
Multimodal Retrieval-Augmented Era (RAG) is a transformative innovation in AI, enabling methods to course of and combine various information varieties reminiscent of textual content, photos, audio, and video. This functionality is essential in addressing the problem of unstructured enterprise information, which predominantly consists of multimodal codecs. By leveraging multimodal inputs, RAG enhances contextual understanding, improves accuracy, and expands AI’s applicability throughout industries like healthcare, buyer assist, and schooling. Docling is an open-source toolkit developed by IBM to streamline doc processing for generative AI purposes. We are going to construct Multimodal RAG Capabilities Utilizing Docling.
It converts various codecs like PDFs, DOCX, and pictures into structured outputs reminiscent of JSON and Markdown, enabling seamless integration with AI frameworks like LangChain and LlamaIndex. By facilitating the extraction of unstructured information and supporting superior structure evaluation, Docling empowers multimodal Retrieval-Augmented Era (RAG) by making advanced enterprise information machine-readable and accessible for AI-driven insights
Studying Goals
- Exploring Docling – Understanding the way it extracts multimodal info from unstructured recordsdata.
- Docling Pipeline & AI Fashions – Analyzing its structure and key AI elements.
- Distinctive Options – Highlighting what makes Docling stand out.
- Constructing a Multimodal RAG System – Implementing a system utilizing Docling for information extraction and retrieval.
- Finish-to-Finish Course of – Extracting information from a PDF, producing picture descriptions, and querying with a vector DB & Phi 4.
This text was revealed as part of the Knowledge Science Blogathon.
Docling For Unstructured Knowledge
Docling is an open-source doc processing toolkit developed by IBM, designed to transform unstructured recordsdata like PDFs, DOCX, and pictures into structured codecs reminiscent of JSON and Markdown. Powered by superior AI fashions like DocLayNet for structure evaluation and TableFormer for desk recognition, it permits correct extraction of textual content, tables, and pictures whereas preserving doc construction. With seamless integration into generative AI frameworks like LangChain and LlamaIndex, Docling helps purposes reminiscent of Retrieval-Augmented Era (RAG) and question-answering methods. Its light-weight structure permits environment friendly efficiency on commonplace {hardware}, making it an economical various to SaaS-based options for enterprises looking for management over information privateness.
Docling Pipeline

Docling implements a linear pipeline of operations, which execute sequentially on every given doc (as proven within the above Determine). Every doc is first parsed by a PDF backend, which retrieves the programmatic textual content tokens, consisting of string content material and its coordinates on the web page, and in addition renders a bitmap picture of every web page to assist downstream operations. Then, the usual mannequin pipeline applies a sequence of AI fashions independently on each web page within the doc to extract options and content material, reminiscent of structure and desk constructions. Lastly, the outcomes from all pages are aggregated and handed via a post-processing stage, which augments metadata, detects the doc language, infers studying order and ultimately assembles a typed doc object which might be serialized to JSON or Markdown.
Key AI Fashions Behind Docling
Historically, builders have relied on optical character recognition (OCR) for changing paperwork into digital codecs. Nonetheless, this know-how might be gradual and susceptible to errors because of the heavy computational energy required. Docling avoids OCR each time doable, as a substitute utilizing laptop imaginative and prescient fashions which can be particularly educated to determine and categorize the visible elements of a web page.
Docling relies on two fashions developed by IBM researchers.
Format Evaluation Mannequin
The structure evaluation mannequin capabilities as an object detector, predicting the bounding bins and classes of varied parts inside a picture of a given web page. Its design relies on RT-DETR and has been re-trained utilizing DocLayNet, our well-known human-annotated dataset for doc structure evaluation, together with different proprietary datasets. DocLayNet is a human-annotated doc structure segmentation dataset containing 80863 pages from a broad number of doc sources.
This mannequin makes use of object detection methods to look at the structure of paperwork, starting from machine manuals to annual experiences. It then identifies and classifies parts reminiscent of blocks of textual content, photos, tables, captions, and extra. The Docling pipeline processes web page photos at a decision of 72 dpi, enabling them to be dealt with by a single CPU.
Desk Former Mannequin
The TableFormer mannequin, initially launched in 2022 and subsequently enhanced with a customized token construction language, is a vision-transformer mannequin designed for recovering the construction of tables. It will possibly predict the logical group of rows and columns in a desk based mostly on an enter picture, figuring out which cells belong to column headers, row headers, or the primary physique of the desk. Not like earlier strategies, TableFormer successfully handles numerous desk complexities, together with partial or absent borders, empty cells, lacking rows or columns, cell spans, hierarchical constructions in each column and row headings, in addition to inconsistencies in indentation or alignment.
