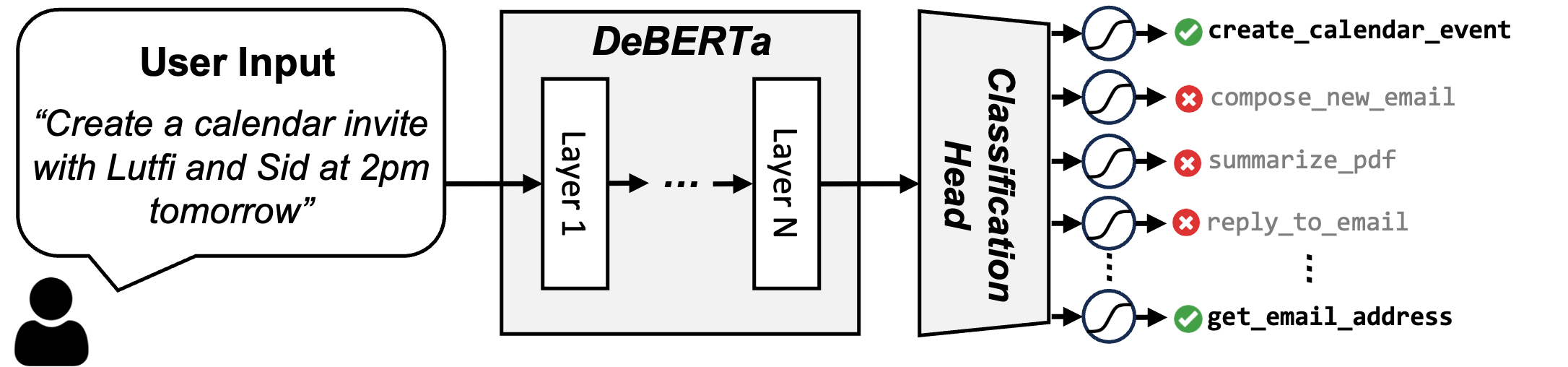
Determine 5: Overview of our Software RAG scheme. We formulate device retrieval as a multi-label classification downside. The person question is given as enter to the fine-tuned DeBERTa-v3-small mannequin, which outputs a 16-dimensional vector indicating device chances. Instruments with chances increased than 50% are chosen, averaging 3.97 instruments per question in comparison with 6 instruments in primary RAG.
We evaluated the mannequin efficiency after incorporating Software RAG. The outcomes are proven in Desk 1 under, the place we report the efficiency of the straightforward RAG system together with the fine-tuned DeBERTa method. As one can see, the DeBERTa primarily based Software RAG methodology achieves virtually good recall efficiency, improves the baseline accuracy, whereas decreasing the immediate measurement by ~2x tokens.
Desk 1: Comparability of TinyAgent efficiency with DeBERTa to Fundamental RAG and no RAG settings.
| Software RAG Technique | Software Recall | Immediate Dimension (Tokens) | TinyAgent 1.1B Success Fee (%) | TinyAgent 7B Success Fee (%) |
|---|---|---|---|---|
| No RAG (all instruments within the immediate) | 1 | 2762 | 78.89 | 83.09 |
| Fundamental RAG | 0.949 (prime 3) | 1674 | 74.88 | 78.50 |
| Tremendous-tuned DeBERTa-v3-small (Ours) | 0.998 (instruments with >50% prob) | 1397 | 80.06 | 84.95 |
Deploying fashions on the edge, comparable to on shopper MacBooks, can nonetheless be difficult even for small fashions of O(1B) parameters, since loading the mannequin parameters can eat a big portion of the accessible reminiscence. An answer to those points is quantization, which permits us to retailer the mannequin at a lowered bit precision. Quantization not solely reduces the storage necessities and mannequin footprint, but in addition cuts down the time and assets wanted to load mannequin weights into reminiscence, thereby decreasing the general inference latency as properly (see this for extra data on quantization).
For extra environment friendly deployment of the fashions, we quantized the fashions into 4-bit with a gaggle measurement of 32, which is supported by the llama.cpp framework with quantization conscious coaching. As proven in Desk 2, the 4-bit fashions lead to 30% higher latency, together with a 4x discount within the mannequin measurement. We additionally discover slight accuracy enchancment which is as a result of further fine-tuning with simulated quantization.
Desk 2: Latency, measurement, and success price of TinyAgent fashions earlier than and after quantization. Latency is the end-to-end latency of the perform calling planner, together with the immediate processing time and era.
| Mannequin | Weight Precision | Latency (seconds) | Mannequin Dimension (GB) | Success Fee (%) |
|---|---|---|---|---|
| GPT-3.5 | Unknown | 3.2 | Unknown | 65.04 |
| GPT-4-Turbo | Unknown | 3.9 | Unknown | 79.08 |
| TinyAgent-1.1B | 16 | 3.9 | 2.2 | 80.06 |
| TinyAgent-1.1B | 4 | 2.9 | 0.68 | 80.35 |
| TinyAgent-7B | 16 | 19.5 | 14.5 | 84.95 |
| TinyAgent-7B | 4 | 13.1 | 4.37 | 85.14 |
Under is the demo of the ultimate TinyAgent-1.1B mannequin deployed on a Macbook Professional M3 which you’ll truly obtain and set up in your Mac and take a look at as properly. It not solely runs all the mannequin inference domestically in your laptop, however it additionally means that you can present instructions via audio. We course of the audio domestically as properly utilizing the Whisper-v3 mannequin from OpenAI deployed domestically utilizing the whisper.cpp framework. The best shock for us was that the accuracy of the 1.1B mannequin exceeds that of GPT-4-Turbo, and is markedly quick whereas deployed domestically and privately on gadget.
To summarize, we launched TinyAgent and confirmed that it’s certainly attainable to coach a small language mannequin and use it to energy a semantic system that processes person queries. Particularly, we thought of a Siri-like assistant for Mac as a driving utility. The important thing elements for enabling it’s to (i) educate off-the-shelf SLMs to carry out perform calling via LLMCompiler framework, (ii) curate prime quality perform calling knowledge for the duty at hand, (iii) fine-tune the off-the-shelf mannequin on the generated knowledge, and (iv) allow environment friendly deployment by optimizing the immediate measurement via solely retrieving the required instruments primarily based on the person question via a technique known as ToolRAG, in addition to quantized mannequin deployment to scale back inference useful resource consumption. After these steps, our ultimate fashions achieved 80.06% and 84.95% for the TinyAgent1.1.B and 7B fashions which exceed GPT-4-Turbo’s success price of 79.08% on this activity.
We want to thank Apple for sponsoring this challenge, in addition to assist from Microsoft via Accelerating Basis Fashions Analysis Program. We additionally thank Sunjin Choi for his insights in vitality value related to native and cloud deployment. Our conclusions don’t essentially mirror the place or the coverage of our sponsors, and no official endorsement ought to be inferred.
BibTex for this publish:
@misc{tiny-agent,
title={TinyAgent: Perform Calling on the Edge},
creator={Erdogan, Lutfi Eren and Lee, Nicholas and Jha, Siddharth and Kim, Sehoon and Tabrizi, Ryan and Moon, Suhong and Hooper, Coleman and Anumanchipalli, Gopala and Keutzer, Kurt and Gholami, Amir},
howpublished={url{https://bair.berkeley.edu/weblog/2024/05/29/tiny-agent/}},
yr={2024}
}

