
Introduction
During the last couple of years, developments in Synthetic Intelligence (AI) have pushed an exponential enhance within the demand for GPU assets and electrical vitality, resulting in a worldwide shortage of high-performance GPUs, reminiscent of NVIDIA’s flagship chipsets. This shortage has created a aggressive and expensive panorama. Organizations with the monetary capability to construct their very own AI infrastructure pay substantial premiums to keep up operations, whereas others depend on renting GPU assets from cloud suppliers, which comes with equally prohibitive and escalating prices. These infrastructures typically function beneath a “one-size-fits-all” mannequin, wherein organizations are compelled to pay for AI-supporting assets that stay underutilized throughout prolonged intervals of low demand, leading to pointless expenditures.
The monetary and logistical challenges of sustaining such infrastructure are higher illustrated by examples like OpenAI, which, regardless of having roughly 10 million paying subscribers for its ChatGPT service, reportedly incurs vital day by day losses as a result of overwhelming operational bills attributed to the tens of 1000’s of GPUs and vitality used to help AI operations. This raises important issues in regards to the long-term sustainability of AI, significantly as demand and prices for GPUs and vitality proceed to rise.
Such prices might be considerably decreased by creating efficient mechanisms that may dynamically uncover and allocate GPUs in a semi-decentralized style that caters to the particular necessities of particular person AI operations. Fashionable GPU allocation options should adapt to the various nature of AI workloads and supply custom-made useful resource provisioning to keep away from pointless idle states. Additionally they want to include environment friendly mechanisms for figuring out optimum GPU assets, particularly when assets are constrained. This may be difficult as GPU allocation techniques should accommodate the altering computational wants, priorities, and constraints of various AI duties and implement light-weight and environment friendly strategies to allow fast and efficient useful resource allocation with out resorting to exhaustive searches.
On this paper, we suggest a self-adaptive GPU allocation framework that dynamically manages the computational wants of AI workloads of various property / techniques by combining a decentralized agent-based public sale mechanism (e.g. English and Posted-offer auctions) with supervised studying strategies reminiscent of Random Forest.
The public sale mechanism addresses the dimensions and complexity of GPU allocation whereas balancing trade-offs between competing useful resource requests in a distributed and environment friendly method. The selection of public sale mechanism might be tailor-made based mostly on the working atmosphere in addition to the variety of suppliers and customers (bidders) to make sure effectiveness. To additional optimize the method, blockchain expertise is included into the public sale mechanism. Utilizing blockchain ensures safe, clear, and decentralized useful resource allocation and a broader attain for GPU assets. Peer-to-peer blockchain tasks (e.g., Render, Akash, Spheron, Gpu.internet) that make the most of idle GPU assets exist already and are broadly used.
In the meantime, the supervised studying element, particularly the Random Forest classification algorithm, allows proactive and automatic decision-making by detecting runtime anomalies and optimizing useful resource allocation methods based mostly on historic information. By leveraging the Random Forest classifier, our framework identifies environment friendly allocation plans knowledgeable by previous efficiency, avoiding exhaustive searches and enabling tailor-made GPU provisioning for AI workloads.
The Use of Market within the GPU Allocation Framework
Companies and GPU assets can adapt to the altering computational wants of AI workloads in dynamic and shared environments. AI duties might be optimized by choosing acceptable GPU assets that greatest meet their evolving necessities and constraints. The connection between GPU assets and AI companies is important (Determine 1), because it captures not solely the computational overhead imposed by AI duties but additionally the effectivity and scalability of the options they supply. A unified mannequin might be utilized: every AI workload aim (e.g., coaching giant language fashions) might be damaged down into sub-goals, reminiscent of lowering latency, optimizing vitality effectivity, or making certain excessive throughput. These sub-goals can then be matched with GPU assets best suited to help the general AI goal.

