
Complexities of Extracting SQL Server Information
Whereas digital native firms acknowledge AI’s essential position in driving innovation, many nonetheless face challenges in making their information available for downstream makes use of, comparable to machine studying growth and superior analytics. For these organizations, supporting enterprise groups that depend on SQL Server means having information engineering assets and sustaining customized connectors, getting ready information for analytics, and making certain it’s obtainable to information groups for mannequin growth. Usually, this information must be enriched with extra sources and reworked earlier than it may possibly inform data-driven selections.
Sustaining these processes rapidly turns into complicated and brittle, slowing down innovation. That’s why Databricks developed Lakeflow Join, which incorporates built-in information connectors for common databases, enterprise purposes, and file sources. These connectors present environment friendly end-to-end, incremental ingestion, are versatile and simple to arrange, and are totally built-in with the Databricks Information Intelligence Platform for unified governance, observability, and orchestration. The brand new Lakeflow SQL Server connector is the primary database connector with sturdy integration for each on-premises and cloud databases to assist derive information insights from inside Databricks.
On this weblog, we’ll assessment the important thing issues for when to make use of Lakeflow Join for SQL Server and clarify the right way to configure the connector to duplicate information from an Azure SQL Server occasion. Then, we’ll assessment a particular use case, greatest practices, and the right way to get began.
Key Architectural Issues
Under are the important thing issues to assist determine when to make use of the SQL Server connector.
Area & Function Compatibility
Lakeflow Join helps a wide selection of SQL Server database variations, together with Microsoft Azure SQL Database, Amazon RDS for SQL Server, Microsoft SQL Server operating on Azure VMs and Amazon EC2, and on-premises SQL Server accessed via Azure ExpressRoute or AWS Direct Join.
Since Lakeflow Join runs on Serverless pipelines beneath the hood, built-in options comparable to pipeline observability, occasion log alerting, and lakehouse monitoring might be leveraged. If Serverless will not be supported in your area, work along with your Databricks Account crew to file a request to assist prioritize growth or deployment in that area.
Lakeflow Join is constructed on the Information Intelligence Platform, which offers seamless integration with Unity Catalog (UC) to reuse established permissions and entry controls throughout new SQL Server sources for unified governance. In case your Databricks tables and views are on Hive, we advocate upgrading them to UC to profit from these options (AWS | Azure | GCP)!
Change Information Necessities
Lakeflow Join might be built-in with an SQL Server with Microsoft change monitoring (CT) or Microsoft Change Information Seize (CDC) enabled to help environment friendly, incremental ingestion.
CDC offers historic change details about insert, replace, and delete operations, and when the precise information has modified. Change monitoring identifies which rows had been modified in a desk with out capturing the precise information modifications themselves. Study extra about CDC and the advantages of utilizing CDC with SQL Server.
Databricks recommends utilizing change monitoring for any desk with a major key to attenuate the load on the supply database. For supply tables with no major key, use CDC. Study extra about when to make use of it right here.
The SQL Server connector captures an preliminary load of historic information on the primary run of your ingestion pipeline. Then, the connector tracks and ingests solely the modifications made to the info because the final run, leveraging SQL Server’s CT/CDC options to streamline operations and effectivity.
Governance & Personal Networking Safety
When a connection is established with a SQL Server utilizing Lakeflow Join:
- Visitors between the consumer interface and the management airplane is encrypted in transit utilizing TLS 1.2 or later.
- The staging quantity, the place uncooked information are saved throughout ingestion, is encrypted by the underlying cloud storage supplier.
- Information at relaxation is protected following greatest practices and compliance requirements.
- When configured with personal endpoints, all information site visitors stays inside the cloud supplier’s personal community, avoiding the general public web.
As soon as the info is ingested into Databricks, it’s encrypted like different datasets inside UC. The ingestion gateway that extracts snapshots, change logs, and metadata from the supply database lands in a UC Quantity, a storage abstraction greatest for registering non-tabular datasets comparable to JSON information. This UC Quantity resides inside the buyer’s cloud storage account inside their Digital Networks or Digital Personal Clouds.
Moreover, UC enforces fine-grained entry controls and maintains audit trails to manipulate entry to this newly ingested information. UC Service credentials and Storage Credentials are saved as securable objects inside UC, making certain safe and centralized authentication administration. These credentials are by no means uncovered in logs or hardcoded into SQL ingestion pipelines, offering sturdy safety and entry management.
In case your group meets the above standards, take into account Lakeflow Join for SQL Server to assist simplify information ingestion into Databricks.
Breakdown of Technical Answer
Subsequent, assessment the steps for configuring Lakeflow Join for SQL Server and replicating information from an Azure SQL Server occasion.
Configure Unity Catalog Permissions
Inside Databricks, guarantee serverless compute is enabled for notebooks, workflows, and pipelines (AWS | Azure | GCP). Then, validate that the person or service principal creating the ingestion pipeline has the next UC permissions:
|
Permission Sort |
Purpose |
Documentation |
|
CREATE CONNECTION on the metastore |
Lakeflow Join wants to ascertain a safe connection to the SQL Server. |
|
|
USE CATALOG on the goal catalog |
Required because it offers entry to the catalog the place Lakeflow Join will land the SQL Server information tables in UC. |
|
|
USE SCHEMA, CREATE TABLE, and CREATE VOLUME on an current schema or CREATE SCHEMA on the goal catalog |
Supplies the required rights to entry schemas and create storage places for ingested information tables. |
|
|
Unrestricted permissions to create clusters, or a customized cluster coverage |
Required to spin up the compute assets required for the gateway ingestion course of |
Arrange Azure SQL Server
To make use of the SQL Server connector, verify that the next necessities are met:
- Affirm SQL Model
- SQL Server 2012 or a later model should be enabled to make use of change monitoring. Nevertheless, 2016+ is really helpful*. Assessment SQL Model necessities right here.
- Configure the Database service account devoted to the Databricks ingestion.
- Allow change monitoring or built-in CDC
- You should have SQL Server 2012 or a later model to make use of CDC. Variations sooner than SQL Server 2016 moreover require the Enterprise version.
* Necessities as of Could 2025. Topic to alter.
Instance: Ingesting from Azure SQL Server to Databricks
Subsequent, we are going to ingest a desk from an Azure SQL Server database to Databricks utilizing Lakeflow Join. On this instance, CDC and CT present an summary of all obtainable choices. For the reason that desk on this instance has a major key, CT may have been the first alternative. Nevertheless, since there is just one small desk on this instance, there isn’t any concern about load overhead, so CDC was additionally included. It’s endorsed to assessment when to make use of CDC, CT, or each to find out which is greatest to your information and refresh necessities.
1. [Azure SQL Server] Confirm and Configure Azure SQL Server for CDC and CT
Begin by accessing the Azure portal and signing in utilizing your Azure account credentials. On the left-hand facet, click on All providers and seek for SQL Servers. Discover and click on your server, and click on the ‘Question Editor’; on this instance, sqlserver01 was chosen.
The screenshot beneath exhibits that the SQL Server database has one desk referred to as ‘drivers’.
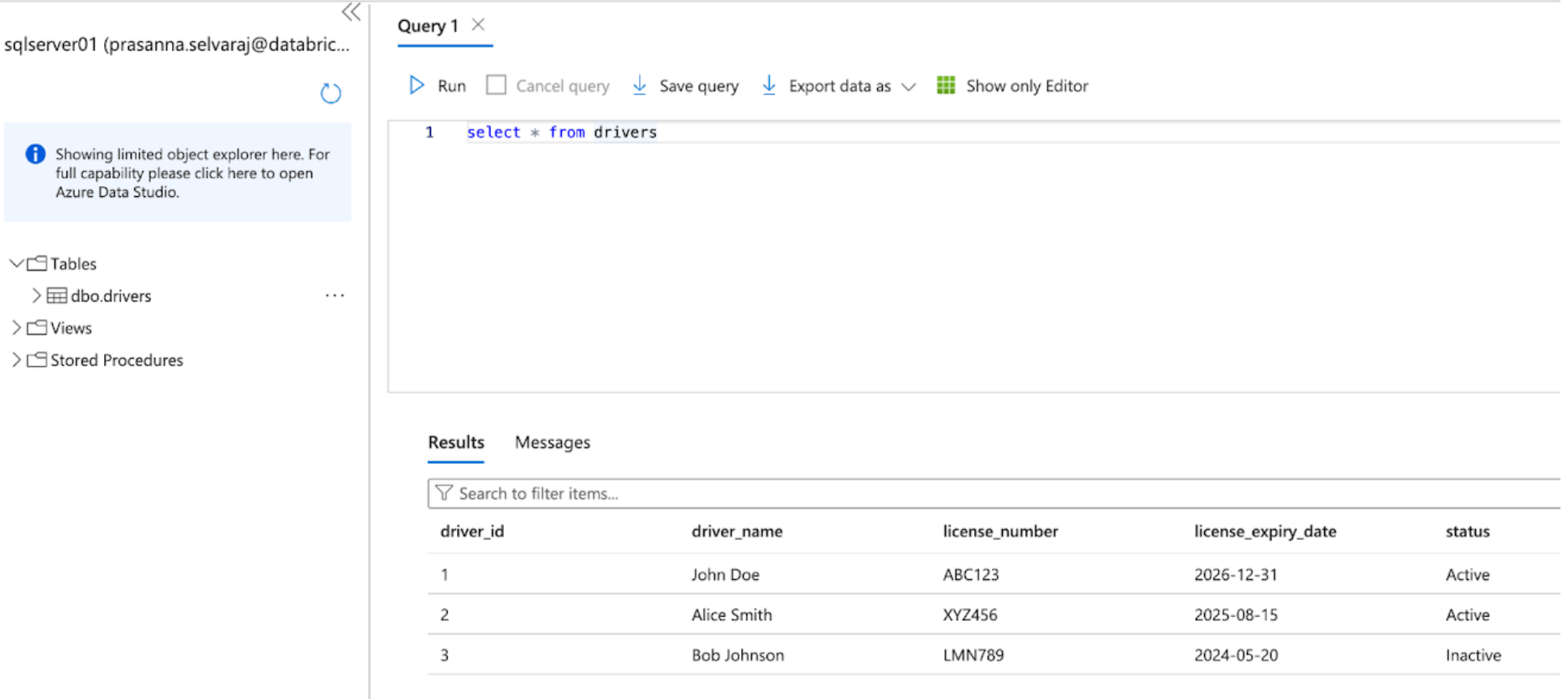
Earlier than replicating the info to Databricks, both change information seize, change monitoring, or each should be enabled.
