
- We set up the Postgres extension referred to as pgvector, which allows tables to have columns of sort vector the place vector is a set of floats. On this instance we use a 768-dimensional vector, i.e. a vector of size 768.
- We create a desk that may save the articles for our data base — the textual content of every article, the title of the article, and a vector embedding of the article textual content. We title the desk
articlesand the columnstitle,textual content, andembedding. - We extract the content material at 4 Wikipedia URLs and separate the title and content material for every.
- We clear every article physique, divide the textual content into chunks of 500 characters, and use an embedding mannequin to create a 768-dimensional vector from every chunk. The vector is a numerical illustration (a float) of the that means of the chunk of textual content.
- We save the title, a piece from the physique, and the embedding vector for the chunk in a row of the database. For every article, there are as many vectors as there are chunks.
- We index the vector column for similarity search in Half 2.
import psycopg2
from sentence_transformers import SentenceTransformer
import requests
from bs4 import BeautifulSoup
import re
import ollama
# Your connection params right here
MY_DB_HOST = 'localhost'
MY_DB_PORT = 5432
MY_DB_NAME = 'nitin'
MY_DB_USER = 'nitin'
MY_DB_PASSWORD = ''
# Arrange the database connection
conn = psycopg2.join(
host=MY_DB_HOST,
port=MY_DB_PORT,
dbname=MY_DB_NAME,
person=MY_DB_USER,
password=MY_DB_PASSWORD
)
cur = conn.cursor()
# Create the articles desk with the pgvector extension
# If the pgvector extension shouldn't be put in in your machine it should must be put in.
# See https://github.com/pgvector/pgvector or cloud situations with pgvector put in.
# First create the pgvector extension, then a desk with a 768 dim vector column for embeddings.
# Word that the title and full textual content of the article can be saved with the embedding.
# This permits vector similarity search on the embedding column, returning matched textual content
# together with matched embeddings relying on what is required.
# After this SQL command is executed we can have
# a) a pgvector extension put in if it didn't exist already
# b) an empty desk with a column of sort vector together with two columns,
# one to avoid wasting the title of the article and one to avoid wasting a piece of textual content.
# Postgres doesn't put a restrict on the variety of dimensions in pgvector embeddings.
# It's value experimenting with bigger lengths however word they should match the size of embeddings
# created by the mannequin you utilize. Embeddings of ~1k, 2k, or extra dimensions are frequent amongst embeddings APIs.
cur.execute('''
CREATE EXTENSION IF NOT EXISTS vector;
DROP TABLE IF EXISTS articles;
CREATE TABLE articles (
id SERIAL PRIMARY KEY,
title TEXT,
textual content TEXT,
embedding VECTOR(768)
);
''')
conn.commit()
# Under are the sources of content material for creating embeddings to be inserted in our demo vector db.
# Be happy so as to add your individual hyperlinks however word that totally different sources aside from Wikipedia could
# have totally different junk characters and should require totally different pre-processing.
# As a begin strive different Wikipedia pages, then increase to different sources.
urls= [
'https://en.wikipedia.org/wiki/Pentax_K-x',
'https://en.wikipedia.org/wiki/2008_Tour_de_France',
'https://en.wikipedia.org/wiki/Onalaska,_Texas',
'https://en.wikipedia.org/wiki/List_of_extinct_dog_breeds'
]
# Fetch the HTML at a given hyperlink and extract solely the textual content, separating title and content material.
# We'll use this textual content to extract content material from Wikipedia articles to reply queries.
def extract_title_and_content(url):
strive:
response = requests.get(url)
if response.status_code == 200: # success
# Create a BeautifulSoup object to parse the HTML content material
soup = BeautifulSoup(response.content material, 'html.parser')
# Extract the title of the web page
title = soup.title.string.strip() if soup.title else ""
# Extract the textual content content material from the web page
content material = soup.get_text(separator=" ")
return {"title": title, "textual content": content material}
else:
print(f"Did not retrieve content material from {url}. Standing code: {response.status_code}")
return None
besides requests.exceptions.RequestException as e:
print(f"Error occurred whereas retrieving content material from {url}: {str(e)}")
return None
# Create the embedding mannequin
# That is the mannequin we use to generate embeddings, i.e. to encode textual content chunks into numeric vectors of floats.
# Sentence Transformers (sbert.internet) is a set of transformer fashions designed for creating embeddings
# from sentences. These are skilled on knowledge units used for various functions. We use one tuned for Q&A,
# therefore the 'qa' within the title. There are different embedding fashions, some tuned for velocity, some for breadth, and so on.