Given the multi-tenant and shared nature of Cloud-based and blockchain enabled AI infrastructure, together with the excessive demand in GPUs, any allocation resolution have to be designed with scalable structure. Market-inspired methodologies current a promising resolution to this downside, providing an efficient optimization mechanism for repeatedly satisfying the various computational necessities of a number of AI duties. These market-based options empower each customers and suppliers to independently make choices that maximize their use, whereas regulating the provision and demand of GPU assets, reaching equilibrium. In situations with restricted GPU availability, public sale mechanisms can facilitate efficient allocation by prioritizing useful resource requests based mostly on urgency (mirrored in bidding costs), making certain that high-priority AI duties obtain the required assets.
Market fashions together with blockchain additionally carry transparency to the allocation course of by establishing systematic procedures for buying and selling and mapping GPU assets to AI workloads and sub-goals. Lastly, the adoption of market rules might be seamlessly built-in by AI service suppliers, working both on Cloud or blockchain, lowering the necessity for structural adjustments and minimizing the danger of disruptions to AI workflows.
Framework Overview (Utilizing an Instance)
Given our experience in cybersecurity, we discover a GPU allocation situation for a forensic AI system designed to help incident response throughout a cyberattack. “Firm Z” (fictitious), a multinational monetary companies agency working in 20 international locations, manages a distributed IT infrastructure with extremely delicate information, making it a chief goal for risk actors. To boost its safety posture, Firm Z deploys a forensic AI system that leverages GPU acceleration to quickly analyze and reply to incidents.
This AI-driven system consists of autonomous brokers embedded throughout the corporate’s infrastructure, repeatedly monitoring runtime safety necessities by way of specialised sensors. When a cyber incident happens, these brokers dynamically regulate safety operations, leveraging GPUs and different computational assets to course of threats in actual time. Nevertheless, outdoors of emergencies, the AI system primarily capabilities in a coaching and reinforcement studying capability, making a devoted AI infrastructure each expensive and inefficient. As an alternative, Firm Z adopts an on-demand GPU allocation mannequin, making certain high-performance, AI-driven, forensic evaluation whereas minimizing pointless useful resource waste. For the needs of this instance, we function beneath the next assumptions:
Incident Overview
Firm Z is beneath a ransomware assault affecting its inside databases and consumer information. The assault disrupts regular operations and threatens to leak and encrypt delicate information. The forensic AI system wants to research the assault in actual time, establish its root-cause, assess its affect, and advocate mitigation steps. The forensic AI system requires GPUs for computationally intensive duties, together with the evaluation of assault patterns in varied log information, evaluation of encrypted information and help with steering on restoration actions. The AI system depends on cloud-based and peer-to-peer blockchain GPU assets suppliers, which supply high-performance GPU situations for duties reminiscent of deep studying model-based inference, information mining, and anomaly detection (Determine 2).
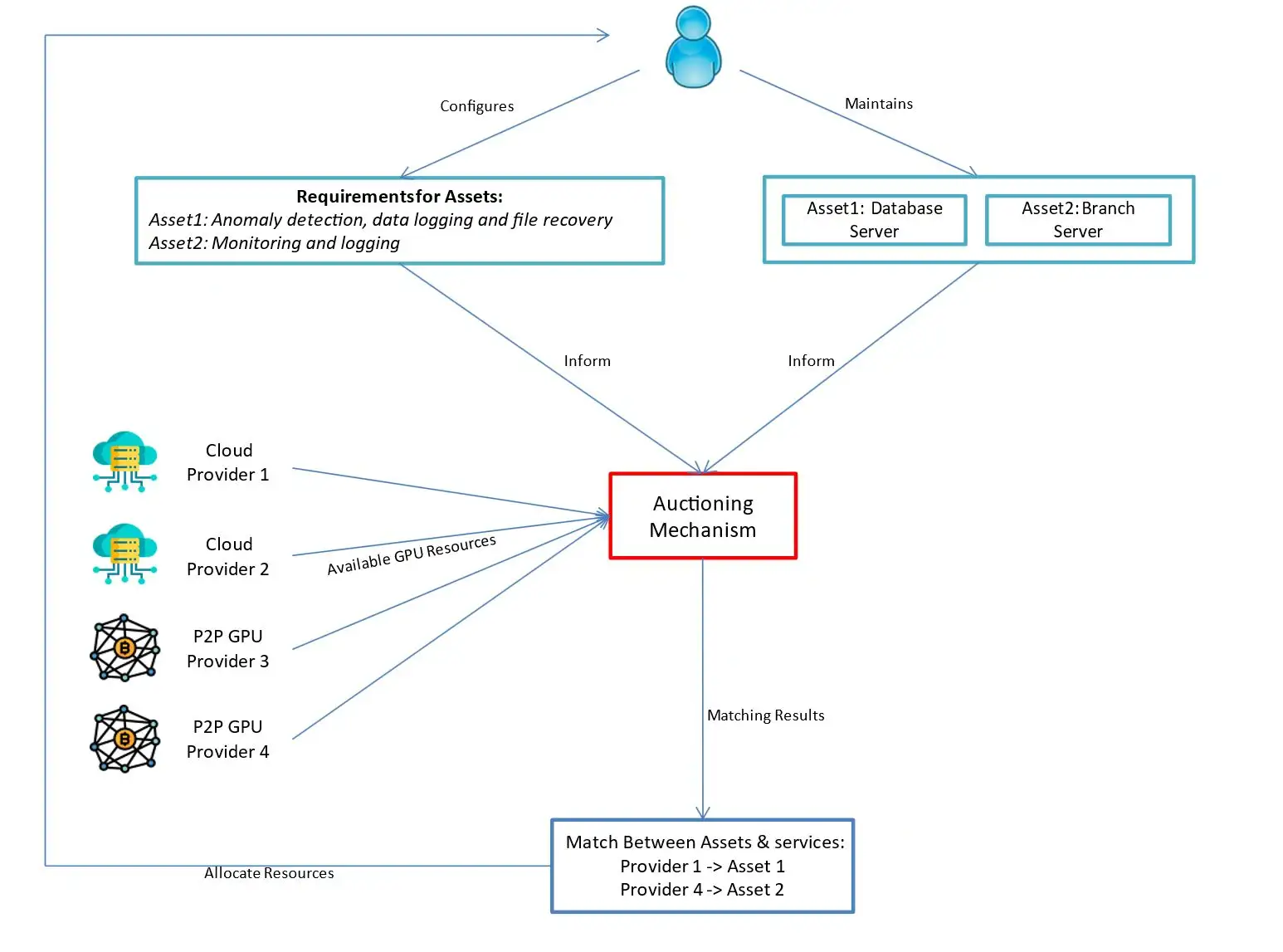
Dynamic Asset Wants
We take an asset centric method to safety to make sure we tailor GPU utilization per system and cater to its precise wants, as a substitute of selling a one-solution-fits-all that may be extra expensive. On this situation the property thought-about embody Firm Z’s servers affected by the ransomware assault that want instant forensic evaluation. Every asset has a set of AI-related computational necessities based mostly on the urgency of the response, sensitivity of the information, and severity of the assault. For instance:
- The major database server shops buyer monetary information and requires intensive GPU assets for anomaly detection, information logging and file restoration operations.
- A department server, used for operational functions, has decrease urgency and requires minimal GPU assets for routine monitoring and logging duties.
Preliminary Situations
The forensic AI system begins by analyzing the ransomware’s root trigger and lateral motion patterns. Firm Z’s major database server is assessed as a important asset with excessive computational calls for, whereas the department server is categorized as a medium-priority asset. The GPUs initially allotted are ample to carry out these duties. Nevertheless, because the assault progresses, the ransomware begins to focus on encrypted backups. That is detected by the deployed brokers which set off a re-prioritization of useful resource allocation.
Adaptation and Resolution Making
The forensic AI system makes use of a Random Forest classifier to research the altering circumstances captured by agent sensors in real-time. It evaluates a number of elements:
- The urgency of duties (e.g., whether or not the ransomware is actively encrypting extra information).