For this instance, the next script is run on the database to allow CT:
This command permits change monitoring for the database with the next parameters:
- CHANGE_RETENTION = 3 DAYS: This worth tracks modifications for 3 days (72 hours). A full refresh will probably be required in case your gateway is offline longer than the set time. It’s endorsed that this worth be elevated if extra prolonged outages are anticipated.
- AUTO_CLEANUP = ON: That is the default setting. To take care of efficiency, it robotically removes change monitoring information older than the retention interval.
Then, the next script is run on the database to allow CDC:
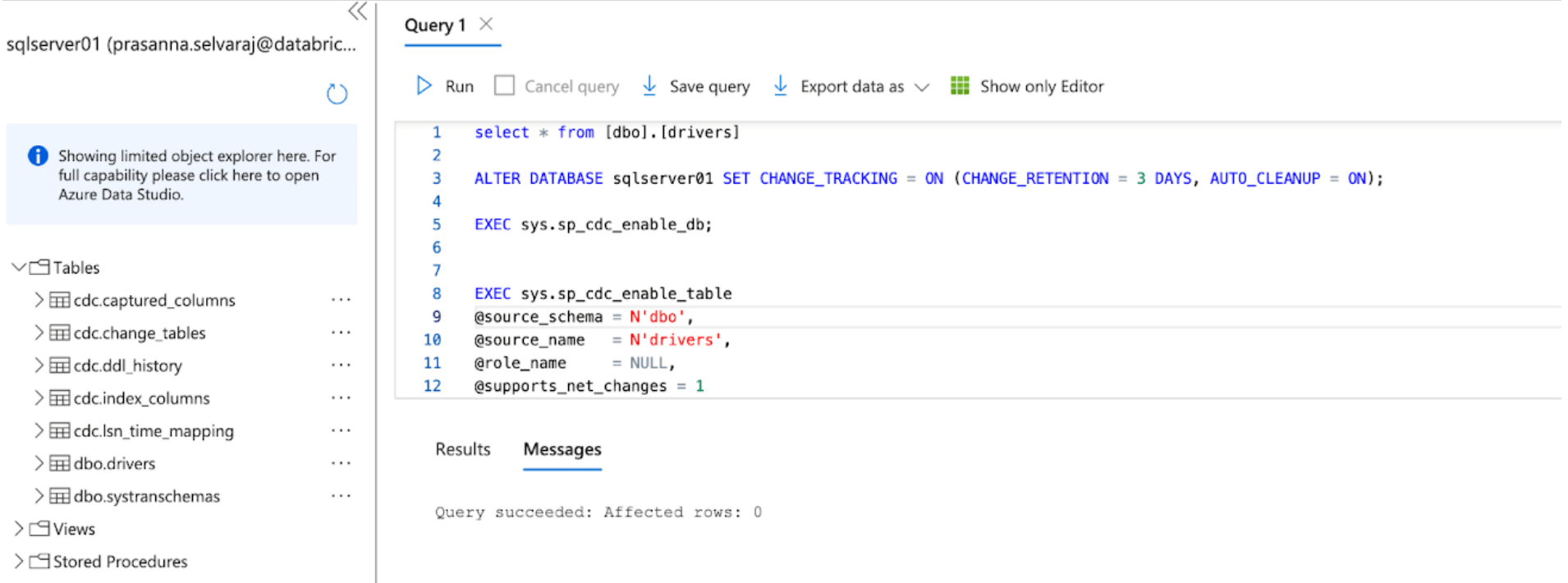
When each scripts end operating, assessment the tables part beneath the SQL Server occasion in Azure and be sure that all CDC and CT tables are created.
2. [Databricks] Configure the SQL Server connector in Lakeflow Join
On this subsequent step, the Databricks UI will probably be proven to configure the SQL Server connector. Alternatively, Databricks Asset Bundles (DABs), a programmatic technique to handle the Lakeflow Join pipelines as code, will also be leveraged. An instance of the complete DABs script is within the appendix beneath.
As soon as all of the permissions are set, as specified by the Permission Conditions part, you might be able to ingest information. Click on the + New button on the prime left, then choose Add or Add information.
Then choose the SQL Server choice.
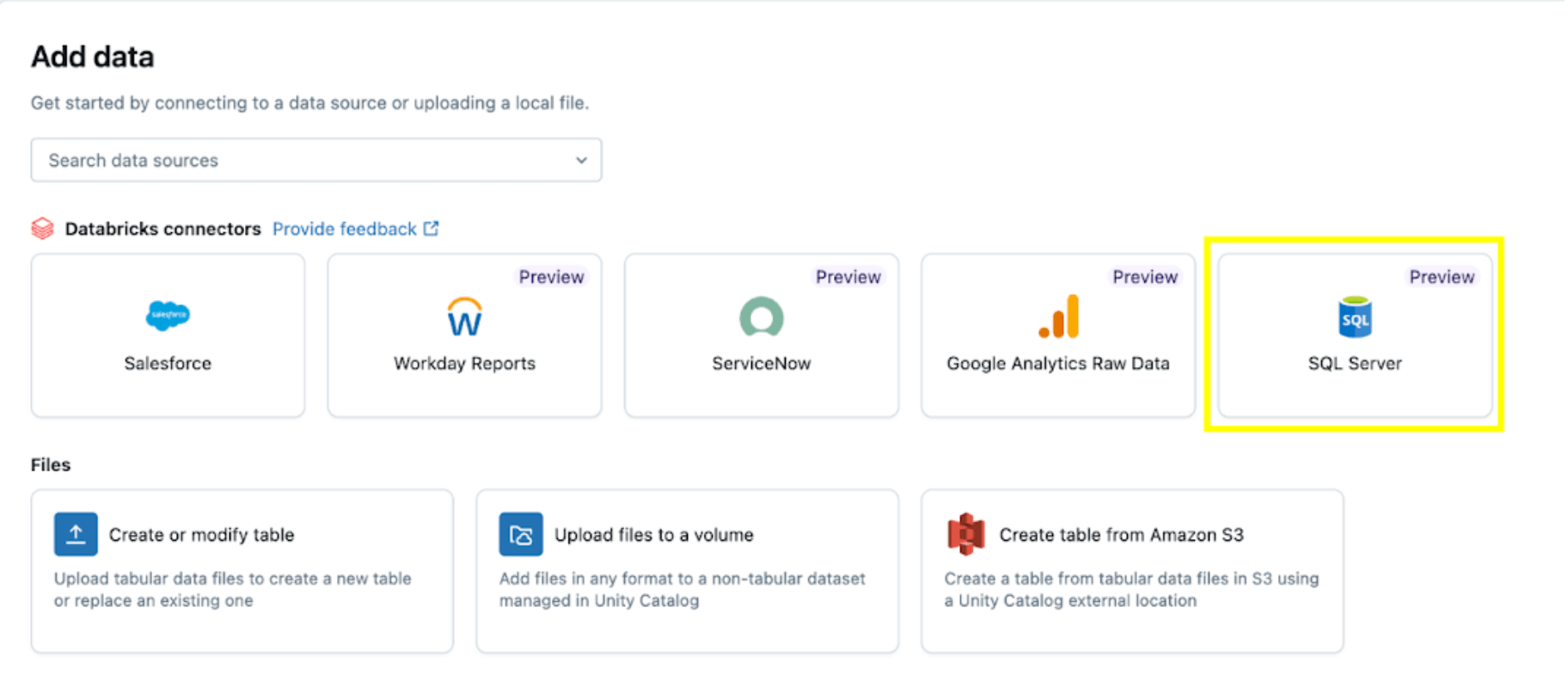
The SQL Server connector is configured in a number of steps.
1. Arrange the ingestion gateway (AWS | Azure | GCP). On this step, present a reputation for the ingestion gateway pipeline and a catalog and schema for the UC Quantity location to extract snapshots and frequently change information from the supply database.
