
This weblog breaks down the accessible pricing and deployment choices, and instruments that help scalable, cost-conscious AI deployments.
While you’re constructing with AI, each determination counts—particularly in terms of price. Whether or not you’re simply getting began or scaling enterprise-grade purposes, the very last thing you need is unpredictable pricing or inflexible infrastructure slowing you down. Azure OpenAI is designed with that in thoughts: versatile sufficient for early experiments, highly effective sufficient for international deployments, and priced to match the way you truly use it.
From startups to the Fortune 500, greater than 60,000 clients are selecting Azure AI Foundry, not only for entry to foundational and reasoning fashions—however as a result of it meets them the place they’re, with deployment choices and pricing fashions that align to actual enterprise wants. That is about extra than simply AI—it’s about making innovation sustainable, scalable, and accessible.
This weblog breaks down the accessible pricing and deployment choices, and instruments that help scalable, cost-conscious AI deployments.
Versatile pricing fashions that match your wants
Azure OpenAI helps three distinct pricing fashions designed to fulfill totally different workload profiles and enterprise necessities:
- Normal—For bursty or variable workloads the place you need to pay just for what you utilize.
- Provisioned—For prime-throughput, performance-sensitive purposes that require constant throughput.
- Batch—For big-scale jobs that may be processed asynchronously at a reduced charge.
Every method is designed to scale with you—whether or not you’re validating a use case or deploying throughout enterprise items.

Normal
The Normal deployment mannequin is good for groups that need flexibility. You’re charged per API name primarily based on tokens consumed, which helps optimize budgets in periods of decrease utilization.
Finest for: Improvement, prototyping, or manufacturing workloads with variable demand.
You’ll be able to select between:
- International deployments: To make sure optimum latency throughout geographies.
- OpenAI Information Zones: For extra flexibility and management over knowledge privateness and residency.
With all deployment alternatives, knowledge is saved at relaxation throughout the Azure chosen area of your useful resource.
Batch
- The Batch mannequin is designed for high-efficiency, large-scale inference. Jobs are submitted and processed asynchronously, with responses returned inside 24 hours—at as much as 50% lower than International Normal pricing. Batch additionally options massive scale workload help to course of bulk requests with decrease prices. Scale your large batch queries with minimal friction and effectively deal with large-scale workloads to cut back processing time, with 24-hour goal turnaround, at as much as 50% much less price than international normal.
Finest for: Massive-volume duties with versatile latency wants.
Typical use instances embrace:
- Massive-scale knowledge processing and content material technology.
- Information transformation pipelines.
- Mannequin analysis throughout intensive datasets.
Buyer in motion: Ontada
Ontada, a McKesson firm, used the Batch API to remodel over 150 million oncology paperwork into structured insights. Making use of LLMs throughout 39 most cancers varieties, they unlocked 70% of beforehand inaccessible knowledge and lower doc processing time by 75%. Be taught extra within the Ontada case research.
Provisioned
The Provisioned mannequin offers devoted throughput through Provisioned Throughput Items (PTUs). This permits secure latency and excessive throughput—perfect for manufacturing use instances requiring real-time efficiency or processing at scale. Commitments may be hourly, month-to-month, or yearly with corresponding reductions.
Finest for: Enterprise workloads with predictable demand and the necessity for constant efficiency.
Widespread use instances:
- Excessive-volume retrieval and doc processing eventualities.
- Name heart operations with predictable visitors hours.
- Retail assistant with persistently excessive throughput.
Prospects in motion: Visier and UBS
- Visier constructed “Vee,” a generative AI assistant that serves as much as 150,000 customers per hour. By utilizing PTUs, Visier improved response occasions by 3 times in comparison with pay-as-you-go fashions and lowered compute prices at scale. Learn the case research.
- UBS created ‘UBS Pink’, a safe AI platform supporting 30,000 workers throughout areas. PTUs allowed the financial institution to ship dependable efficiency with region-specific deployments throughout Switzerland, Hong Kong, and Singapore. Learn the case research.
