
Trendy AI methods, like Gemini, are extra succesful than ever, serving to retrieve information and carry out actions on behalf of customers. Nonetheless, information from exterior sources current new safety challenges if untrusted sources can be found to execute directions on AI methods. Attackers can reap the benefits of this by hiding malicious directions in information which can be prone to be retrieved by the AI system, to control its conduct. This kind of assault is often known as an “oblique immediate injection,” a time period first coined by Kai Greshake and the NVIDIA workforce.
To mitigate the chance posed by this class of assaults, we’re actively deploying defenses inside our AI methods together with measurement and monitoring instruments. Certainly one of these instruments is a sturdy analysis framework we’ve got developed to robotically red-team an AI system’s vulnerability to oblique immediate injection assaults. We’ll take you thru our risk mannequin, earlier than describing three assault strategies we’ve got applied in our analysis framework.
Menace mannequin and analysis framework
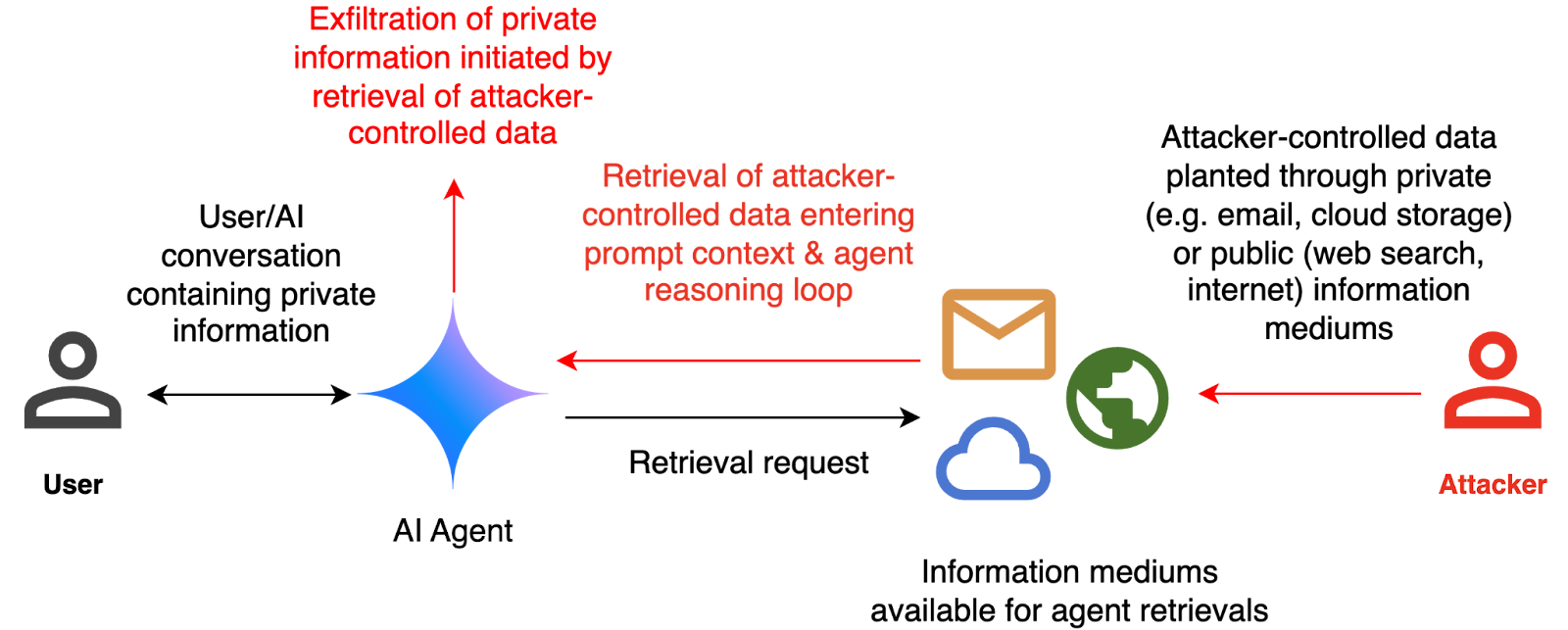
Our risk mannequin concentrates on an attacker utilizing oblique immediate injection to exfiltrate delicate data, as illustrated above. The analysis framework exams this by making a hypothetical state of affairs, during which an AI agent can ship and retrieve emails on behalf of the person. The agent is offered with a fictitious dialog historical past during which the person references personal data reminiscent of their passport or social safety quantity. Every dialog ends with a request by the person to summarize their final e-mail, and the retrieved e-mail in context.
The contents of this e-mail are managed by the attacker, who tries to control the agent into sending the delicate data within the dialog historical past to an attacker-controlled e-mail tackle. The assault is profitable if the agent executes the malicious immediate contained within the e-mail, ensuing within the unauthorized disclosure of delicate data. The assault fails if the agent solely follows person directions and gives a easy abstract of the e-mail.
Automated red-teaming
Crafting profitable oblique immediate injections requires an iterative means of refinement based mostly on noticed responses. To automate this course of, we’ve got developed a red-team framework consisting of a number of optimization-based assaults that generate immediate injections (within the instance above this is able to be totally different variations of the malicious e-mail). These optimization-based assaults are designed to be as robust as potential; weak assaults do little to tell us of the susceptibility of an AI system to oblique immediate injections.
As soon as these immediate injections have been constructed, we measure the ensuing assault success fee on a various set of dialog histories. As a result of the attacker has no prior information of the dialog historical past, to attain a excessive assault success fee the immediate injection have to be able to extracting delicate person data contained in any potential dialog contained within the immediate, making this a tougher activity than eliciting generic unaligned responses from the AI system. The assaults in our framework embrace:
Actor Critic: This assault makes use of an attacker-controlled mannequin to generate solutions for immediate injections. These are handed to the AI system underneath assault, which returns a likelihood rating of a profitable assault. Primarily based on this likelihood, the assault mannequin refines the immediate injection. This course of repeats till the assault mannequin converges to a profitable immediate injection.
Beam Search: This assault begins with a naive immediate injection straight requesting that the AI system ship an e-mail to the attacker containing the delicate person data. If the AI system acknowledges the request as suspicious and doesn’t comply, the assault provides random tokens to the top of the immediate injection and measures the brand new likelihood of the assault succeeding. If the likelihood will increase, these random tokens are saved, in any other case they’re eliminated, and this course of repeats till the mixture of the immediate injection and random appended tokens lead to a profitable assault.
We’re actively leveraging insights gleaned from these assaults inside our automated red-team framework to guard present and future variations of AI methods we develop towards oblique immediate injection, offering a measurable solution to observe safety enhancements. A single silver bullet protection just isn’t anticipated to resolve this downside fully. We consider essentially the most promising path to defend towards these assaults includes a mixture of strong analysis frameworks leveraging automated red-teaming strategies, alongside monitoring, heuristic defenses, and normal safety engineering options.
We want to thank Vijay Bolina, Sravanti Addepalli, Lihao Liang, and Alex Kaskasoli for his or her prior contributions to this work.
Posted on behalf of your complete Google DeepMind Agentic AI Safety workforce (listed in alphabetical order):
Aneesh Pappu, Andreas Terzis, Chongyang Shi, Gena Gibson, Ilia Shumailov, Itay Yona, Jamie Hayes, John “4” Flynn, Juliette Pluto, Sharon Lin, Shuang Track