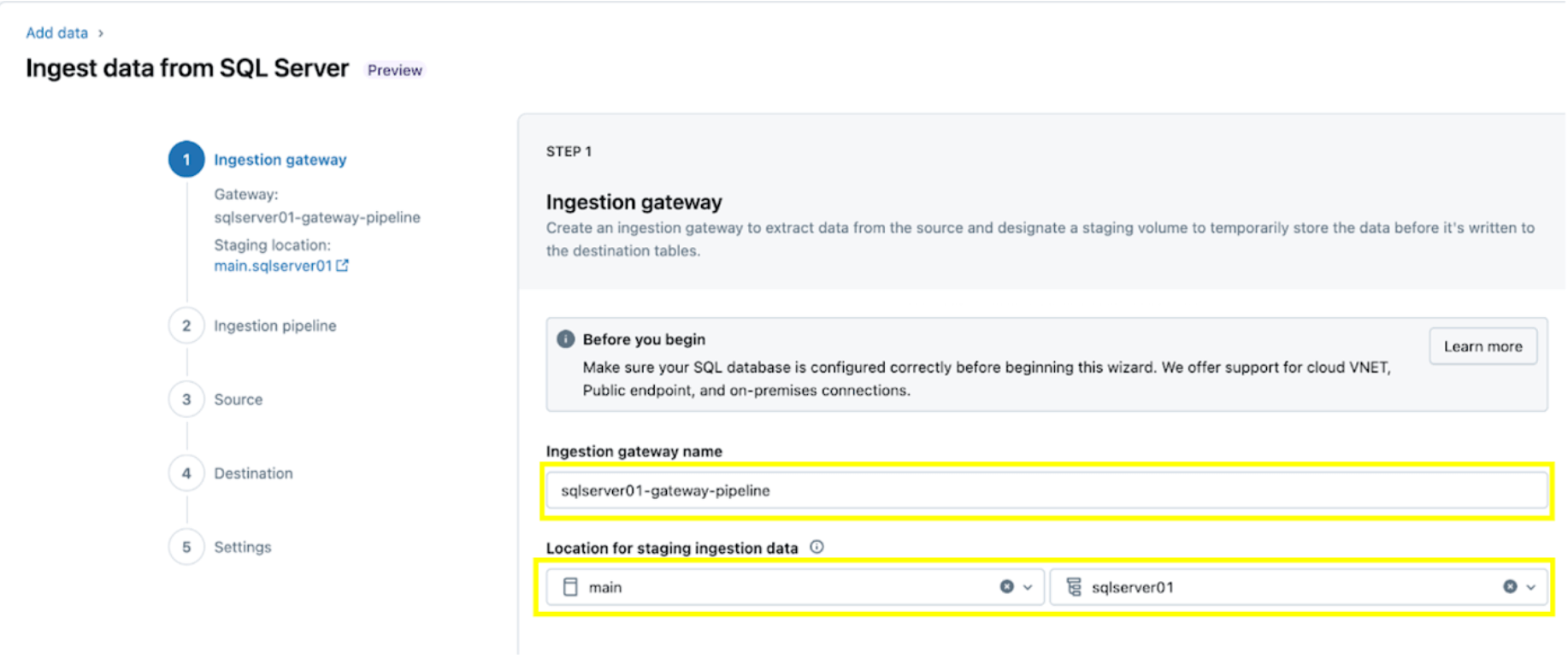
2. Configure the ingestion pipeline. This replicates the CDC/CT information supply and the schema evolution occasions. A SQL Server connection is required, which is created via the UI following these steps or with the next SQL code beneath:
For this instance, title the SQL server connection insurgent as proven.
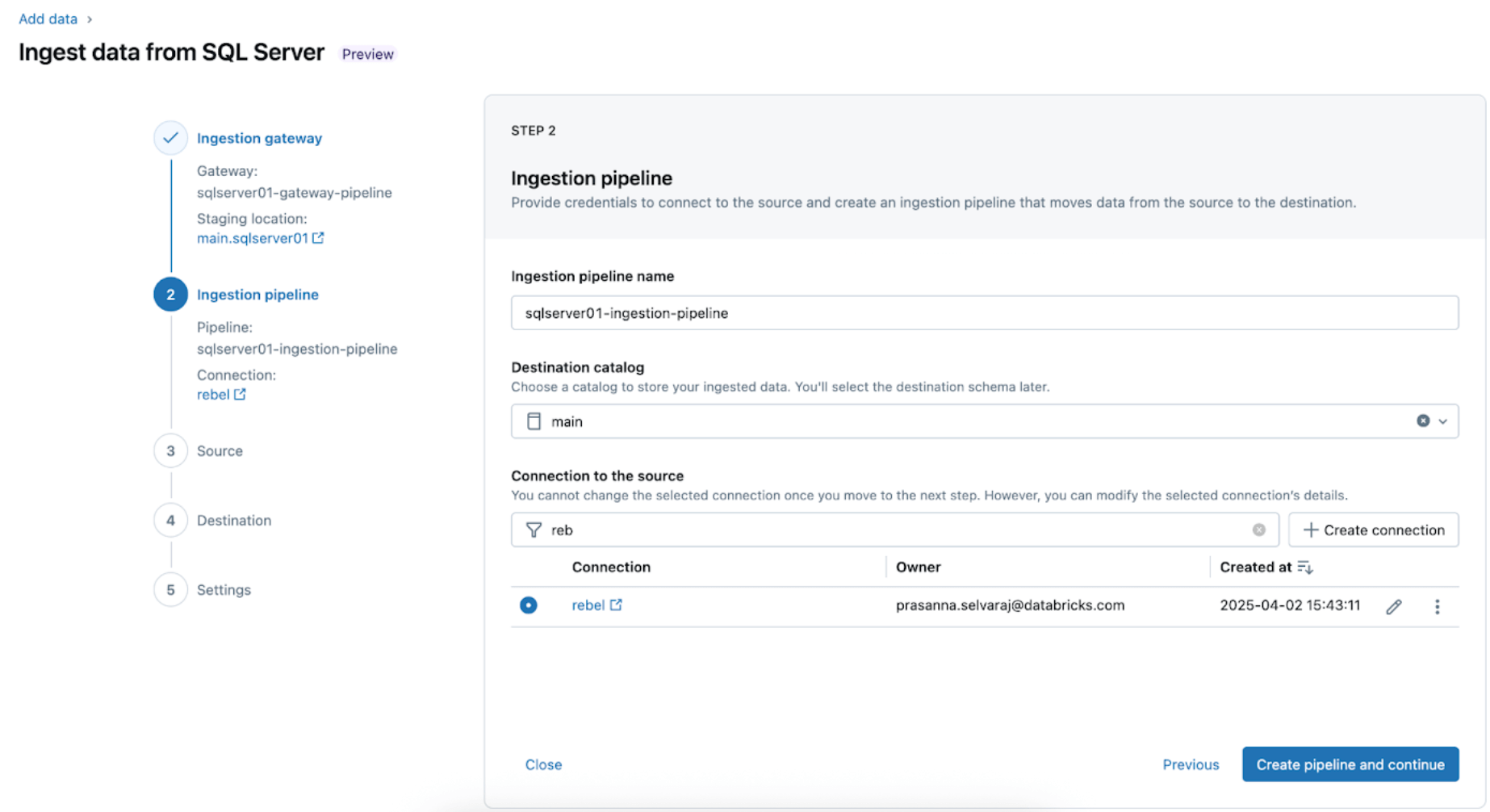
3. Deciding on the SQL Server tables for replication. Choose the entire schema to be ingested into Databricks as an alternative of selecting particular person tables to ingest.
The entire schema might be ingested into Databricks throughout preliminary exploration or migrations. If the schema is massive or exceeds the allowed variety of tables per pipeline (see connector limits), Databricks recommends splitting the ingestion throughout a number of pipelines to take care of optimum efficiency. To be used case-specific workflows comparable to a single ML mannequin, dashboard, or report, it’s typically extra environment friendly to ingest particular person tables tailor-made to that particular want, quite than the entire schema.
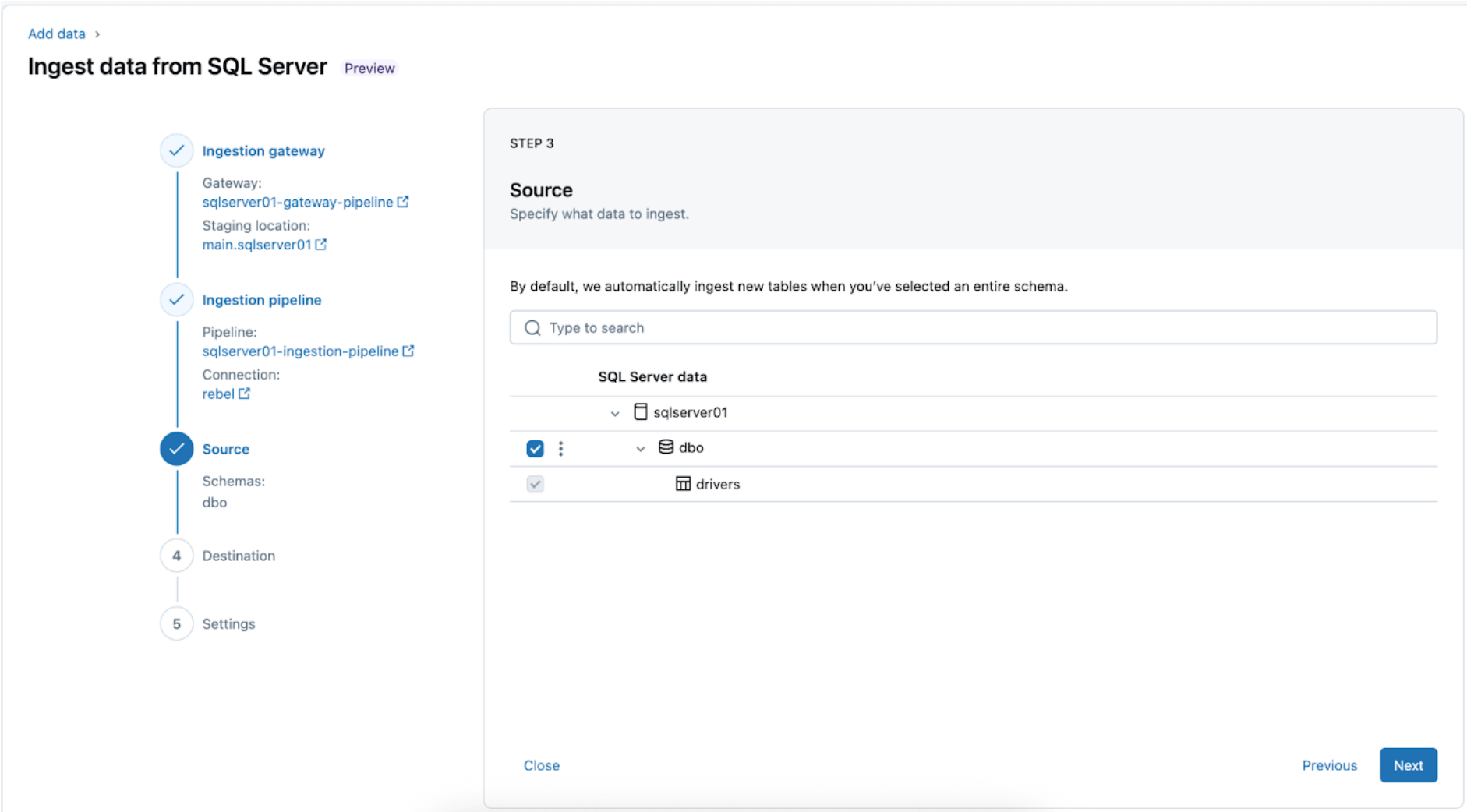
4. Configure the vacation spot the place the SQL Server tables will probably be replicated inside UC. Choose the foremost catalog and sqlserver01 schema to land the info in UC.
