
Increase your expertise with Development Memo’s weekly skilled insights. Subscribe free of charge!
Perplexity’s technique behind its new Pages function created a deep rift with publishers, however the response appears blown out of proportion. It’s way more fascinating as a case research for user-directed AI content material (UDC as a substitute of UGC).
Perplexity Pages permits customers to “create fantastically designed, complete articles on any matter.” You possibly can flip a thread, a immediate sequence, right into a web page a few matter.
As an everyday Development Memo reader, you shortly grasp that it is a progress technique the place, ideally, customers create AI content material that ranks in natural search and brings guests to perplexity.ai that converts into paying subscribers.
The expansion technique matches into what CEO Srinivas explains as “an aggregator of data.” It holds energy by offering a superior consumer expertise, which permits it to channel demand and commoditize provide.
Drop In The Bucket
Once we take a look at precise information, we will see that the media response is overblown. Not within the critique however in influence. It’s honest to ask Perplexity to regulate attribution, observe net requirements like robots.txt, and use official IPs like search engines like google do as properly.
In accordance with developer Ryan Knight, Perplexity crawls the online with a headless browser that masks its IP string.
CEO Srinivas mentioned Perplexity obeys robots.txt, and the masked IP got here from a third-party service. However he additionally talked about that “the emergence of AI requires a brand new sort of working relationship between content material creators, or publishers, and websites like his.”
However by way of profit for Perplexity, Pages is a drop within the bucket.
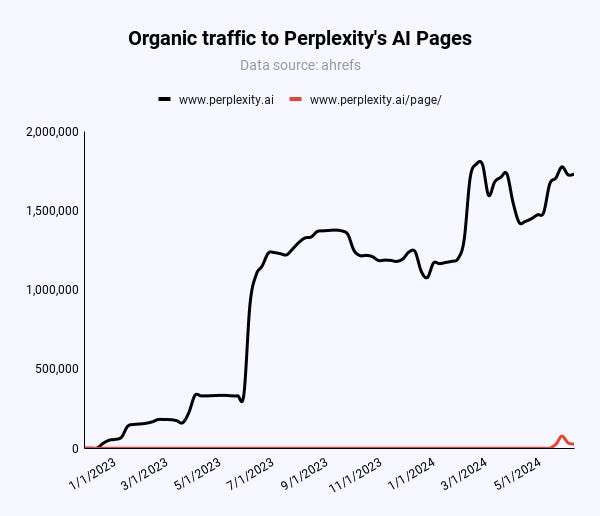 Picture Credit score: Kevin Indig
Picture Credit score: Kevin Indig91% of natural visitors to perplexity.ai comes from branded phrases like “perplexity.”
Solely 47,000 out of 217,000 (21.6%) month-to-month guests to Pages come from natural, non-branded key phrases globally.
Within the US, it’s 55% (20,000/36,000). Nonetheless, in comparison with x month-to-month visits from branded phrases, Pages doesn’t make a dent in Perplexity’s natural visitors.
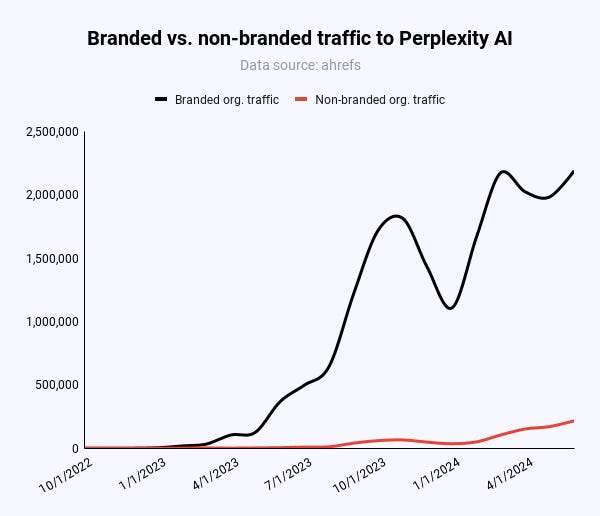 Picture Credit score: Kevin Indig
Picture Credit score: Kevin IndigIn actuality, most visitors to Perplexity comes by means of its model and phrase of mouth. The current media protection may need helped Perplexity greater than it harmed. The positioning has hit new all-time visitors highs day by day since January 2024, based on Similarweb.