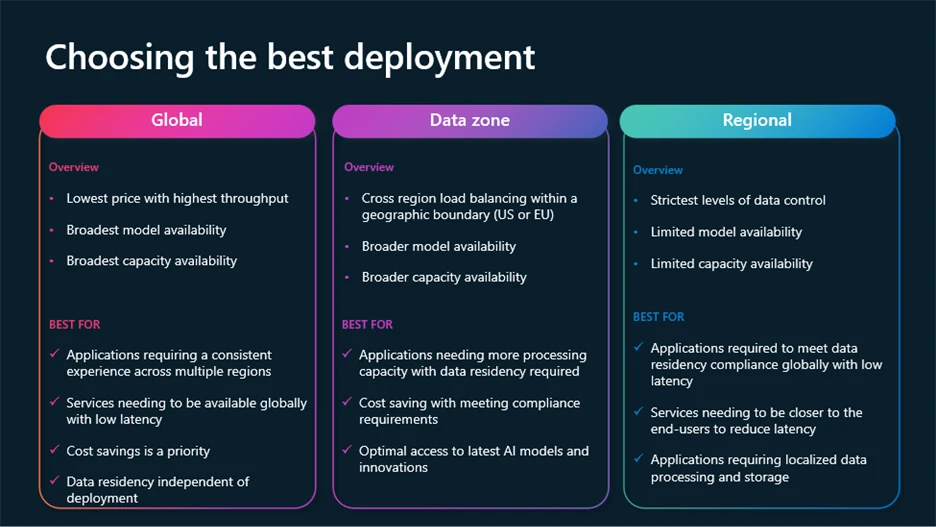
Deployment varieties for normal and provisioned
To fulfill rising necessities for management, compliance, and price optimization, Azure OpenAI helps a number of deployment varieties:
- International: Most cost-effective, routes requests via the worldwide Azure infrastructure, with knowledge residency at relaxation.
- Regional: Retains knowledge processing in a particular Azure area (28 accessible right now), with knowledge residency each at relaxation and processing within the chosen area.
- Information Zones: Gives a center floor—processing stays inside geographic zones (E.U. or U.S.) for added compliance with out full regional price overhead.
International and Information Zone deployments can be found throughout Normal, Provisioned, and Batch fashions.
Dynamic options assist you to lower prices whereas optimizing efficiency
A number of dynamic new options designed that can assist you get the very best outcomes for decrease prices at the moment are accessible.
- Mannequin router for Azure AI Foundry: A deployable AI chat mannequin that robotically selects the very best underlying chat mannequin to answer a given immediate. Excellent for various use instances, mannequin router delivers excessive efficiency whereas saving on compute prices the place attainable, all packaged as a single mannequin deployment.
- Batch massive scale workload help: Processes bulk requests with decrease prices. Effectively deal with large-scale workloads to cut back processing time, with 24-hour goal turnaround, at 50% much less price than international normal.
- Provisioned throughput dynamic spillover: Offers seamless overflowing in your high-performing purposes on provisioned deployments. Handle visitors bursts with out service disruption.
- Immediate caching: Constructed-in optimization for repeatable immediate patterns. It accelerates response occasions, scales throughput, and helps lower token prices considerably.
- Azure OpenAI monitoring dashboard: Constantly monitor efficiency, utilization, and reliability throughout your deployments.
To study extra about these options and how you can leverage the newest improvements in Azure AI Foundry fashions, watch this session from Construct 2025 on optimizing Gen AI purposes at scale.
Past pricing and deployment flexibility, Azure OpenAI integrates with Microsoft Price Administration instruments to offer groups visibility and management over their AI spend.
Capabilities embrace:
- Actual-time price evaluation.
- Finances creation and alerts.
- Help for multi-cloud environments.
- Price allocation and chargeback by group, challenge, or division.
These instruments assist finance and engineering groups keep aligned—making it simpler to grasp utilization tendencies, monitor optimizations, and keep away from surprises.
Constructed-in integration with the Azure ecosystem
Azure OpenAI is a component of a bigger ecosystem that features:
This integration simplifies the end-to-end lifecycle of constructing, customizing, and managing AI options. You don’t should sew collectively separate platforms—and meaning quicker time-to-value and fewer operational complications.
A trusted basis for enterprise AI
Microsoft is dedicated to enabling AI that’s safe, personal, and protected. That dedication exhibits up not simply in coverage, however in product:
- Safe future initiative: A complete security-by-design method.
- Accountable AI ideas: Utilized throughout instruments, documentation, and deployment workflows.
- Enterprise-grade compliance: Overlaying knowledge residency, entry controls, and auditing.
Get began with Azure AI Foundry