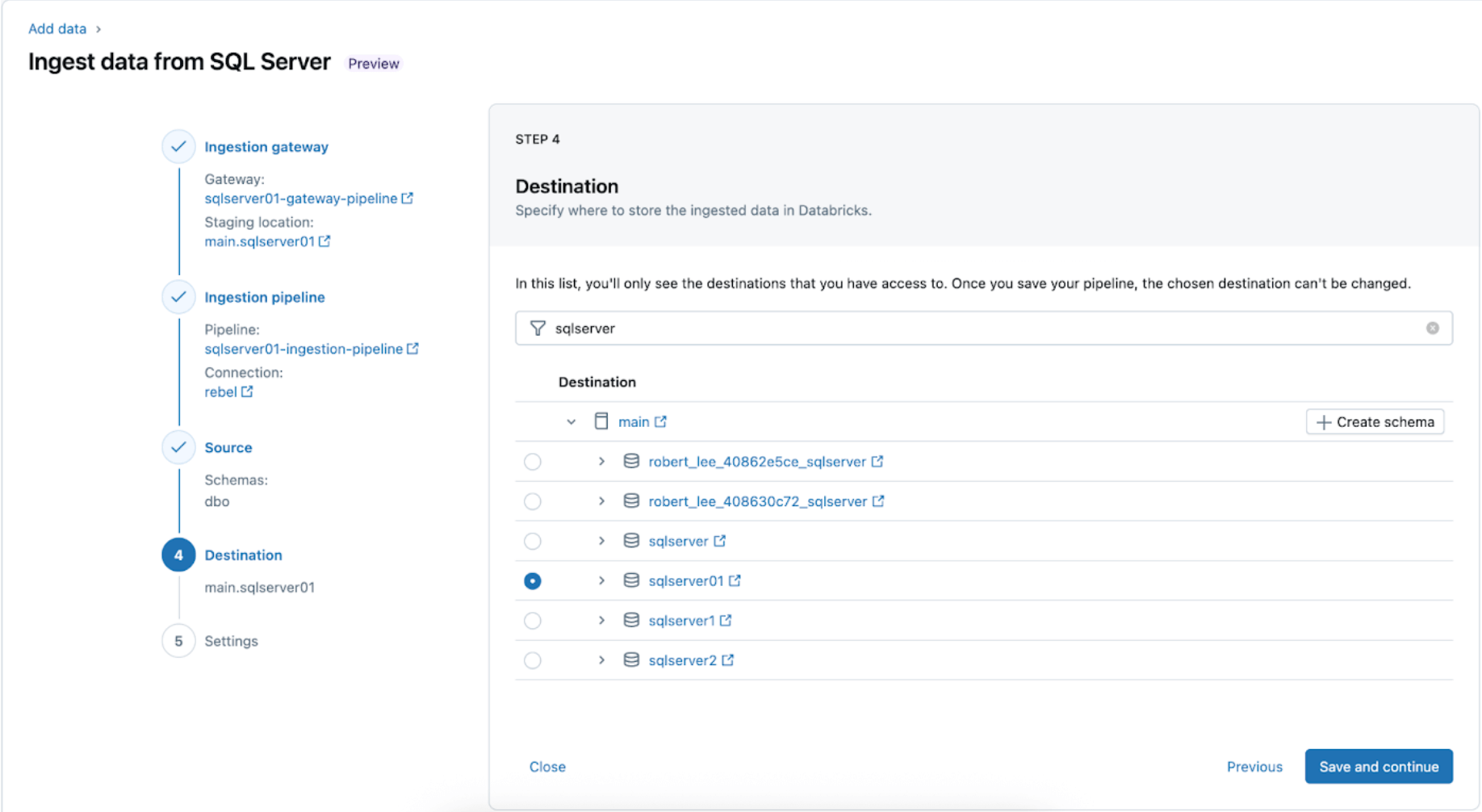
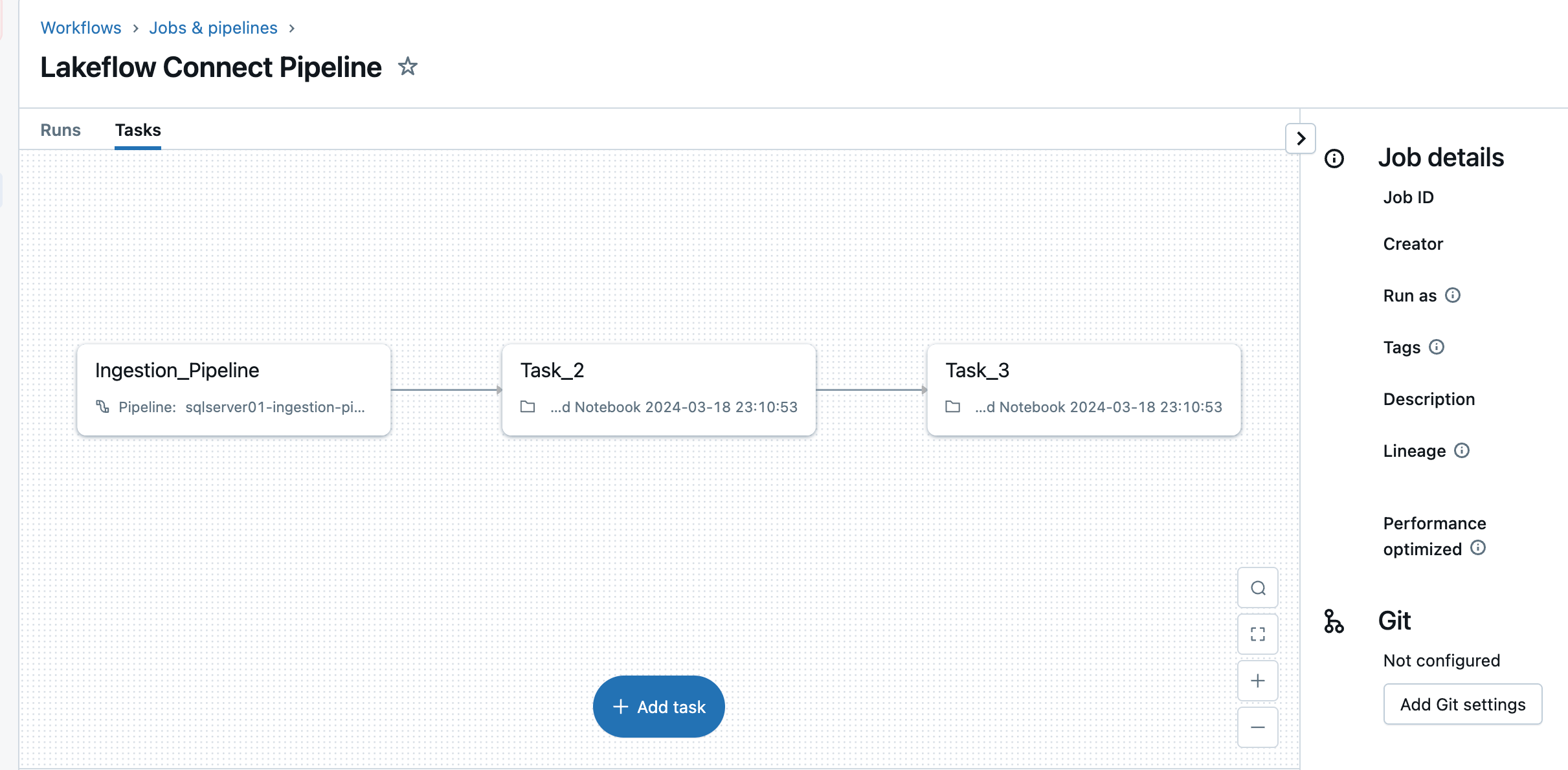
5. Configure schedules and notifications (AWS | Azure | GCP). This remaining step will assist decide how usually to run the pipeline and the place success or failure messages must be despatched. Set the pipeline to run each 6 hours and notify the person solely of pipeline failures. This interval might be configured to fulfill the wants of your workload.
The ingestion pipeline might be triggered on a customized schedule. Lakeflow Join will robotically create a devoted job for every scheduled pipeline set off. The ingestion pipeline is a job inside the job. Optionally, extra duties might be added earlier than or after the ingestion job for any downstream processing.