- The sensitivity of the information (e.g., buyer monetary information vs. operational logs).
- Historic patterns of comparable assaults and the related GPU necessities.
- Historic evaluation of incident responder actions on ransomware instances and their related responses.
Based mostly on these inputs, the system dynamically determines new useful resource allocation priorities. As an example, it might determine to allocate further GPUs to the first database server to expedite anomaly detection, system containment and information restoration whereas lowering the assets assigned to the department server.
Market-Impressed GPU Allocation
Given the shortage of GPUs, the system leverages a decentralized agent-based public sale mechanism to accumulate further assets from Cloud and peer-to-peer blockchain suppliers. Every agent submits a bidding worth per asset, reflecting its computational urgency. The first database server submits a excessive bid as a consequence of its important nature, whereas the department server submits a decrease bid. These bids are knowledgeable by historic information, making certain environment friendly use of obtainable assets. The GPU suppliers reply with a variation of the Posted Provide public sale. On this mannequin, suppliers set GPU costs and the variety of accessible situations for a selected time. Belongings with the best bids (indicating probably the most pressing wants) are prioritized for GPU allocation, towards the bids of different customers and their property in want of GPU assets.
As such, the first database server efficiently acquires further GPUs as a consequence of its larger bidding worth, prioritizing file restoration suggestions and anomaly detection, over the department server, with its decrease bid, reflecting a low precedence activity that’s queued to attend for accessible GPU assets.
Evolving Necessities
Because the ransomware assault additional spreads, the sensors detect this exercise. Based mostly on historic patterns of comparable assaults and their related GPU necessities a brand new high-priority activity for analyzing and defending encrypted backups to stop information loss has been created. This activity introduces a brand new computational requirement, prompting the system to submit one other bid for GPUs. The Random Forest algorithm identifies this activity as important and assigns a better bidding worth based mostly on the sensitivity of the impacted information. The public sale mechanism ensures that GPUs are dynamically allotted to this activity, sustaining a steadiness between value and urgency. By means of this adaptive course of, the forensic AI system efficiently prioritizes GPU assets for probably the most important duties. Making certain that Firm Z can shortly mitigate the ransomware assault and information incident responders and safety analysts in recovering delicate information and restoring operations.
Safety Issues
Outsourcing GPU computation introduces dangers associated to information confidentiality, integrity, and availability. Delicate information transmitted to exterior suppliers could also be uncovered to unauthorized entry, both by way of insider threats, misconfigurations, or side-channel assaults.
Moreover, malicious actors may manipulate computational outcomes, inject false information, or intervene with useful resource allocation by inflating bids. Availability dangers additionally come up if an attacker outbids important property, delaying important processes like anomaly detection or file restoration. Regulatory issues additional complicate outsourcing, as information residency and compliance legal guidelines (e.g., GDPR, HIPAA) might limit the place and the way information is processed.
To mitigate these dangers, the place efficiency permits, we leverage encryption strategies reminiscent of homomorphic encryption to allow computations on encrypted information with out exposing uncooked data. Trusted Execution Environments (TEEs) like Intel SGX present safe enclaves that guarantee computations stay confidential and tamper-proof. For integrity, zero-knowledge proofs (ZKPs) permit verification of right computation with out revealing delicate particulars. In instances the place giant quantities of knowledge must be processed, differential privateness strategies can be utilized to hide particular person information factors in datasets by including managed random noise. Moreover, blockchain-based sensible contracts can improve public sale transparency, stopping worth manipulation and unfair useful resource allocation.
From an operational perspective, implementing a multi-cloud or hybrid technique reduces dependency on a single supplier, enhancing availability and redundancy. Robust entry controls and monitoring assist detect unauthorized entry or tampering makes an attempt in real-time. Lastly, implementing strict service-level agreements (SLAs) with GPU suppliers ensures accountability for efficiency, safety, and regulatory compliance. By combining these mitigations, organizations can securely leverage exterior GPU assets whereas minimizing potential threats.