Some Key Options of Docling
Listed here are the options:
- Versatile Format Assist: Docling can parse a variety of doc codecs, together with PDFs, DOCX, PPTX, HTML, photos, and extra. It exports content material into structured codecs like JSON and Markdown for seamless integration into AI workflows
- Superior PDF Processing: It contains refined capabilities reminiscent of structure evaluation, studying order detection, desk construction recognition, and OCR for scanned paperwork. This ensures the correct extraction of advanced doc parts like tables and figures. Docling extracts tables utilizing superior AI-driven strategies, primarily leveraging its customized TableFormer mannequin.
- Unified Doc Illustration: Docling makes use of a unified and expressive format to signify parsed paperwork, making it simpler to course of and analyze them in downstream purposes
- AI-Prepared Integration: The toolkit integrates seamlessly with fashionable AI frameworks like LangChain and LlamaIndex, making it excellent for purposes like Retrieval-Augmented Era (RAG) and question-answering methods
- Native Execution: It helps native execution, enabling safe processing of delicate information in air-gapped environments
- Environment friendly Efficiency: Designed to run on commodity {hardware} with minimal useful resource necessities, Docling avoids conventional OCR when doable, rushing up processing by as much as 30 instances whereas decreasing errors.
- Modular Structure: Its modular design permits straightforward customization and extension with new options or fashions, catering to various use instances
- Open-Supply Accessibility: Not like proprietary instruments like Watson Doc Understanding, Docling is open-source below the MIT license, permitting builders to freely use, customise, and combine it into their workflows with out vendor lock-in or further prices
Docling offers non-obligatory assist for OCR, for instance, to cowl scanned PDFs or content material in
bitmap photos embedded on a web page. Docling depends on EasyOCR, a well-liked third-party OCR library with assist for a lot of languages. These options make Docling a complete resolution for doc parsing and preparation in generative AI workflows.
Constructing a Multimodal RAG System utilizing Docling
On this article, we’ll first extract all types of knowledge – textual content, photos, and tables from a PDF utilizing Docling. For extracted photos, we’ll use a imaginative and prescient language mannequin to generate the outline of the pictures and save these textual content descriptions of the pictures in our VectorDB together with the textual content information from the unique textual content contents and textual content from extracted Tables within the PDF. Put up this, we’ll construct a RAG system utilizing the vector DB for retrieval together with an LLM (Phi 4) via Ollama for querying from the PDF doc.
Palms-On Python Implementation on Google Colab utilizing T4 GPU (Free Tier)
You could find the Colab Pocket book which has all of the steps right here.
Step 1. Putting in Libraries
We first begin with putting in the mandatory libraries
!pip set up docling
#Following code added to keep away from an error in set up - might be eliminated if not wanted
import locale
def getpreferredencoding(do_setlocale = True):
return "UTF-8"
locale.getpreferredencoding = getpreferredencoding
!pip set up langchain-huggingfaceStep 2. Loading the Converter Object
This code prepares a doc converter to course of PDF recordsdata with out OCR however with picture era. It then applies this conversion to a specified PDF file, storing the leads to a dictionary.
We use this PDF (we put it aside within the present working listing as ‘accenture.pdf’) which has loads of charts to check the multimodal retrieval utilizing Docling.
from docling.document_converter import DocumentConverter, PdfFormatOption
from docling.datamodel.base_models import InputFormat
from docling.datamodel.pipeline_options import PdfPipelineOptions
pdf_pipeline_options = PdfPipelineOptions(do_ocr=False,generate_picture_images=True,)
format_options = {InputFormat.PDF: PdfFormatOption(pipeline_options=pdf_pipeline_options)}
converter = DocumentConverter(format_options=format_options)
sources = [ "/content/accenture.pdf",]
conversions = {supply: converter.convert(supply=supply).doc for supply in sources}Step 3. Loading the Mannequin For Embedding Textual content
from langchain_huggingface.embeddings import HuggingFaceEmbeddings
from transformers import *
embeddings_model_path = "ibm-granite/granite-embedding-30m-english"
embeddings_model = HuggingFaceEmbeddings(model_name=embeddings_model_path,)
embeddings_tokenizer = AutoTokenizer.from_pretrained(embeddings_model_path)Step 4. Chunking the Texts within the Doc
The code beneath is for the doc processing pipeline. It takes transformed paperwork from the earlier step and breaks them down into smaller chunks, excluding tables (which is processed individually later). Every chunk is then wrapped right into a Doc object with particular metadata. The code processes transformed paperwork by splitting them into chunks, skipping tables, and creating new Doc objects with metadata for every chunk.