After this step, the ingestion pipeline is saved and triggered, beginning a full information load from the SQL Server into Databricks.
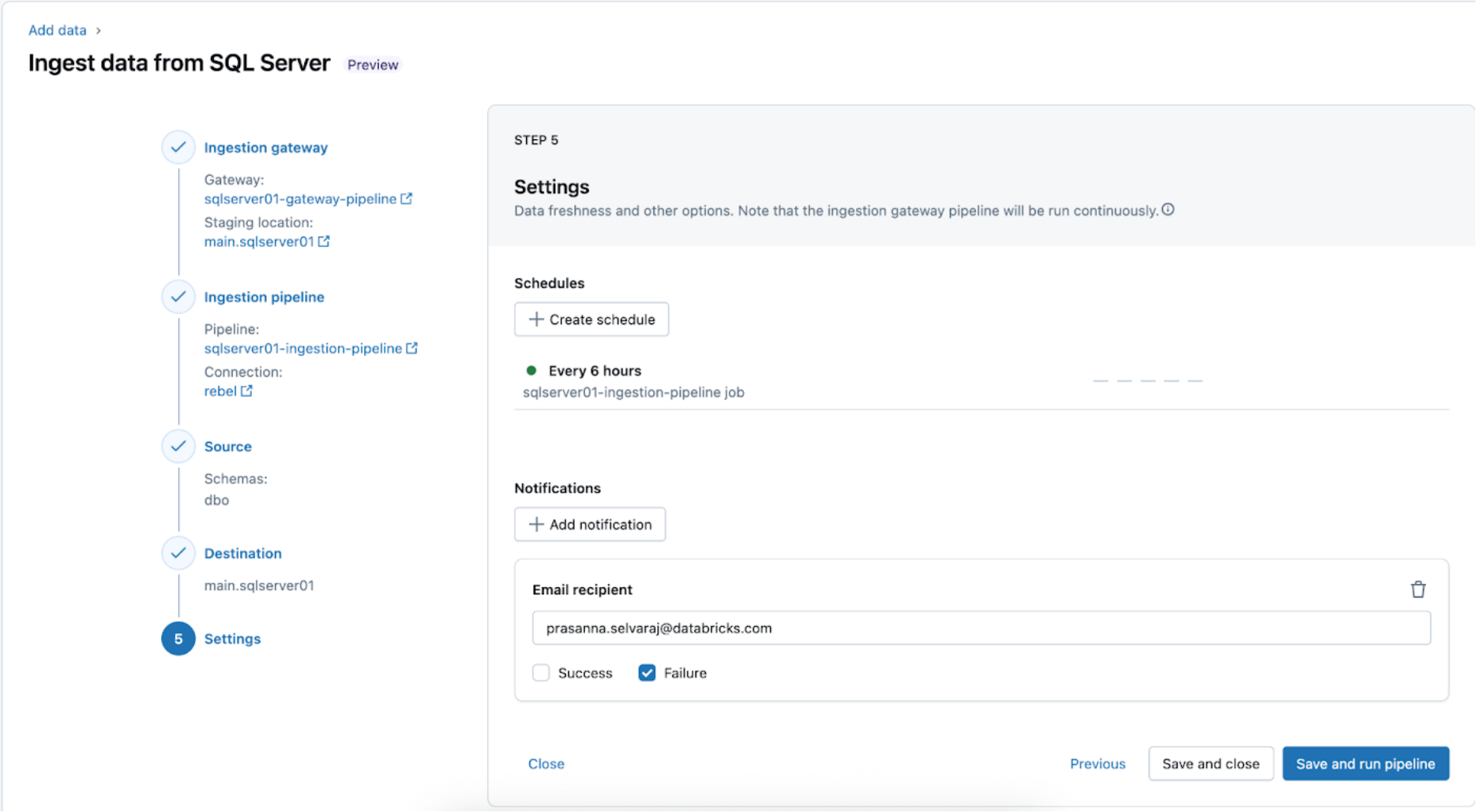
3. [Databricks] Validate Profitable Runs of the Gateway and Ingestion Pipelines
Navigate to the Pipeline menu to test if the gateway ingestion pipeline is operating. As soon as full, seek for ‘update_progress’ inside the pipeline occasion log interface on the backside pane to make sure the gateway efficiently ingests the supply information.
To test the sync standing, navigate to the pipeline menu. The screenshot beneath exhibits that the ingestion pipeline has carried out three insert and replace (UPSERT) operations.
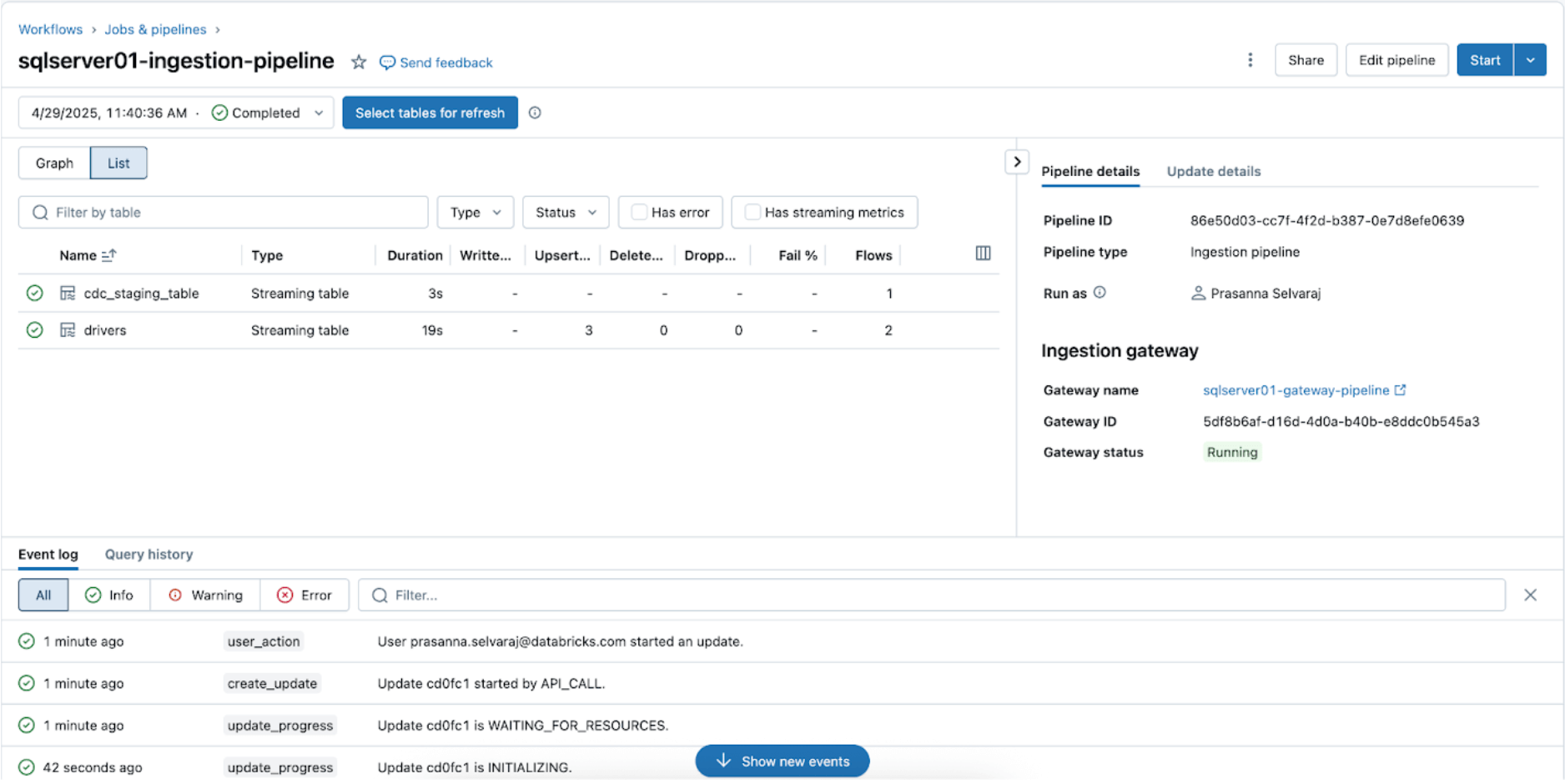
Navigate to the goal catalog, foremost, and schema, sqlserver01, to view the replicated desk, as proven beneath.
