

Cloudflare has confirmed that the huge service outage yesterday was not attributable to a safety incident and no knowledge has been misplaced.
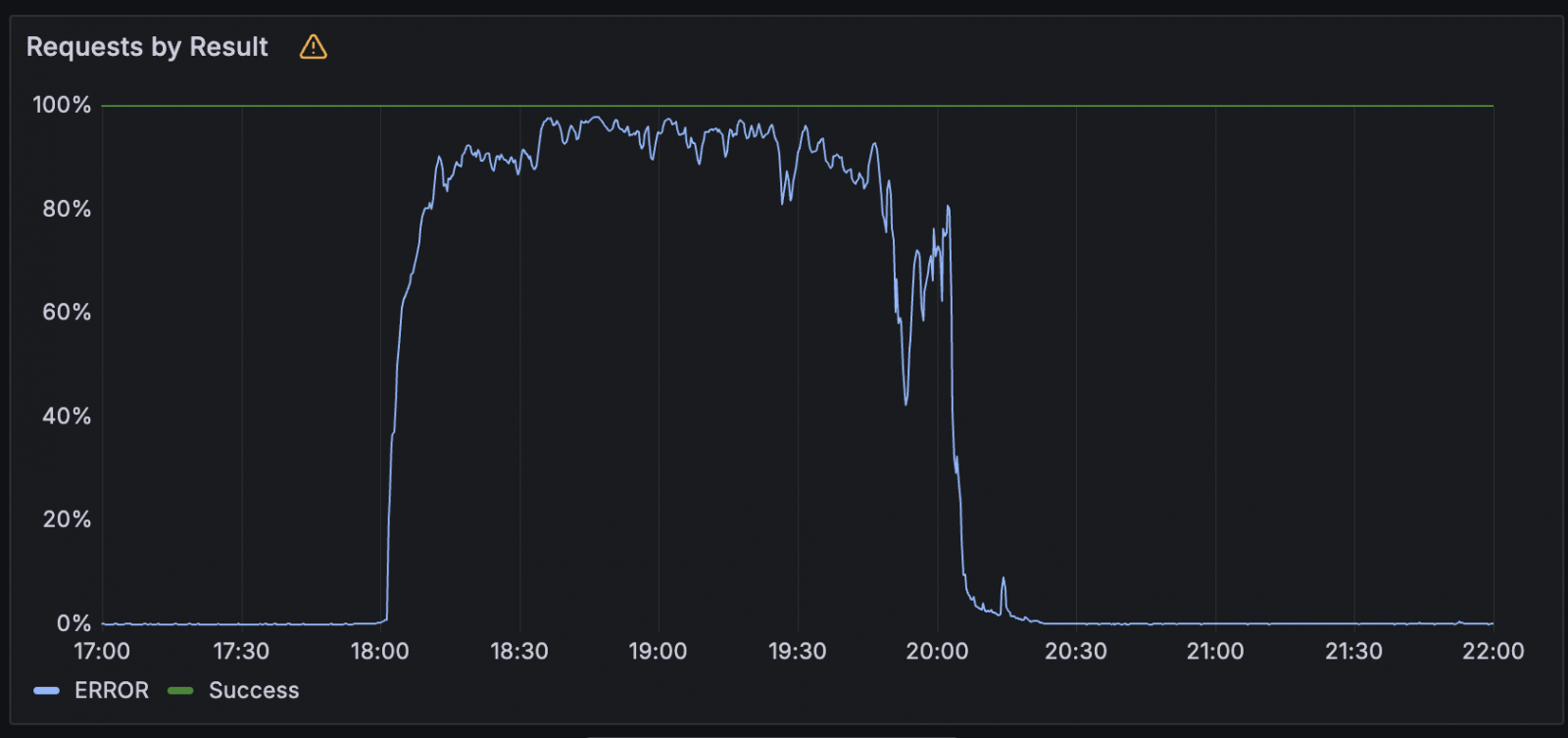
The difficulty has been largely mitigated. It began 17:52 UTC yesterday when the Employees KV (Key-Worth) system went utterly offline, inflicting widespread service losses throughout a number of edge computing and AI providers.
Employees KV is a globally distributed, constant key-value retailer utilized by Cloudflare Employees, the corporate’s serverless computing platform. It’s a elementary piece in lots of Cloudflare providers and a failure could cause cascading points throughout many elements.
The disruption additionally impacted different providers utilized by hundreds of thousands, most notably the Google Cloud Platform.
Supply: Cloudflare
In a put up mortem, Cloudflare explains that the outage lasted virtually 2.5 hours and the basis trigger was a failure within the Employees KV underlying storage infrastructure as a result of a third-party cloud supplier outage.
“The reason for this outage was as a result of a failure within the underlying storage infrastructure utilized by our Employees KV service, which is a vital dependency for a lot of Cloudflare merchandise and relied upon for configuration, authentication, and asset supply throughout the affected providers,” Cloudflare says.
“A part of this infrastructure is backed by a third-party cloud supplier, which skilled an outage in the present day and instantly impacted the supply of our KV service.”
Cloudflare has decided the impression of the incident on every service:
- Employees KV – skilled a 90.22% failure price as a result of backend storage unavailability, affecting all uncached reads and writes.
- Entry, WARP, Gateway – all suffered vital failures in identity-based authentication, session dealing with, and coverage enforcement as a result of reliance on Employees KV, with WARP unable to register new units, and disruption of Gateway proxying and DoH queries.
- Dashboard, Turnstile, Challenges – skilled widespread login and CAPTCHA verification failures, with token reuse danger launched as a result of kill change activation on Turnstile.
- Browser Isolation & Browser Rendering – didn’t provoke or preserve link-based classes and browser rendering duties as a result of cascading failures in Entry and Gateway.
- Stream, Photographs, Pages – skilled main practical breakdowns: Stream playback and reside streaming failed, picture uploads dropped to 0% success, and Pages builds/serving peaked at ~100% failure.
- Employees AI & AutoRAG – had been utterly unavailable as a result of dependence on KV for mannequin configuration, routing, and indexing capabilities.
- Sturdy Objects, D1, Queues – providers constructed on the identical storage layer as KV suffered as much as 22% error charges or full unavailability for message queuing and knowledge operations.
- Realtime & AI Gateway – confronted near-total service disruption as a result of incapacity to retrieve configuration from Employees KV, with Realtime TURN/SFU and AI Gateway requests closely impacted.
- Zaraz & Employees Property – noticed full or partial failure in loading or updating configurations and static belongings, although end-user impression was restricted in scope.
- CDN, Employees for Platforms, Employees Builds – skilled elevated latency and regional errors in some areas, with new Employees builds failing 100% throughout the incident.
In response to this outage, Cloudflare says will probably be accelerating a number of resilience-focused modifications, primarily eliminating reliance on a single third-party cloud supplier for Employees KV backend storage.
Step by step, the KV’s central retailer will likely be migrated to Cloudflare’s personal R2 object storage to cut back exterior dependency.
Cloudflare additionally plans to implement cross-service safeguards and develop new tooling to regularly restore providers throughout storage outages, stopping visitors surges that would overwhelm recovering programs and trigger secondary failures.

Patching used to imply complicated scripts, lengthy hours, and limitless hearth drills. Not anymore.
On this new information, Tines breaks down how fashionable IT orgs are leveling up with automation. Patch quicker, cut back overhead, and deal with strategic work — no complicated scripts required.