Conceptual Market-based Structure
This part gives a high-level evaluation of the entities and operation phases of the proposed framework.
Brokers
Brokers are autonomous entities that characterize customers within the “GPU market”. An agent is chargeable for utilizing their sensors to watch adjustments within the run-time AI targets and sub-goals of property and set off adaptation for assets. By sustaining information information for every AI operation, it’s possible to assemble coaching datasets to tell the Random Forest algorithm to duplicate such conduct and allocate GPUs in an automatic method. To adapt, the Random Forest algorithm examines the recorded historic information of a consumer and its property to find correlations between earlier AI operations (together with their related GPU utilization) and the prevailing scenario. The outcomes from the Random Forest algorithm are then used to assemble a specification, known as a bid, which displays the precise AI wants and supporting GPU assets. The bid consists of the totally different attributes which might be depending on the issue area. As soon as a bid is fashioned, it’s forwarded to the coordinator (auctioneer) for auctioning.
GPU Useful resource Suppliers (GRP)
Cloud service and peer-to-peer GPU suppliers are distributors that commerce their GPU assets available in the market. They’re chargeable for publicly saying their gives (known as asks) to the coordinator. The asks comprise a specification of the traded assets together with the value that they need to promote them at. In case of a match between an ask and a bid, the GRP allocates the required GPU assets to the successful agent to help their AI operations. Thus, every consumer has entry to totally different configurations of GPU assets which may be supplied by totally different GRPs.
Coordinator
The coordinator is a centralized software program system that capabilities as each an auctioneer and a market regulator, facilitating the allocation of GPU assets. Positioned between brokers and GPU useful resource suppliers (GRPs), it manages buying and selling rounds by accumulating and matching bids from brokers with supplier gives. As soon as the public sale course of is finalized, the coordinator now not interacts straight with customers and suppliers. Nevertheless, it continues to supervise compliance with Service Degree Agreements (SLAs) and ensures that allotted assets are correctly assigned to customers as agreed.
System Operation Phases
The proposed framework consists of 4 (4) phases working in a steady cycle. Beginning with monitoring that passes all related information for evaluation informing the difference course of, which in flip triggers suggestions (allocation of required assets) assembly the altering AI operational necessities. As soon as a set of AI operational necessities are met, the monitoring part begins once more to detect new adjustments. The operational phases are as observe:
Monitor Part
Sensors function on the agent facet to detect adjustments in safety. The kind of information collected varies relying on the particular downside being addressed (safety or in any other case). For instance, within the case of AI-driven risk detection, related adjustments impacting safety would possibly embody:
Behavioral indicators:
- Course of Execution Patterns: Monitoring sudden or suspicious processes (e.g., execution of PowerShell scripts, uncommon system calls).
- Community Site visitors Anomalies: Detecting irregular spikes in information switch, communication with recognized malicious IPs, or unauthorized protocol utilization.
- File Entry and Modification Patterns: Figuring out unauthorized file encryption (potential ransomware), uncommon deletions, or repeated failed entry makes an attempt.
- Person Exercise Deviations: Analyzing deviations in system utilization patterns, reminiscent of extreme privilege escalations, speedy information exfiltration, or irregular working hours.
Content material-based risk indicators:
- Malicious File Signatures: Scanning for recognized malware hashes, embedded exploits, or suspicious scripts in paperwork, emails, or downloads.
- Code and Reminiscence Evaluation: Detecting obfuscated code execution, course of injection, or suspicious reminiscence manipulations (e.g., Reflective DLL Injection, shellcode execution).
- Log File Anomalies: Figuring out irregularities in system logs, reminiscent of log deletion, occasion suppression, or manipulation makes an attempt.
Anomaly-based detection:
- Uncommon Privilege Escalations: Monitoring sudden admin entry, unauthorized privilege elevation, or lateral motion throughout techniques.