Perplexity’s complete area has solely 950 pages, of which Pages make up nearly 600. In comparison with different websites – like Wikipedia’s 6.8 million articles on the English model alone – that’s simply not so much. Stronger scale results will emerge as Pages get extra traction. Proper now, Pages is a nascent beta function.
Taking a more in-depth take a look at its efficiency, essentially the most searched-for key phrase Pages rank within the high 3 for is “was sweet montgomery responsible” (600 MSV). Essentially the most tough key phrase it ranks in place one for is “when was the primary bitcoin buy” (KD: 76, MSV: 30). In different phrases, Pages nonetheless has a protracted approach to go.
An n=1 (!) textual content similarity comparability with GoTranscript between Perplexity’s web page for “bitcoin pizza day” and its 4 linked sources exhibits little proof of plagiarism:
- nationaltoday.com/bitcoin-pizza-day/ (15% similarity).
- www.uledger.io/submit/bitcoin-pizza-day-history (27% similarity).
- coinedition.com/bitcoin-pizza-day-a-700-million-reminder-of-cryptocurrencys-rise/ (15%).
- www.investopedia.com/information/bitcoin-pizza-day-celebrating-20-million-pizza-order/ (9%).
 Textual content comparability between Perplexity’s and NationalToday’s article about Bitcoin Pizza Day (Picture Credit score: Kevin Indig)
Textual content comparability between Perplexity’s and NationalToday’s article about Bitcoin Pizza Day (Picture Credit score: Kevin Indig)The “lacking” attribution concern appears to have been fastened, as the instance under exhibits.
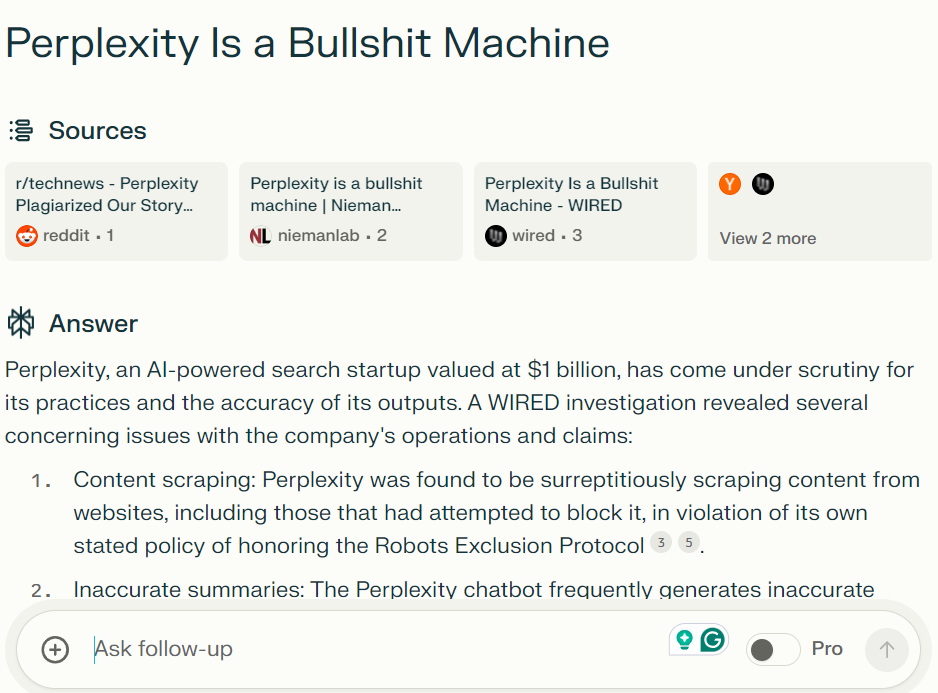 Perplexity highlights sources for solutions on the high (Picture Credit score: Kevin Indig)
Perplexity highlights sources for solutions on the high (Picture Credit score: Kevin Indig)The outcomes confirmed the chatbot at instances intently paraphrasing WIRED tales, and at instances summarizing tales inaccurately and with minimal attribution.
I wasn’t capable of affirm or deny circumstances of hallucination, however I anticipate higher fashions to get to a degree at which they will summarize current content material flawlessly. The fact is, we’re not there but. Google’s AI Overviews have additionally been proven to incorporate improper information or make issues up.
Google appears to have been capable of enhance the issue shortly, which is why I anticipate the diploma of hallucination to drop.
One underlying concern of the plagiarism critique is {that a} seek for the precise title of an article returns that article.
After all, Perplexity ought to return a abstract of an article when customers immediate it. What else ought to Perplexity present? The identical argument got here up within the lawsuit between OpenAI and the NY Occasions.
Triggered
In addition to the crawling points Perplexity wants to repair, the media’s response appears to be triggered by Perplexity’s positioning.
One sentence in Perplexity’s announcement of Pages will get to the guts of the underlying concern:
“With Pages, you don’t should be an skilled author to create top quality content material.”
The web page additionally mentions:
”Crafting content material that resonates may be tough. Pages is constructed for readability, breaking down advanced topics into digestible items and serving everybody from educators to executives.”
All examples of Pages listed within the announcement are about “the best way to” or “what’s” subjects:
- “Newbie’s information to drumming”
- “How one can use an AeroPress”
- “Writing Kubernetes CronJobs”
- “Steve Jobs: Visionary CEO”
- And so on.
That’s precisely the problem AI poses to writers: AI can more and more cowl clearly outlined content material codecs like guides or tutorials. I can see how that is triggering to journalists.
Person-Directed Content material
Observe how Perplexity doesn’t create all of the content material for Pages however takes route from people by means of prompts (UDC).
As an alternative of writing a complete article, people put the puzzle items collectively and their creator bio stamp on a Web page.
I anticipate the identical to occur with different content material sorts like evaluations and platforms like Google, Tripadvisor, Yelp, G2 & Co. to offer corresponding instruments to make content material creation simpler. The largest problem will likely be to maintain high quality excessive and cut back ineffective info to a minimal.
The large query is whether or not a construct like Pages can compete with a purely human-written website like Wikipedia, which at the moment has 116,000 energetic contributors.
The larger “Development play” behind pages (IMHO) is how Perplexity creates AI (video) podcasts out of summarized articles that outrank unique outcomes.
“Perplexity then despatched this knockoff story to its subscribers through a cell push notification. It created an AI-generated podcast utilizing the identical (Forbes) reporting — with none credit score to Forbes, and that turned a YouTube video that outranks all Forbes content material on this matter inside Google search.”