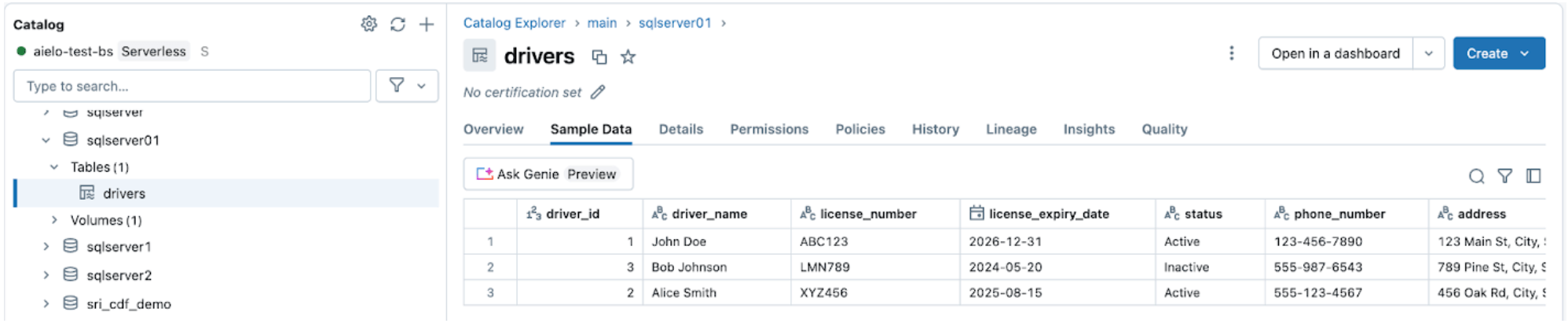
4. [Databricks] Check CDC and Schema Evolution
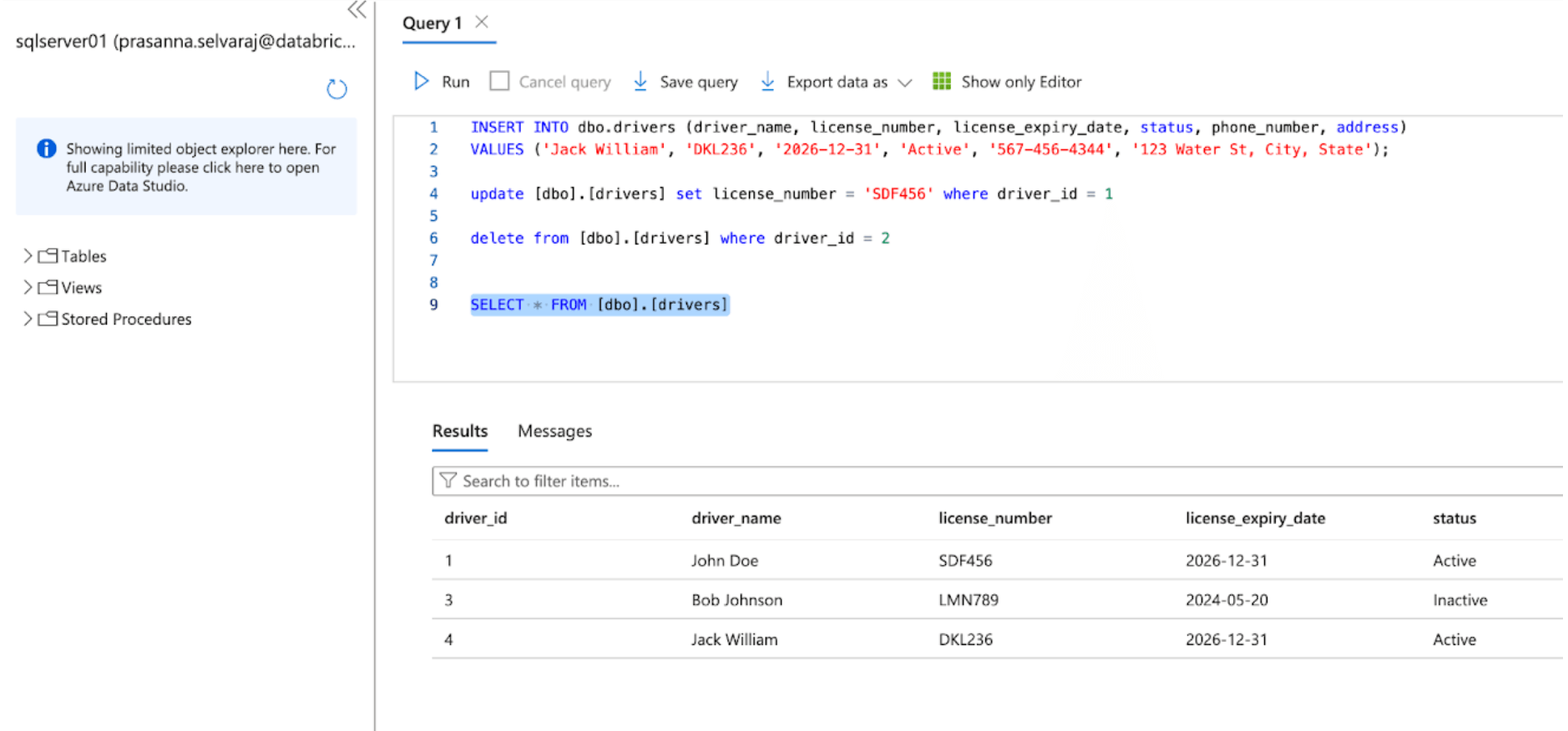
Subsequent, confirm a CDC occasion by performing insert, replace, and delete operations within the supply desk. The screenshot of the Azure SQL Server beneath depicts the three occasions.
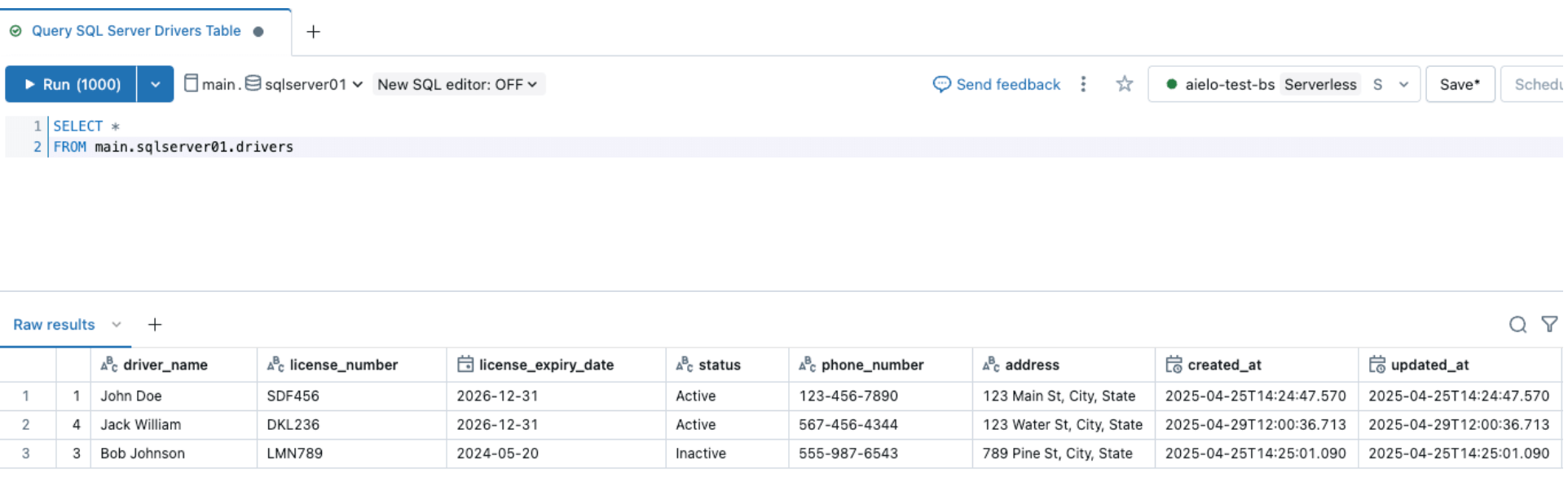
As soon as the pipeline is triggered and is accomplished, question the delta desk beneath the goal schema and confirm the modifications.
Equally, let’s carry out a schema evolution occasion and add a column to the SQL Server supply desk, as proven beneath
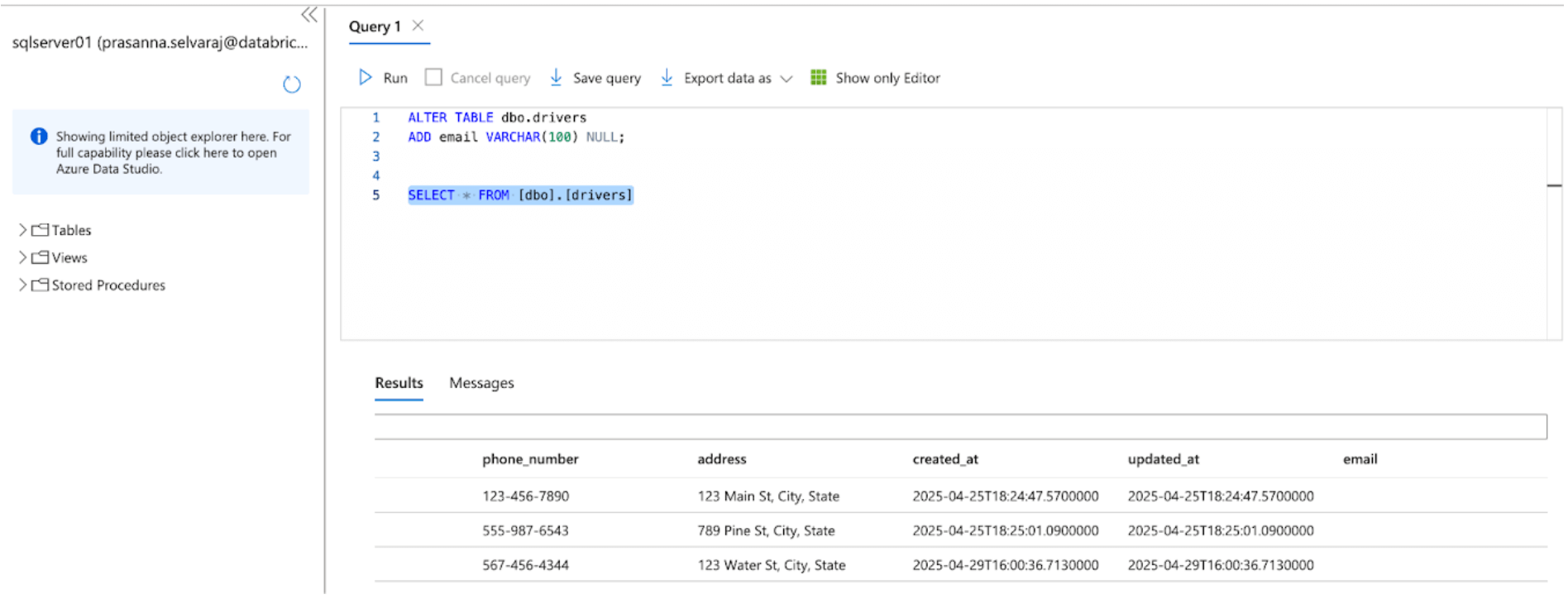
After altering the sources, set off the ingestion pipeline by clicking the beginning button inside the Databricks DLT UI. As soon as the pipeline has been accomplished, confirm the modifications by shopping the goal desk, as proven beneath. The brand new column e mail will probably be appended to the top of the drivers desk.