- Useful resource Consumption Spikes: Monitoring unexplained excessive CPU/GPU utilization, probably indicating cryptojacking or denial-of-service (DoS) assaults.
- Information Exfiltration Patterns: Detecting giant outbound information transfers, uncommon information compression, or encrypted payloads despatched to exterior servers.
Risk intelligence and correlation:
- Risk Feed Integration: Matching noticed community conduct with real-time risk intelligence sources for recognized indicators of compromise (IoCs).
The info collected by the sensors is then fed right into a watchdog course of, which repeatedly displays for any adjustments that might affect AI operations. This watchdog identifies shifts in safety circumstances or system conduct which will affect how GPU assets are allotted and consumed. As an example, if an AI agent detects an uncommon login try from a high-risk location, it might require further GPU assets to carry out extra intensive risk evaluation and advocate acceptable actions for enhanced safety.
Evaluation Part
In the course of the evaluation part the information recorded from the sensors are examined to find out if the prevailing GPU assets can fulfill the runtime AI operational targets and sub-goals of an asset. In case the place they’re deemed inadequate adaptation is triggered. We undertake a goal-oriented method to map safety targets to their sub-goals. Important adjustments to the dynamics of a number of interrelated sub-goals can set off the necessity for adaptation. As adaptation is dear, the frequency of adaptation might be decided by contemplating the extent to which the safety targets and sub-goals diverge from the tolerance degree.
Adaptation Part
Adaptation entails bid formulation by brokers, ask formulation by GPU suppliers, and the auctioning course of to find out optimum matches. It additionally consists of the allocation of GPU assets to customers. The variation course of operates as follows.
Bid Formulation
Adaptation initiates with the creation of a bid that requests the invention, choice and allocation of GPU assets from totally different GRPs available in the market. The bid is constructed with the help of the Random Forest algorithm which identifies the optimum plan of action for adaptation based mostly on beforehand encountered AI operations and their GPU utilization. The usage of ensemble classifiers, reminiscent of Random Forest, permits for mitigating bias and information overfitting as a consequence of their excessive variance. The constructed bids include the next attributes: i) the asset linked with AI operations; ii) the criticality of the operations; iii) the sub-goals that require help; iv) an approximate quantity of GPU assets that shall be utilized and v) the best worth {that a} consumer is prepared to pay (might be calculated by taking the typical worth of all comparable historic bids).
To find out how the selection of an public sale can have an effect on the price of an answer for customers, the proposed framework considers two dominant market mechanisms, particularly the English public sale and a variant of the Posted-offer public sale mannequin. Consequently, we use two totally different strategies to calculate the bidding costs when forming bids. Our modified Posted Provide public sale mannequin is based on a take-it-or-leave-it foundation. On this mannequin, the GRPs publicly announce the buying and selling assets together with their related prices for a sure buying and selling interval. In the course of the buying and selling interval, brokers are chosen (one by one) in descending order based mostly on their bidding costs (as a substitute of being chosen randomly) and allowed to just accept or decline GRP gives. By introducing consumer bidding costs within the Posted Provide mannequin, it’s attainable for the self-adaptive system to find out if a consumer can afford to pay a vendor’s requested worth, therefore automating the choice course of. In addition to utilizing bidding costs as a heuristic for rating / choosing customers based mostly on the criticality of their requests. The auctioning spherical continues till all patrons have acquired service, or till all provided GPU assets have been allotted. Brokers decide their bidding costs in Posted Provide by calculating the typical worth of all historic bidding costs with comparable nature and criticality after which enhance or lower that worth by a proportion “p”. The calculated bidding worth is the best worth {that a} consumer is prepared to bid on in an public sale. As soon as the bidding worth is calculated, the agent provides the value together with the opposite required attributes in a bid.
Equally, the English public sale process follows comparable steps to the Posted Provide mannequin to calculate bidding costs. Within the English public sale mannequin, the bidding worth initiates at a low worth (established by the GRPs) after which raises incrementally, reminiscent of progressively larger bids are solicited till the public sale is closed, or no larger bids are acquired. Subsequently, every agent calculates its highest bidding worth by contemplating the closing costs of accomplished auctions, in distinction to the fastened bidding costs used within the Posted Provide mannequin.
Ask Formulation
GRPs on their facet type their gives / asks which they ahead to the coordinator for auctioning. GRPs decide the value of their GPU assets based mostly on the historic information of submitted asks. A possible method to calculate the promoting worth is to take the typical worth of beforehand submitted ask costs after which subtract or add a proportion “p” on that worth, relying on the revenue margin a GRP needs to make. As soon as the promoting worth is calculated, the brokers encapsulate the value together with a specification of the provided assets in an ask. Upon creation of the bid, it’s forwarded to the public sale coordinator.
Auctioning
As soon as bids and asks are acquired, the coordinator enters them in an public sale to find GPU assets that may greatest fulfill the AI operational targets and sub-goals of various property and customers, whereas catering for optimum prices. Relying on the tactic chosen for calculating the bid and ask costs (i.e., Posted Provide or English public sale), there may be a similar process for auctioning.
Within the case the place the Posted Provide methodology is employed, the coordinator discovers GRPs that may help the runtime AI targets and sub-goals of an asset / consumer by evaluating the useful resource specification in an ask with the bid specification. Particularly, the coordinator compares the: quantity of GPU assets and worth to find out the suitability of a service for an agent. Within the case the place an ask violates any of the required necessities and constraints (e.g., a service gives insufficient computational assets) of an asset, the ask is eradicated. Upon elimination of all unsuitable asks, the coordinator kinds brokers in a descending worth order to rank them based mostly on the criticality of their bids / requests. Following, the auctioneer selects brokers (one by one) ranging from the highest of the record to permit them to buy the wanted assets till all brokers are served or till all accessible models are bought.
Within the event the place the English public sale is used, the coordinator discovers all on-going auctions that fulfill the: computational necessities and bidding worth and units a bid on behalf of the agent. The bidding worth displays the present highest worth in an public sale plus a bid increment worth “p”. The bid increment worth is the minimal quantity by which an agent’s bid might be raised to develop into the best bidder. The bid increment worth might be decided based mostly on the best bid in an public sale. These values are case particular, and they are often altered by brokers in line with their runtime wants and the market costs. Within the event the place a rival agent tries to outbid the successful agent, the out-bid agent robotically will increase its biding worth to stay the best bidder, while making certain that the best worth laid out in its bid shouldn’t be violated. The successful public sale, wherein a match happens, is the one wherein an agent has set a bid and, upon completion of the public sale spherical, has remained the best bidder. If a match happens and the agent has set a bid to multiple ongoing public sale that trades comparable companies/assets, these bids are discarded. Submitting a number of bids to multiple public sale that trades comparable assets is permitted to extend the probability of a match occurring.
Suggestions Part
As soon as a match happens, the suggestions part is initiated, throughout which the coordinator notifies the successful GRP and agent to begin the commerce. The agent is requested to ahead the cost for the received assets to the GRP. The transaction is recorded by the coordinator to make sure that no social gathering will lie in regards to the validity of the cost and allocation. Within the case the place the auctioning was carried out based mostly on the English public sale, the agent must pay the value of the second highest bid plus an outlined bid increment, whereas if the Posted Provide public sale was used the fastened worth set by a GRP is paid. As soon as cost is acquired, the Service Supplier releases the requested assets. Useful resource allocation might be carried out in two methods, relying on the GRP: both by way of a cloud container offering entry to all GPU assets throughout the atmosphere, or by making a community drive that permits a direct, native interface to the consumer’s system. The coordinator is paid for its auctioning companies by including a small fee payment for each profitable match which is equally break up between the successful agent and GRP.
We’d love to listen to what you assume! Ask a query, remark beneath, and keep linked with Cisco Safety on social media.
Cisco Safety Social Channels
Share:

 Area")