from docling_core.transforms.chunker.hybrid_chunker import HybridChunker
from docling_core.varieties.doc.doc import TableItem
from langchain_core.paperwork import Doc
doc_id = 0
texts: record[Document] = []
for supply, docling_document in conversions.objects():
for chunk in HybridChunker(tokenizer=embeddings_tokenizer).chunk(docling_document):
objects = chunk.meta.doc_items
if len(objects) == 1 and isinstance(objects[0], TableItem):
proceed # we'll course of tables later
refs = " ".be part of(map(lambda merchandise: merchandise.get_ref().cref, objects))
textual content = chunk.textual content
doc = Doc(page_content=textual content,metadata={"doc_id": (doc_id:=doc_id+1),"supply": supply,"ref": refs,},)
texts.append(doc)
print(f"{len(texts)} textual content doc chunks created")Step 5. Processing the Tables within the Doc
The code beneath is designed to course of tables from transformed paperwork. It extracts tables, converts them into Markdown format, and wraps every desk right into a Doc object with particular metadata.
from docling_core.varieties.doc.labels import DocItemLabel
doc_id = len(texts)
tables: record[Document] = []
for supply, docling_document in conversions.objects():
for desk in docling_document.tables:
if desk.label in [DocItemLabel.TABLE]:
ref = desk.get_ref().cref
textual content = desk.export_to_markdown()
doc = Doc(
page_content=textual content,
metadata={
"doc_id": (doc_id:=doc_id+1),
"supply": supply,
"ref": ref
},
)
tables.append(doc)
print(f"{len(tables)} desk paperwork created")Step 6. Defining Perform For Changing Photographs From PDF to base64 kind
import base64
import io
import PIL.Picture
import PIL.ImageOps
from IPython.show import show
def encode_image(picture: PIL.Picture.Picture, format: str = "png") -> str:
picture = PIL.ImageOps.exif_transpose(picture) or picture
picture = picture.convert("RGB")
buffer = io.BytesIO()
picture.save(buffer, format)
encoding = base64.b64encode(buffer.getvalue()).decode("utf-8")
return encodingStep 7. Pulling Mannequin From Ollama For Analysing Photographs from the PDF
We are going to use a imaginative and prescient language mannequin from Ollama to analyse the extracted photos from the PDF and generate an outline for every of the pictures. To facilitate using Ollama fashions, we set up the next libraries and begin up the Ollama server earlier than pulling the mannequin as described beneath within the code.
!sudo apt replace
!sudo apt set up -y pciutils
!pip set up langchain-ollama
!curl -fsSL https://ollama.com/set up.sh | sh
!pip set up ollama==0.4.2
!pip set up langchain-community
#Enabling threading to start out ollama server in a non blocking method
import threading
import subprocess
import time
def run_ollama_serve():
subprocess.Popen(["ollama", "serve"])
thread = threading.Thread(goal=run_ollama_serve)
thread.begin()
time.sleep(5)The code beneath is designed to course of photos from transformed paperwork. It extracts photos, makes use of a imaginative and prescient mannequin (llama3.2-vision via Ollama) to generate descriptive textual content for every picture, and wraps this textual content into a Doc object with particular metadata. Right here’s an in depth clarification:
Pulling the “llama3.2-vision” mannequin from Ollama.
!ollama pull llama3.2-visiondef encode_image(picture: PIL.Picture.Picture, format: str = "png") -> str:
picture = PIL.ImageOps.exif_transpose(picture) or picture
picture = picture.convert("RGB")
buffer = io.BytesIO()
picture.save(buffer, format)
encoding = base64.b64encode(buffer.getvalue()).decode("utf-8")
return encodingimport ollama
photos: record[Document] = []
doc_id = len(texts) + len(tables)
for supply, docling_document in conversions.objects():
for image in docling_document.photos:
ref = image.get_ref().cref
picture = image.get_image(docling_document)
if picture:
print(picture)
response = ollama.chat(
mannequin="llama3.2-vision",
messages=[{
"role": "user",
"content": "Describe this image?",
"images": [encode_image(image)]
}],
)
textual content = response['message']['content'].strip()
doc = Doc(
page_content=textual content,
metadata={
"doc_id": (doc_id:=doc_id+1),
"supply": supply,
"ref": ref,
},
)
photos.append(doc)
print(f"{len(photos)} picture descriptions created")
import itertools
from docling_core.varieties.doc.doc import RefItem
# Print all created paperwork
for doc in itertools.chain(texts, tables):
print(f"Doc ID: {doc.metadata['doc_id']}")
print(f"Supply: {doc.metadata['source']}")
print(f"Content material:n{doc.page_content}")
print("=" * 80) # Separator for readability
for doc in photos:
print(f"Doc ID: {doc.metadata['doc_id']}")
supply = doc.metadata['source']
print(f"Supply: {supply}")
print(f"Content material:n{doc.page_content}")
docling_document = conversions[source]
ref = doc.metadata['ref']
image = RefItem(cref=ref).resolve(docling_document)
picture = image.get_image(docling_document)
print("Picture:")
show(picture)
print("=" * 80) # Separator for readability
Step 9. Storing in Milvus Vector DB
Milvus is a high-performance vector database constructed for scale. It powers AI purposes by effectively organizing and looking huge quantities of unstructured information, reminiscent of textual content, photos, and multi-modal info. We set up the langchain-milvus library first after which retailer the texts, tables and photos within the vector DB. Whereas defining the vector DB, we additionally go the embedding mannequin in order that the vector DB converts all of the textual content extracted, together with the information from tables and picture descriptions, into embeddings earlier than storing them.
!pip set up langchain_milvus
import tempfile
from langchain_core.vectorstores import VectorStore
from langchain_milvus import Milvus
db_file = tempfile.NamedTemporaryFile(prefix="vectorstore_", suffix=".db", delete=False).title
vector_db: VectorStore = Milvus(embedding_function=embeddings_model,connection_args={"uri": db_file},auto_id=True,enable_dynamic_field=True,index_params={"index_type": "AUTOINDEX"},)
#add all of the LangChain paperwork for the textual content, tables and picture descriptions to the vector database
import itertools
paperwork = record(itertools.chain(texts, tables, photos))
ids = vector_db.add_documents(paperwork)
print(f"{len(ids)} paperwork added to the vector database")Step 10. Querying the mannequin utilizing Retrieval Augmented Era with Phi 4 mannequin
Within the following code, we first pull the “Phi 4” mannequin from Ollama after which use it because the LLM on this RAG system for producing a response submit retrieval of the related context from the vector DB based mostly on a question.
#Pulling the Ollama mannequin for querying
!ollama pull phi4
#Querying
from langchain_core.output_parsers import StrOutputParser
from langchain.prompts import ChatPromptTemplate
from langchain_community.chat_models import ChatOllama
from langchain_core.runnables import RunnableLambda, RunnablePassthrough
retriever = vector_db.as_retriever()
# Immediate
template = """Reply the query based mostly solely on the next context:
{context}
Query: {query}
"""
immediate = ChatPromptTemplate.from_template(template)
# Native LLM
ollama_llm = "phi4"
model_local = ChatOllama(mannequin=ollama_llm)
# Chain
chain = (
{"context": retriever, "query": RunnablePassthrough()}
| immediate
| model_local
| StrOutputParser()
)
chain.invoke("How a lot price in {dollars} is Technique & Conslution in Providers?")
Output
In accordance with the context supplied, the 'Expertise & Technique/Consulting'
part of the corporate's operations generated a price of $15 billion.
As seen from the chart beneath from the doc, the response of our multimodal RAG system is right. With Docling, the data was accurately extracted from the chart and therefore the retrieval system was in a position to present us with an correct response.

Analyzing Our RAG System with Extra Queries
What was the income in Germany?
The income in Germany, in accordance with the supplied context, is $3 billion.
This info is listed below the 'Nation-Sensible Income' part of the
doc: nn. **Germany**: $3 billionnnIf you want any additional particulars
or have further questions, be at liberty to ask!
As seen from the chart beneath from the doc, the response of our multimodal RAG system is right. With Docling, the data was accurately extracted from the chart and therefore the retrieval system was in a position to present us with an correct response.

What was the Cloud FY19 income?
The Cloud FY19 income, as supplied within the doc context, was $11 billion.
This info is discovered within the first desk below the part titled
'Cloud' the place it states:nnFY19: $11BnnThis signifies that the income
from cloud providers for fiscal 12 months 2019 was $11 billion.
As seen from the Desk beneath from the doc, the response of our multimodal RAG system is right. With Docling, the data was accurately extracted from the chart and therefore the retrieval system was in a position to present us with an correct response.
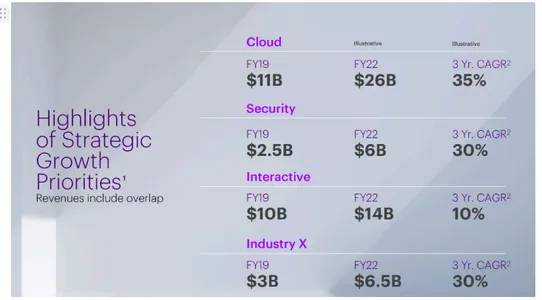
What was the Trade X 3 Yr CAGR?
Based mostly on the supplied context from the paperwork in Accenture’s PDF:nn-In
Doc withdoc_id15 and Doc withdoc_id3, each point out Trade
X.n-The related info is discovered below a piece about income development
for Trade X:nn**Doc 15** signifies: "FY19 $10B Trade X FY19 $3B
FY22 $6.5B 3 Yr. CAGR 2 30%"nn**Doc 3** reiterates this with related
wording: "Cloud = FY19 $10B Trade X FY19. , Illustrative = . , Cloud =
$3B. , Illustrative = FY22 $6.5B. , Illustrative = 3 Yr. CAGR 2 30%"nnFrom
these excerpts, the 3-year compound annual development fee (CAGR) for Trade X
is **30%."**.nn
As seen from the earlier Desk from the doc, the response of our multimodal RAG system is right. With Docling, the data was accurately extracted from the chart and therefore the retrieval system was in a position to present us with an correct response
Conclusion
In conclusion, Docling stands as a robust device for remodeling unstructured information into machine-readable codecs, making it a necessary useful resource for purposes like Multimodal Retrieval-Augmented Era (RAG). By using superior AI fashions and providing seamless integration with fashionable AI frameworks, Docling enhances the power to course of and question advanced paperwork effectively. Its open-source nature, mixed with versatile format assist and modular structure, makes it a perfect resolution for enterprises looking for to leverage generative AI in real-world use instances.
Key Takeaways
- Docling Toolkit: IBM’s open-source device for extracting structured information (JSON, Markdown) from PDFs, DOCX, and pictures, enabling seamless AI integration.
- Superior AI Fashions: Makes use of Format Evaluation and TableFormer for correct doc processing, decreasing reliance on conventional OCR.
- AI Framework Integration: Works with LangChain and LlamaIndex, excellent for RAG methods, providing cost-effective AI-driven insights.
- Open-Supply & Customizable: MIT-licensed, modular, and adaptable for various use instances, free from vendor lock-in.
The media proven on this article is just not owned by Analytics Vidhya and is used on the Writer’s discretion.
Regularly Requested Questions
Ans. RAG is an AI framework that integrates numerous information varieties, reminiscent of textual content, photos, audio, and video, to enhance contextual understanding and accuracy. By processing multimodal inputs, RAG permits AI methods to generate extra correct insights and prolong their applicability throughout industries like healthcare, schooling, and buyer assist.
Ans. Docling is an open-source doc processing toolkit developed by IBM. It converts unstructured paperwork (e.g., PDFs, DOCX, photos) into structured codecs reminiscent of JSON and Markdown. This conversion permits seamless integration with generative AI frameworks like LangChain and LlamaIndex, facilitating purposes like RAG and question-answering methods.
Ans. Docling makes use of superior AI fashions like Format Evaluation for detecting doc structure parts and TableFormer for recognizing desk constructions. These fashions assist extract textual content, tables, and pictures whereas preserving the doc’s construction, enhancing accuracy and making advanced information machine-readable for AI methods.
Ans. Sure, Docling is designed to combine seamlessly with fashionable AI frameworks like LangChain and LlamaIndex. It may be used to energy purposes like Retrieval-Augmented Era (RAG) by extracting information from unstructured paperwork and enabling AI methods to question and retrieve related info.
Ans. Docling is an economical various to SaaS-based doc processing instruments. It permits native execution, making it excellent for enterprises that must course of delicate information in air-gapped environments, guaranteeing information privateness whereas providing environment friendly efficiency on commonplace {hardware}. Moreover, Docling is open-source below the MIT license, permitting for straightforward customization with out vendor lock-in.
Nibedita accomplished her grasp’s in Chemical Engineering from IIT Kharagpur in 2014 and is at present working as a Senior Knowledge Scientist. In her present capability, she works on constructing clever ML-based options to enhance enterprise processes.
Login to proceed studying and revel in expert-curated content material.