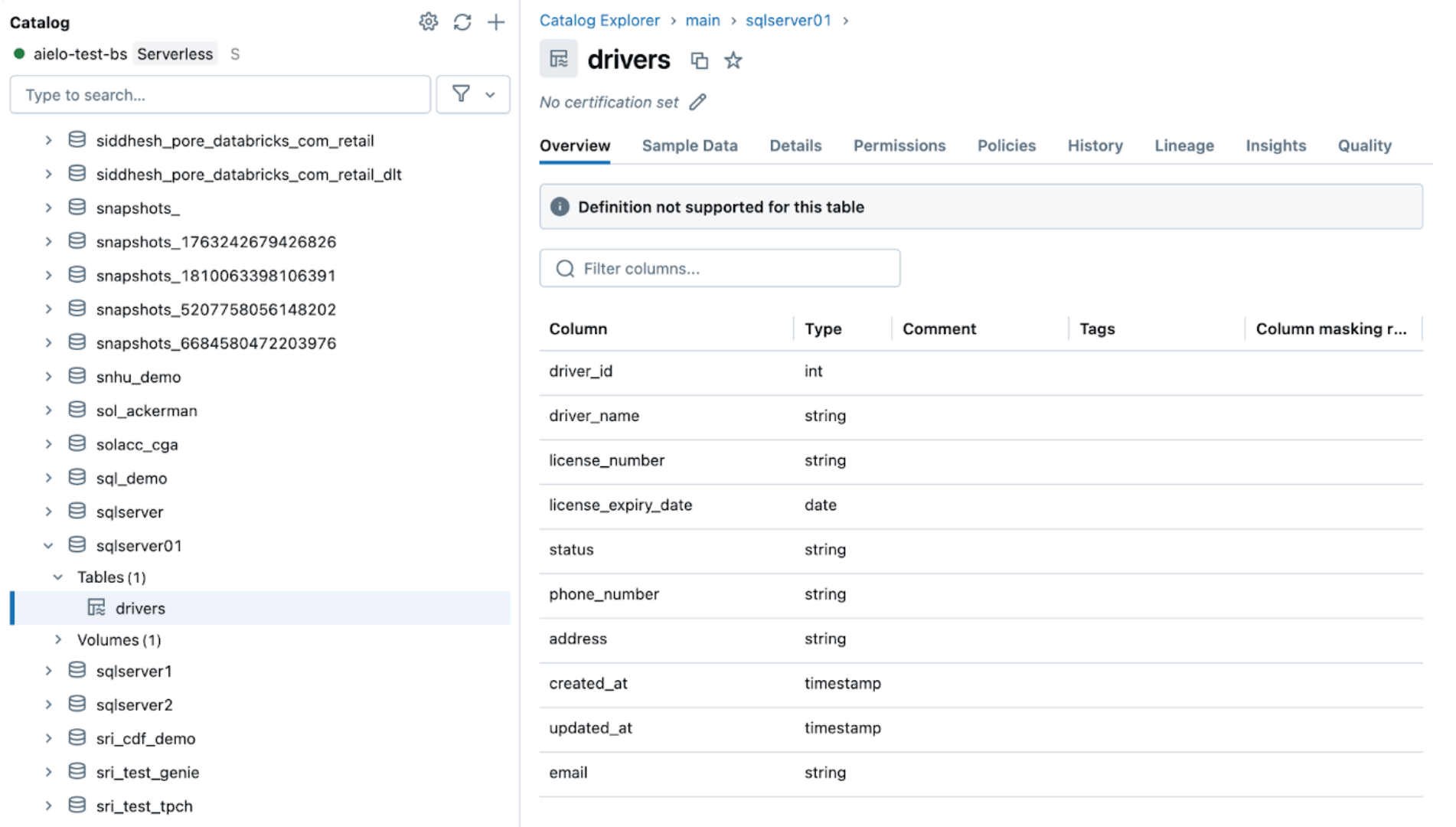
5. [Databricks] Steady Pipeline Monitoring
Monitoring their well being and conduct is essential as soon as the ingestion and gateway pipelines are efficiently operating. The pipeline UI offers information high quality checks, pipeline progress, and information lineage info. To view the occasion log entries within the pipeline UI, find the underside pane beneath the pipeline DAG, as proven beneath.
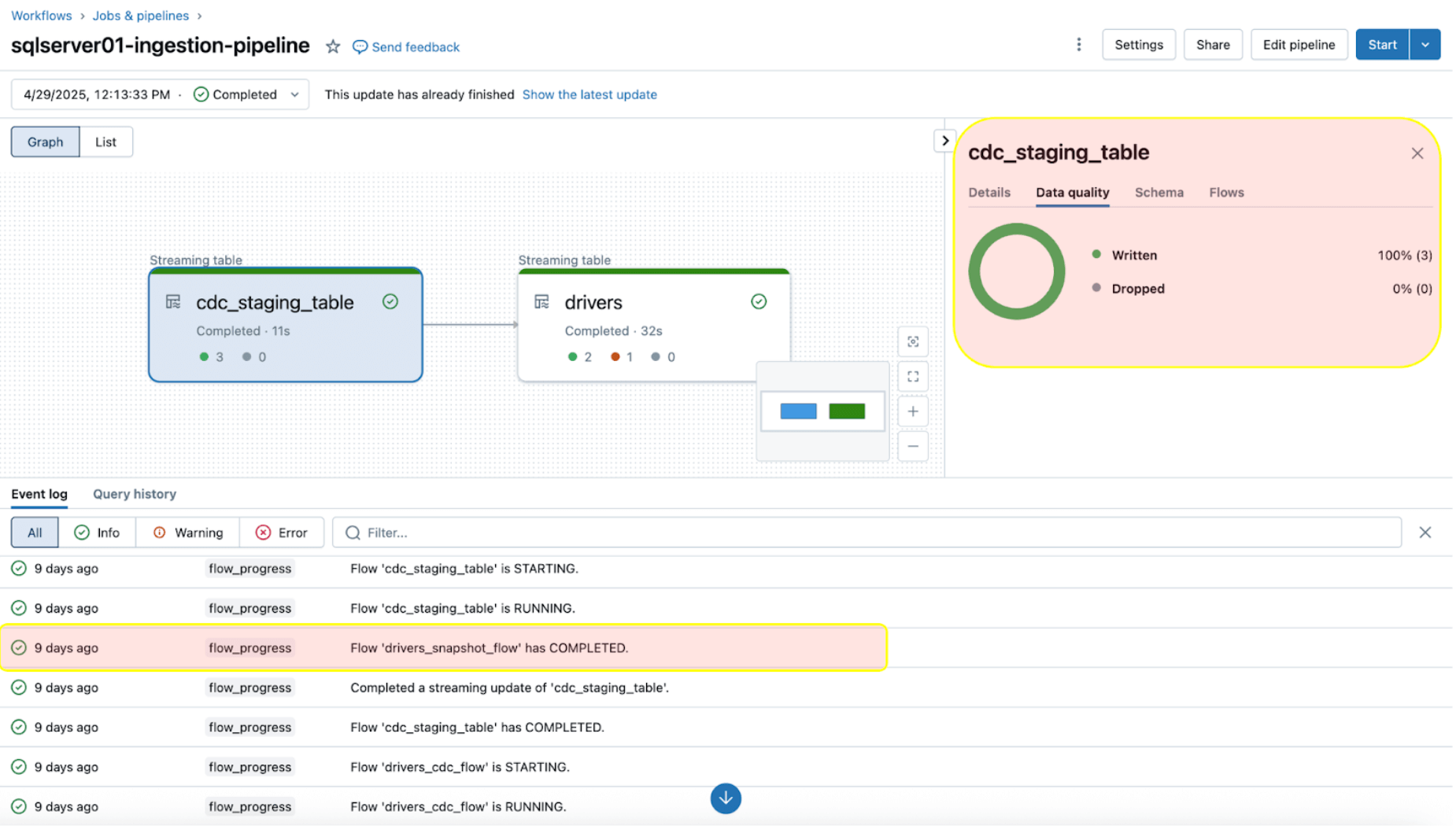
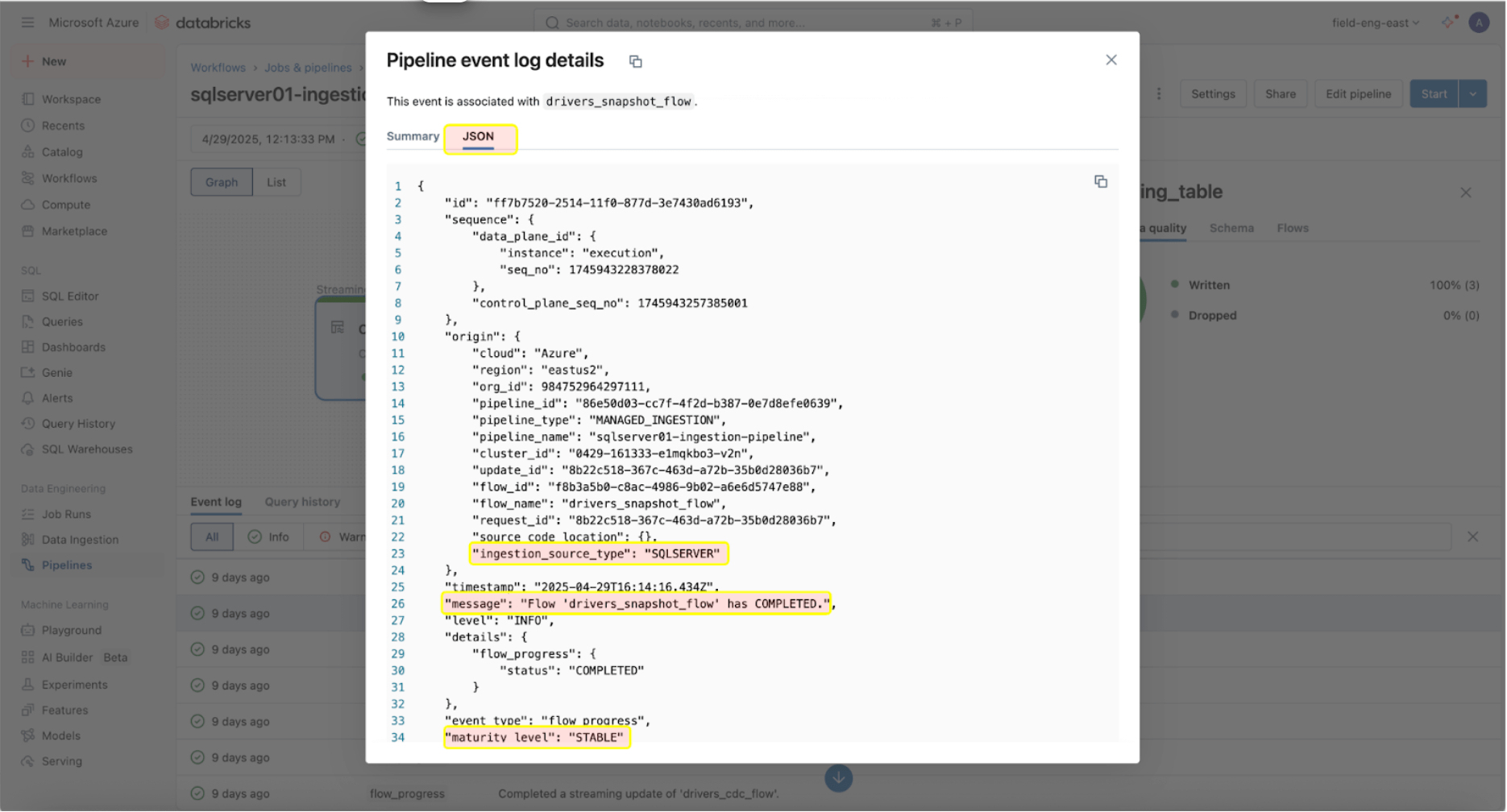
The occasion log entry above exhibits that the ‘drives_snapshot_flow’ was ingested from the SQL Server and accomplished. The maturity degree of STABLE signifies that the schema is secure and has not modified. Extra info on the occasion log schema might be discovered right here.
Actual-World Instance
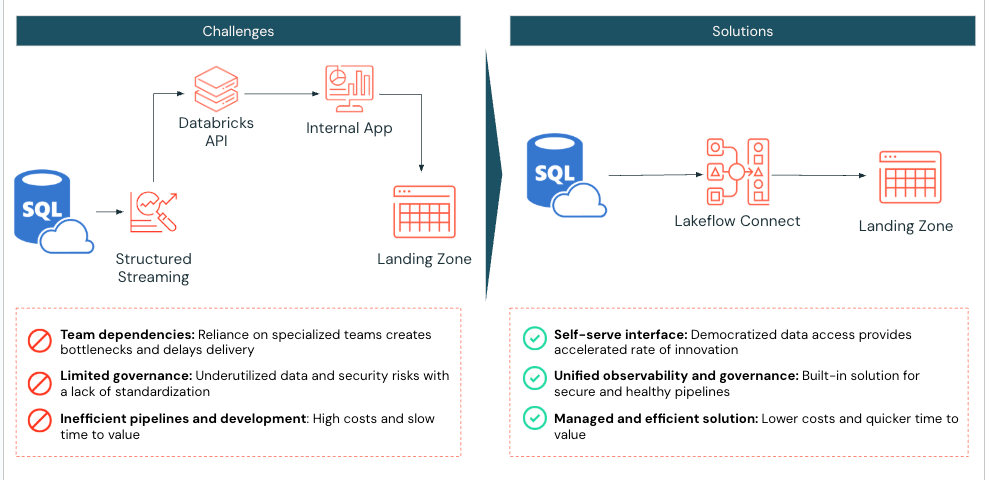
A big-scale medical diagnostic lab utilizing Databricks confronted challenges effectively ingesting SQL Server information into its lakehouse. Earlier than implementing Lakeflow Join, the lab used Databricks Spark notebooks to drag two tables from Azure SQL Server into Databricks. Their utility would then work together with the Databricks API to handle compute and job execution.
The medical diagnostic lab applied Lakeflow Join for SQL Server, recognizing that this course of might be simplified. As soon as enabled, the implementation was accomplished in simply sooner or later, permitting the medical diagnostic lab to leverage Databricks’ built-in instruments for observability with day by day incremental ingestion refreshes.
Operational Issues
As soon as the SQL Server connector has efficiently established a connection to your Azure SQL Database, the following step is to effectively schedule your information pipelines to optimize efficiency and useful resource utilization. As well as, it is important to comply with greatest practices for programmatic pipeline configuration to make sure scalability and consistency throughout environments.
Pipeline Orchestration
There isn’t a restrict on how usually the ingestion pipeline might be scheduled to run. Nevertheless, to attenuate prices and guarantee consistency in pipeline executions with out overlap, Databricks recommends at the very least a 5-minute interval between ingestion executions. This enables new information to be launched on the supply whereas accounting for computational assets and startup time.
The ingestion pipeline might be configured as a job inside a job. When downstream workloads depend on recent information arrival, job dependencies might be set to make sure the ingestion pipeline run completes earlier than executing downstream duties.
Moreover, suppose the pipeline continues to be operating when the following refresh is scheduled. In that case, the ingestion pipeline will behave equally to a job and skip the replace till the following scheduled one, assuming the at the moment operating replace completes on time.
Observability & Price Monitoring
Lakeflow Join operates on a compute-based pricing mannequin, making certain effectivity and scalability for numerous information integration wants. The ingestion pipeline operates on serverless compute, which permits for flexibility in scaling primarily based on demand and simplifies administration by eliminating the necessity for customers to configure and handle the underlying infrastructure.