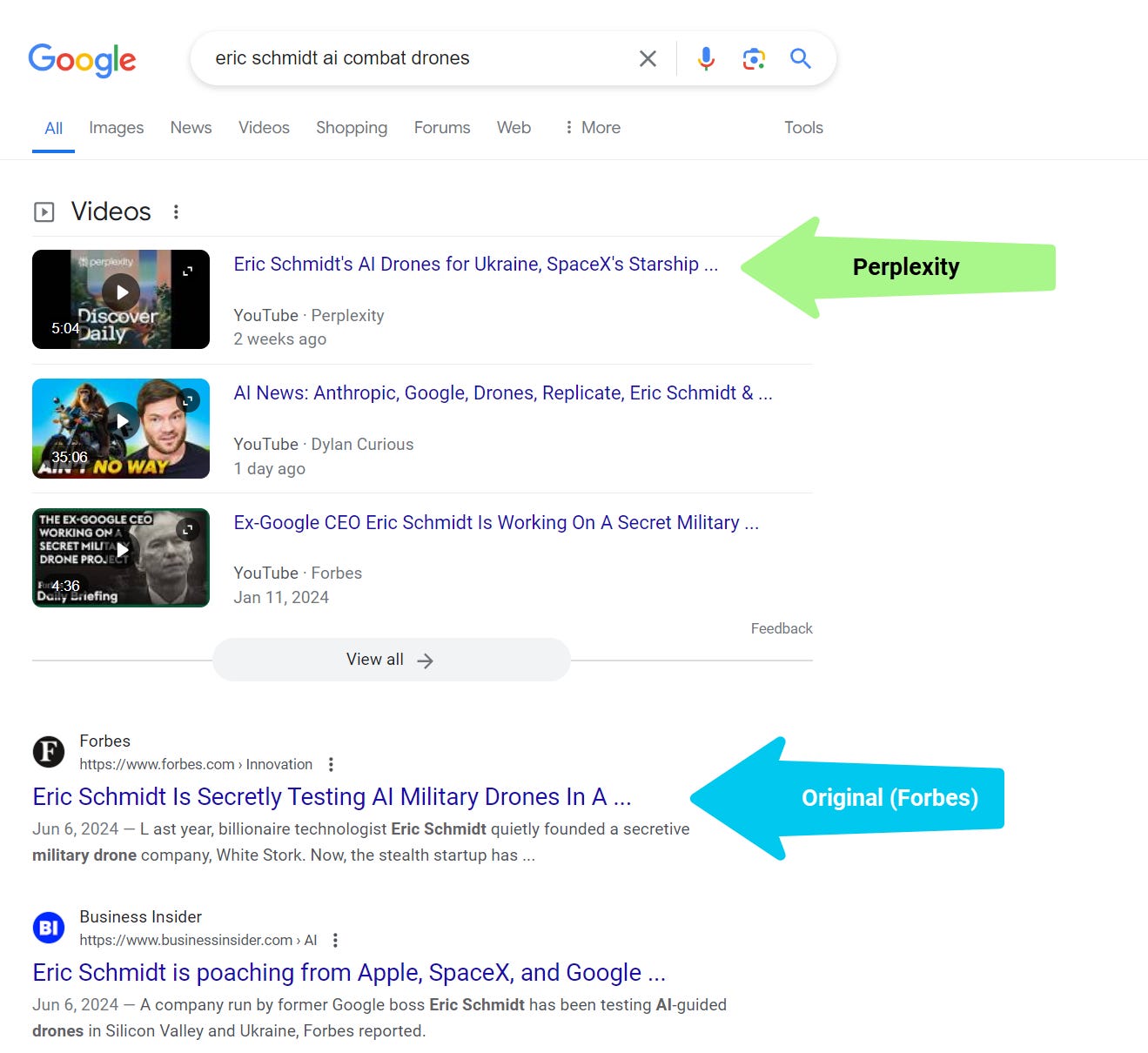 Perplexity outranks publishers with video podcasts summarizing articles (Picture Credit score: Kevin Indig)
Perplexity outranks publishers with video podcasts summarizing articles (Picture Credit score: Kevin Indig)Google must work out the best way to forestall LLMs from repurposing the content material of publishers.
What stays after inspecting the information is the conclusion of how tough it’s to stability giving an AI reply whereas sending visitors to sources. Why ought to customers click on when most of their questions are answered?
On the opposite aspect of the coin, publishers themselves can present summaries of their articles. Subsequently, the important thing problem for Perplexity – and anybody else who desires to create large-scale AI content material for Search – is including distinctive worth on high of AI summaries.
The trail to distinctive worth from AI summaries and different AI content material is personalization.
A system that may acknowledge your preferences of stage of understanding for a subject could make AI summaries extra helpful to you. Perplexity is a wrapper round completely different LLMs, but when it collects important details about customers and personalizes output, it may well add worth past quick solutions.
Gadget working system makers like Alphabet and Apple have the largest benefit in relation to consumer information since they sit on high of the meals chain.
A robust instance is Apple Intelligence, which may possible reply questions at the moment supplied by guides and tutorials on Google or Perplexity.
Apple Intelligence (abbreviated “AI” – good one, Apple!) has full context by means of location (Apple Maps), third-party app utilization, Siri prompts, e mail (Apple Mail), and different sources, which creates a pleasant base to personalize outcomes on. The online is only one physique of data, with a a lot sexier one ready on our Dropbox, Gmail inbox, and iPhone images.
Right now, customized solutions are a imaginative and prescient and a demo.
However in some unspecified time in the future sooner or later, personalization will create higher solutions than any generic LLM abstract and certainly greater than any human-written information.
The worth of outlined and generic data is on a collision course with LLM bombers. On the identical time, the worth of customized data, human expertise, and reliable skilled experience is skyrocketing.
AI startup Perplexity desires to upend search enterprise. Information outlet Forbes says it’s ripping them off; Integrator vs Aggregator Development
Perplexity AI Is Mendacity about Their Person Agent
Perplexity CEO Aravind Srinivas responds to plagiarism and infringement accusations
Why Perplexity’s Cynical Theft Represents The whole lot That Might Go Flawed With AI
Featured Picture: Paulo Bobita/Search Engine Journal
")