# The positioning sbert.internet is value finding out for selecting the correct mannequin for different makes use of. It is also value wanting
# on the embedding fashions of suppliers like OpenAI, Cohere, and so on. to study the variations, however word that
# the usage of a web based mannequin includes a possible lack of privateness.
embedding_model = SentenceTransformer('multi-qa-mpnet-base-dot-v1')
articles = []
embeddings = []
# Extract title,content material from every URL and retailer it within the listing.
for url in urls:
article = extract_title_and_content(url)
if article:
articles.append(article)
for article in articles:
raw_text = article["text"]
# Pre-processing: Exchange massive chunks of white area with an area, eradicate junk characters.
# It will differ with every supply and can want customized cleanup.
textual content = re.sub(r's+', ' ', raw_text)
textual content = textual content.substitute("]", "").substitute("[", "")
# chunk into 500 character chunks, this is a typical size, could be lower if total size of article is small.
chunks = [text[i:i + 500] for i in vary(0, len(textual content), 500)]
for chunk in chunks:
# That is the place we invoke our mannequin to generate a listing of floats.
# The embedding mannequin returns a numpy ndarray of floats.
# Psycopg coerces the listing right into a vector for insertion.
embedding = embedding_model.encode([chunk])[0].tolist()
cur.execute('''
INSERT INTO articles (title, textual content, embedding)
VALUES (%s, %s, %s); ''', (article["title"], chunk, embedding)
)
embeddings.append(embedding)
conn.commit()
# Create an index
# pgvector permits totally different indexes for similarity search.
# See the docs within the README at https://github.com/pgvector/pgvector for detailed explanations.
# Right here we use 'hnsw' which is an index that assumes a Hierarchical Community Small Worlds mannequin.
# HNSW is a sample seen in community fashions of language. Therefore this is among the indexes
# that's anticipated to work properly for language embeddings. For this small demo it should in all probability not
# make a lot of a distinction which index you utilize, and the others are additionally value attempting.
# The parameters offered within the 'USING' clause are 'embedding vector_cosine_ops'
# The primary, 'embedding' on this case, must match the title of the column which holds embeddings.
# The second, 'vector_cosine_ops', is the operation used for similarity search i.e. cosine similarity.
# The identical README doc on GitHub offers different decisions however for commonest makes use of it makes little distinction
# therefore cosine similarity is used as our default.
cur.execute('''
CREATE INDEX ON articles USING hnsw (embedding vector_cosine_ops);
''')
conn.commit()
cur.shut()
conn.shut()
# Finish of file
Half 2. Retrieve context from the vector database and question the LLM
Partly 2 we ask a pure language query of our data base, utilizing similarity search to discover a context and utilizing an LLM (on this case Meta’s Llama 3) to generate a solution to the query within the offered context. The steps:
- We encode our pure language question as a vector utilizing the identical embedding mannequin we used to encode the chunks of textual content we extracted from the Wikipedia pages.
- We carry out a similarity search on this vector utilizing a SQL question. Similarity, or particularly cosine similarity, is a solution to discover the vectors in our database which are nearest to the vector question. As soon as we discover the closest vectors, we will use them to retrieve the corresponding textual content that’s saved with every vector. That’s the context for our question to the LLM.
- We append this context to our pure language question textual content, explicitly telling the LLM that the offered textual content is to be taken because the context for answering the question.
- We use a programmatic wrapper round Ollama to go the pure language question and contextual textual content to the LLM’s request API and fetch the response. We submit three queries, and we obtain the reply in context for every question. An instance screenshot for the primary question is proven under.
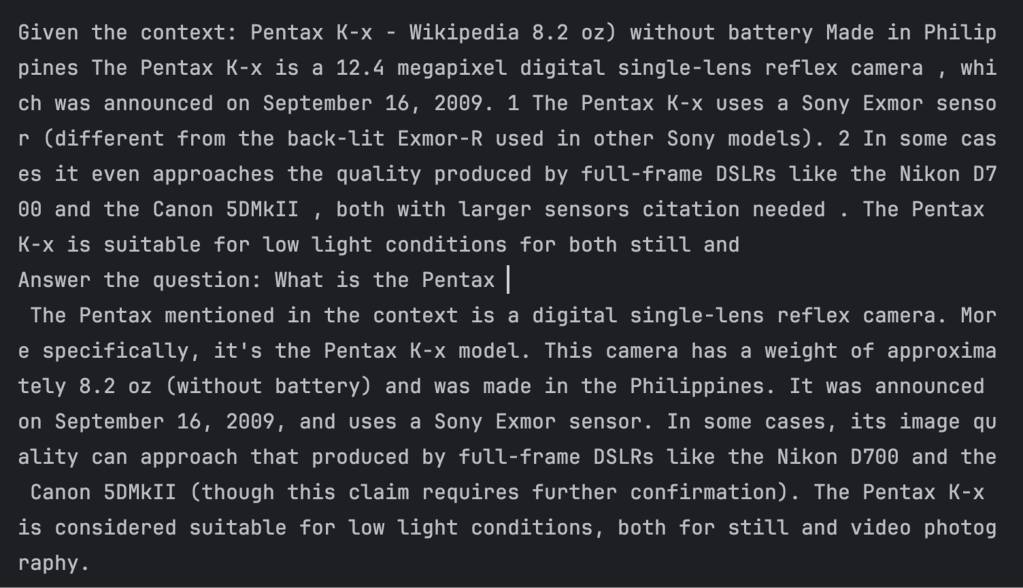
IDG