Nevertheless, it is necessary to notice that whereas the ingestion pipeline can run on serverless compute, the ingestion gateway for database connectors at the moment operates on basic compute to simplify connections to the database supply. In consequence, customers would possibly see a mixture of basic and serverless DLT DBU expenses mirrored of their billing.
The best technique to observe and monitor Lakeflow Join utilization is thru system tables. Under is an instance question to view a selected Lakeflow Join pipeline’s utilization:

The official pricing for Lakeflow Join documentation (AWS | Azure | GCP) offers detailed fee info. Further prices, comparable to serverless egress charges (pricing), might apply. Egress prices from the Cloud supplier for traditional compute might be discovered right here (AWS | Azure | GCP).
Greatest Practices and Key Takeaways
As of Could 2025, beneath are among the greatest practices and issues to comply with when implementing this SQL Server connector:
- Configure every Ingestion Gateway to authenticate with a person or entity with entry solely to the replicated supply database.
- Make sure the person is given the required permissions to create connections in UC and ingest the info.
- Make the most of DABs to reliably configure Lakeflow Join ingestion pipelines, making certain repeatability and consistency in infrastructure administration.
- For supply tables with major keys, allow Change Monitoring to realize decrease overhead and improved efficiency.
- For supply tables with no major key, allow CDC as a result of its skill to seize modifications on the column degree, even with out distinctive row identifiers.
Lakeflow Join for SQL Server offers a completely managed, built-in integration for each on-premises and cloud databases for environment friendly, incremental ingestion into Databricks.
Subsequent Steps & Further Sources
Strive the SQL Server connector as we speak to assist clear up your information ingestion challenges. Comply with the steps outlined on this weblog or assessment the documentation. Study extra about Lakeflow Join on the product web page, view a product tour or view a demo of the Salesforce connector to assist predict buyer churn.
Databricks Supply Options Architects (DSAs) speed up Information and AI initiatives throughout organizations. They supply architectural management, optimize platforms for value and efficiency, improve developer expertise, and drive profitable challenge execution. DSAs bridge the hole between preliminary deployment and production-grade options, working carefully with numerous groups, together with information engineering, technical leads, executives, and different stakeholders to make sure tailor-made options and quicker time to worth. To learn from a customized execution plan, strategic steerage, and help all through your information and AI journey from a DSA, please contact your Databricks Account Staff.
Appendix
On this optionally available step, to handle the Lakeflow Join pipelines as code utilizing DABs, you merely want so as to add two information to your current bundle:
- A workflow file that controls the frequency of knowledge ingestion (assets/sqlserver.yml).
- A pipeline definition file (assets/sqlserver_pipeline.yml).
assets/sqlserver.yml:
assets/sqlserver_job.yml:

