

To get your net pages ranked on search engine consequence pages (SERPs), they first have to be crawled and listed by engines like google like Google. Nevertheless, Google has restricted sources and might’t index each web page on the web. That is the place the idea of crawl funds is available in.
Crawl funds is the period of time and sources that Google allocates to crawling and indexing your web site. Sadly, this crawl funds doesn’t need to match the dimensions of your web site. And you probably have a big web site, this will trigger necessary content material to be missed by Google.
The excellent news is that there are methods to extend the crawl funds obtainable to your web site, which we’ll cowl on this article. And we may also present you the right way to effectively use your current crawl funds to be sure that Google can simply discover and crawl your most necessary content material.
However earlier than we dive in, we’ll begin with a fast introduction to how precisely crawl funds works and what kinds of web sites must optimize their crawl funds.
If you wish to skip the speculation, you may leap proper into crawl funds optimization strategies right here!
What’s crawl funds?
As talked about above, crawl funds refers back to the period of time and sources Google invests into crawling your web site.
This crawl funds isn’t static although. In line with Google Search Central, it’s decided by two important elements: crawl price and crawl demand.
Crawl price
The crawl price describes what number of connections Googlebot can use concurrently to crawl your web site.
This quantity can fluctuate relying on how briskly your server responds to Google’s requests. You probably have a strong server that may deal with Google’s web page requests effectively, Google can improve its crawl price and crawl extra pages of your web site directly.
Nevertheless, in case your web site takes a very long time to ship the requested content material, Google will decelerate its crawl price to keep away from overloading your server and inflicting a poor consumer expertise for guests looking your website. Consequently, a few of your pages is probably not crawled or could also be deprioritized.
Crawl demand
Whereas crawl price refers to what number of pages of your website Google can crawl, crawl demand displays how a lot time Google desires to spend crawling your web site. Crawl demand is elevated by:
- Content material high quality: Recent, helpful content material that resonates with customers.
- Web site reputation: Excessive site visitors and highly effective backlinks point out a robust website authority and significance.
- Content material updates: Often updating content material means that your website is dynamic, which inspires Google to crawl it extra steadily.
Subsequently, based mostly on crawl price and crawl demand, we are able to say that crawl funds represents the variety of URLs Googlebot can crawl (technically) and needs to crawl (content-wise) in your website.
How does crawl funds have an effect on rankings and indexing?
For a web page to point out up on search outcomes, it must be crawled and listed. Throughout crawling, Google analyzes content material and different necessary components (meta knowledge, structured knowledge, hyperlinks, and so on.) to grasp the web page. This info is then used for indexing and rating.
When your crawl funds hits zero, engines like google like Google can not crawl your pages utterly. This implies it takes longer in your pages to be processed and added to the search index. Consequently, your content material received’t seem on search engine outcomes pages as rapidly because it ought to. This delay can stop customers from discovering your content material once they search on-line. Within the worst-case situation, Google would possibly by no means uncover a few of your high-quality pages.
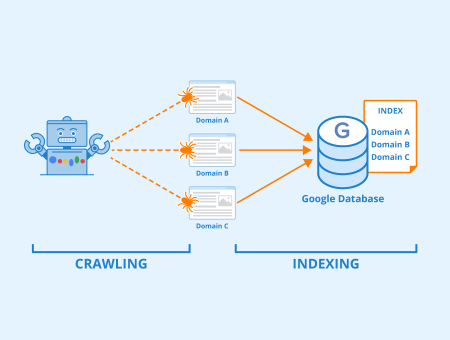
Determine: Indexing – Creator: Seobility – License: CC BY-SA 4.0
A depleted crawl funds may result in ‘lacking content material.’ This happens when Google solely partially crawls or indexes your net web page, leading to lacking textual content, hyperlinks, or photos. Since Google didn’t absolutely crawl your web page, it could interpret your content material otherwise than supposed, doubtlessly harming your rating.
It’s necessary to say although that crawl funds is not a rating issue. It solely impacts the standard of crawling and the time it takes to index and rank your pages on the SERPs.
What kinds of web sites ought to optimize their crawl funds?
Of their Google Search Central information, Google mentions that crawl funds points are most related to those use circumstances:
- Web site with numerous pages (1 million+ pages) which might be up to date repeatedly
- Web sites with a medium to giant variety of pages (10,000+ pages) which might be up to date very steadily (each day)
- Web sites with a excessive proportion of pages which might be listed as Found – presently not listed in Google Search Console, indicating inefficient crawling*
*Tip: Seobility may also let you realize if there’s a big discrepancy between pages which might be being crawled and pages which might be really appropriate to be listed, i.e. if there’s a big proportion of pages which might be losing your web site’s crawl funds. On this case, Seobility will show a warning in your Tech. & Meta dashboard:
Solely X pages that may be listed by engines like google have been discovered.
In case your web site doesn’t fall into one among these classes, a depleted crawl funds shouldn’t be a serious concern.
The one exception is that if your website hosts a whole lot of JavaScript-based pages. On this case you should still need to contemplate optimizing your crawl funds spending, as processing JS pages could be very resource-intensive.
Why does JavaScript crawling simply deplete a web site’s crawl funds?
When Google indexes easy HTML pages, it requires two steps: crawl and index. Nevertheless, for indexing dynamic JavaScript-based content material, Google wants three steps: crawl, render, and index. This may be considered a ‘two-wave indexing’ method, as defined within the illustration under.
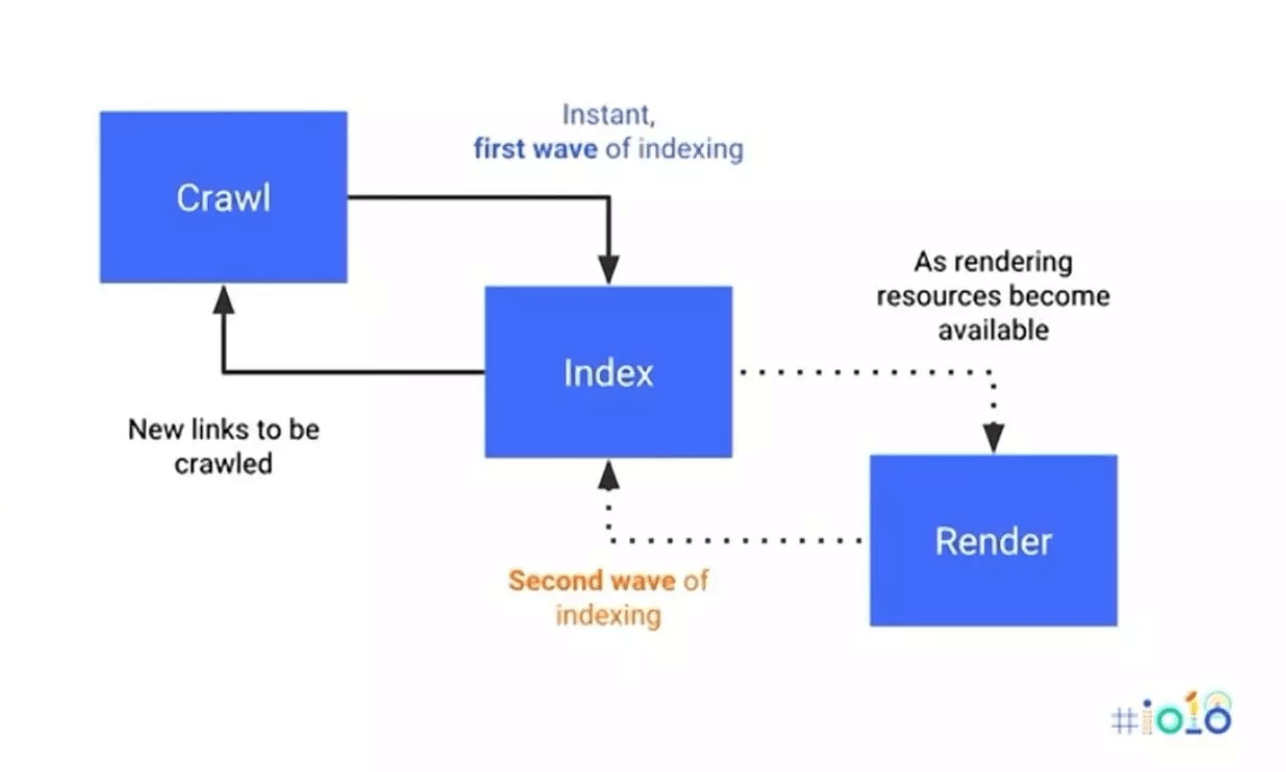
Supply: Search Engine Journal
The longer and extra complicated the method, the extra of the location’s crawl funds is used. This extra rendering step can rapidly deplete your crawl funds and result in lacking content material points. Usually, non-JavaScript net components are listed first, earlier than the JavaScript-generated content material is absolutely listed. Consequently, Google could rank the web page based mostly on incomplete info, ignoring the partially or totally uncrawled JavaScript content material.
The additional rendering step may considerably delay the indexation time, inflicting the web page to take days, weeks, and even months to seem on search engine outcomes.
We’ll present you later the right way to deal with crawl funds points particularly on JavaScript-heavy websites. For now, all it is advisable know is that crawl funds could possibly be a difficulty in case your website comprises a whole lot of JavaScript-based content material.
Now let’s check out the choices you need to optimize your website’s crawl funds typically!
Easy methods to optimize your web site’s crawl funds
The aim of crawl funds optimization is to maximise Google’s crawling of your pages, guaranteeing that they’re rapidly listed and ranked in search outcomes and that no necessary pages are missed.
There are two primary mechanisms to realize this:
- Enhance your web site’s crawl funds: Enhance the elements that may improve your website’s crawl price and crawl demand, similar to your server efficiency, web site reputation, content material high quality, and content material freshness.
- Get probably the most out of your current crawl funds: Hold Googlebot from crawling irrelevant pages in your website and direct it to necessary, high-value content material. This can make it simpler for Google to seek out your finest content material, which in flip would possibly improve its crawl demand.
Subsequent, we are going to share particular methods for each of those mechanisms, so let’s dive proper in.
5 methods to get probably the most out of your current crawl funds
1. Exclude low-value content material from crawling
When a search engine crawls low-value content material, it wastes your restricted crawl funds with out benefiting you. Examples of low-value pages embrace log-in pages, procuring carts, or your privateness coverage. These pages are often not supposed to rank in search outcomes, so there’s no want for Google to crawl them.
Whereas it’s not definitely not an enormous deal if Google crawls a handful of those pages, there are particular circumstances the place numerous low-value pages are created routinely and uncontrollably, and that’s the place you need to positively step in. An instance of this are so-called “infinite areas”. Infinite areas consult with part of a web site that may generate a vast variety of URLs. This sometimes occurs with dynamic content material that adapts to consumer selections, similar to calendars (e.g., each attainable date), search filters (e.g., an limitless mixture of filters and types) or user-generated content material (e.g., feedback).
Have a look at the instance under. A calendar with a “subsequent month” hyperlink in your website could make Google preserve following this hyperlink infinitely:
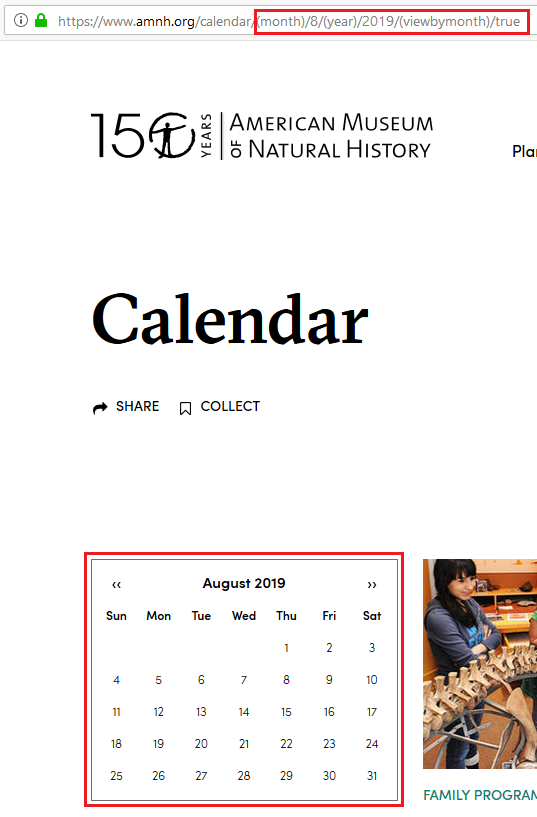
Screenshot of amnh.org
As you may see, every click on on the best arrow creates a brand new URL. Google may comply with this hyperlink perpetually, which might create an enormous mass of URLs that Google must retrieve one after the other.
Advisable answer: use robots.txt or ‘nofollow’
The simplest method to preserve Googlebot from following infinite areas is to exclude these areas of your web site from crawling in your robots.txt file. This file tells engines like google which areas of your web site they’re allowed or not allowed to crawl.
As an illustration, if you wish to stop Googlebot from crawling your calendar pages, you solely have to incorporate the next directive in your robots.txt file:
Disallow: /calendar/
Another methodology is to make use of the nofollow attribute for hyperlinks inflicting the infinite area. Though many SEOs advise in opposition to utilizing ‘nofollow’ for inner hyperlinks, it’s completely fantastic to make use of it in a situation like this.
Within the calendar instance above, nofollow can be utilized for the “subsequent month” hyperlink to forestall Googlebot from following and crawling it.
2. Remove duplicate content material
Just like low-value pages, there’s no want for Google to crawl duplicate content material pages, i.e. pages the place the identical or very related content material seems on a number of URLs. These pages are losing Google’s sources, as a result of it must crawl many URLs with out discovering new content material.
There are particular technical points that may result in numerous duplicate pages and which might be price listening to when you’re experiencing crawl funds points. One among these is lacking redirects between the www and non-www variations of a URL, or from HTTP to HTTPS.
Duplicate content material as a consequence of lacking redirects
If these common redirects should not arrange accurately, this will trigger the variety of URLs that may be crawled to double and even quadruple! For instance, the web page www.instance.com could possibly be obtainable beneath 4 URLs if no redirect was configured:
http://www.instance.com
https://www.instance.com
http://instance.com
https://instance.com
That’s positively not good in your website’s crawl funds!
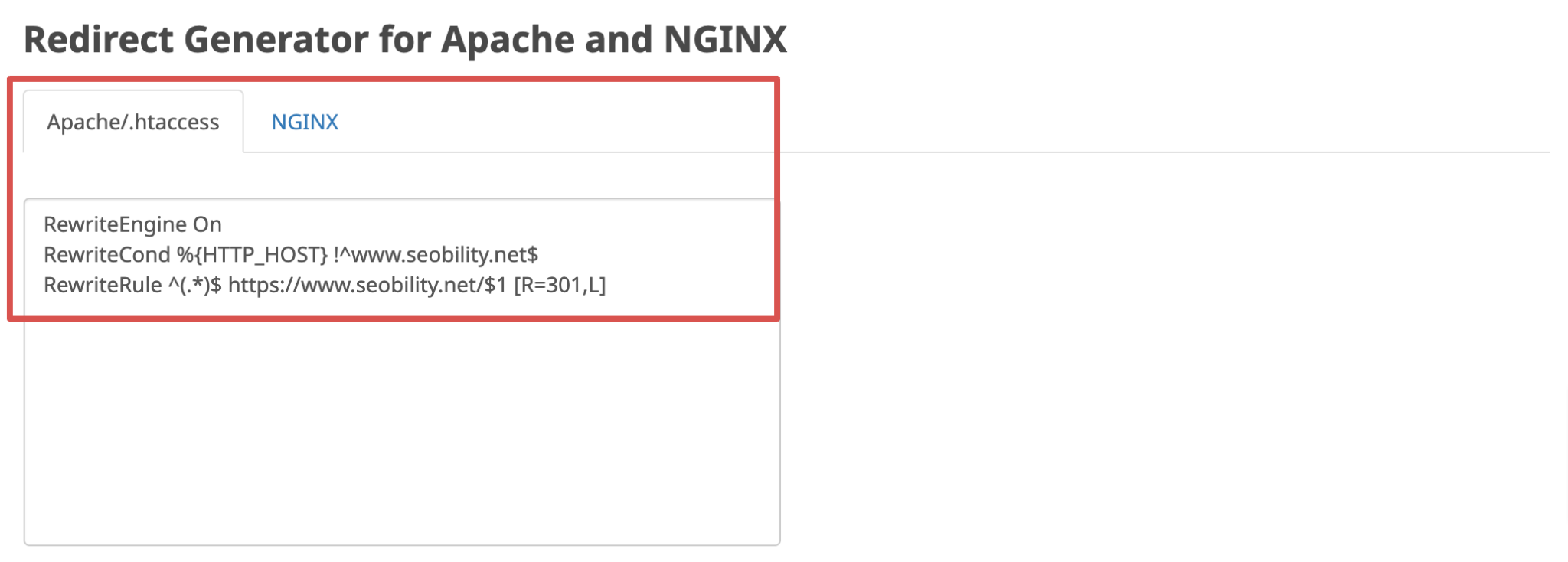
Advisable answer: Verify your redirects and proper them if mandatory
With Seobility’s free Redirect Checker, you may simply in case your web site’s WWW redirects are configured accurately. Simply enter your area and select the URL model that your guests ought to be redirected to by default:
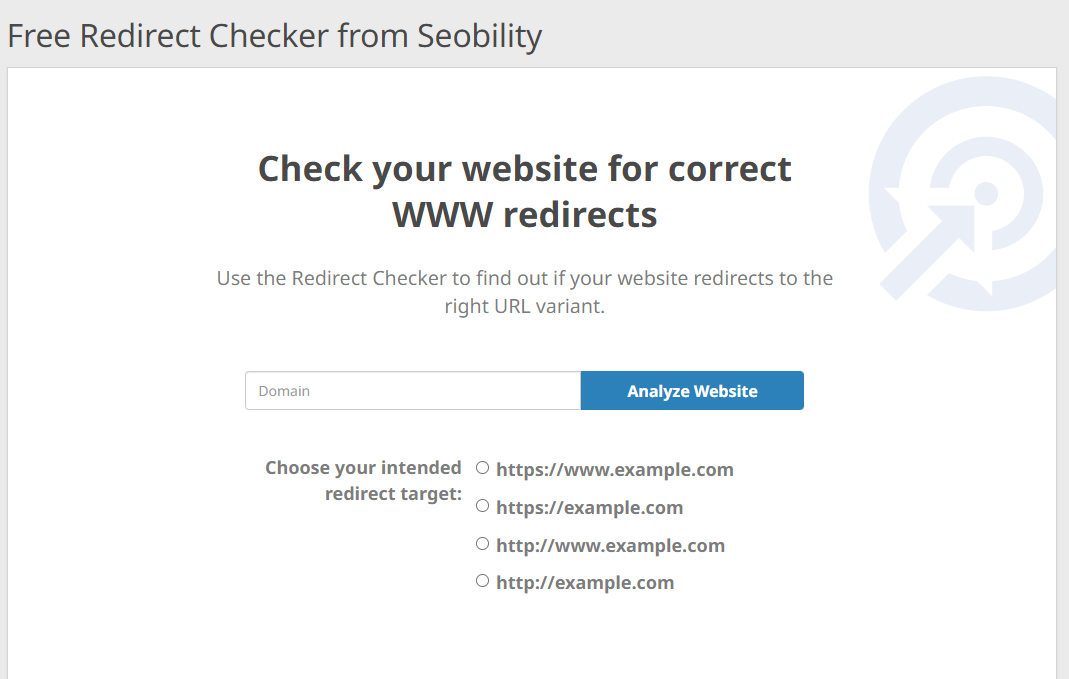
In case the device detects any points, you will see that the proper redirect code in your Apache or NGINX server within the Redirect Generator on the outcomes web page. This manner you may appropriate any damaged or lacking redirects and ensuing duplicate content material with just some clicks.
Duplicate content material as a consequence of URL parameters
One other technical problem that may result in the creation of numerous duplicate pages are URL parameters.
Many eCommerce web sites use URL parameters to let guests kind the merchandise on a class web page by completely different metrics similar to worth, relevance, evaluations, and so on.
For instance, an eCommerce website would possibly append the parameter ?kind=price_asc to the URL of its product overview web page to kind merchandise by worth, beginning with the bottom worth:
www.abc.com/merchandise?kind=price_asc
This might create a brand new URL containing the identical merchandise because the common web page, simply sorted in a distinct order. For websites with numerous classes and a number of sorting choices, this will simply add as much as a big variety of duplicate pages that waste crawl funds.
An identical downside happens with faceted navigation, which permits customers to slim the outcomes on a product class web page based mostly on standards similar to colour or measurement. That is completed by including URL parameters to the corresponding URL:
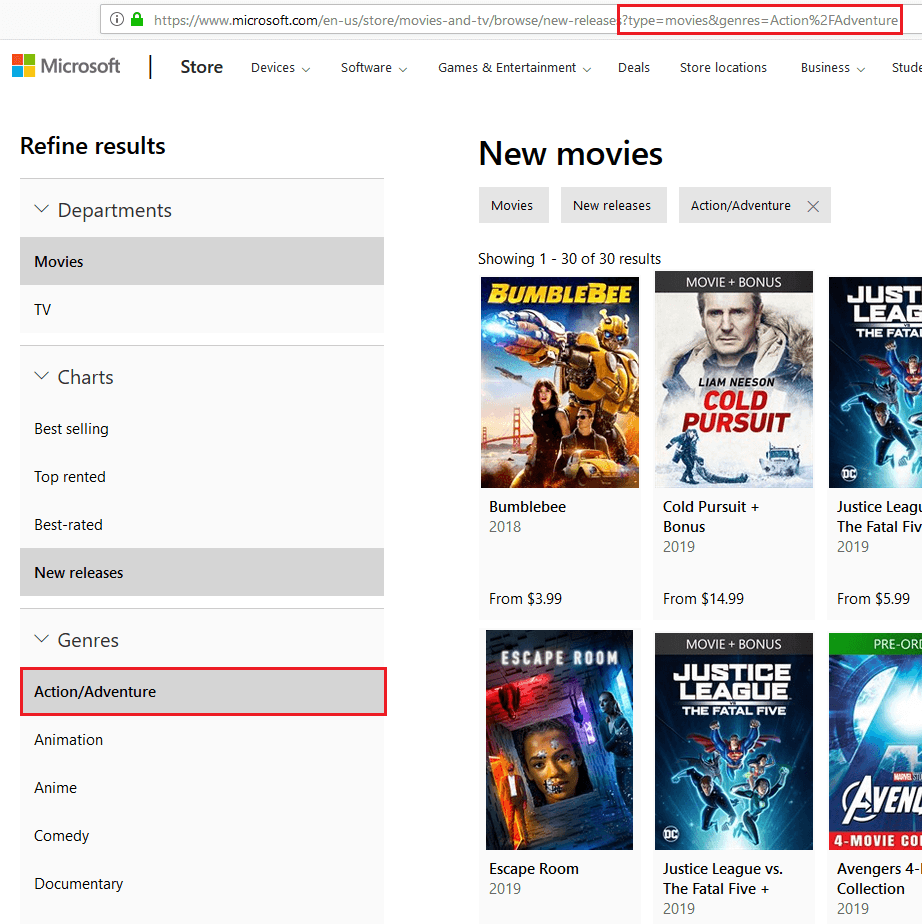
Screenshot from microsoft.com
Within the instance above, the outcomes are restricted to the Motion/Journey style by including the URL parameter &genres=Actionpercent2FAdventure to the URL. This creates a brand new URL that wastes the crawl funds as a result of the web page doesn’t present any new content material, only a snippet of the unique web page.
Advisable answer: robots.txt
As with low-value pages, the simplest method to preserve Googlebot away from these parameterized URLs is to exclude them from crawling in your robots.txt file. Within the examples above, we may disallow the parameters that we don’t need Google to crawl like this:
Disallow: /*?kind=
Disallow: /*&genres=Actionpercent2FAdventure
Disallow: /*?genres=Actionpercent2FAdventure
This method is the simplest method to cope with crawl funds points brought on by URL parameters, however remember the fact that it’s not the best answer for each scenario. An necessary draw back of this methodology is that if pages are excluded from crawling through robots.txt, Google will not be capable of discover necessary meta info similar to canonical tags on them, stopping Google from consolidating the rating indicators of the affected pages.
So if crawl funds just isn’t your major concern, one other methodology of dealing with parameters and faceted navigation could also be extra acceptable in your particular person scenario.
You could find in-depth guides on each subjects right here:
You must also keep away from utilizing URL parameters typically, except they’re completely mandatory. For instance, you need to not use URL parameters with session IDs. It’s higher to make use of cookies to switch session info.
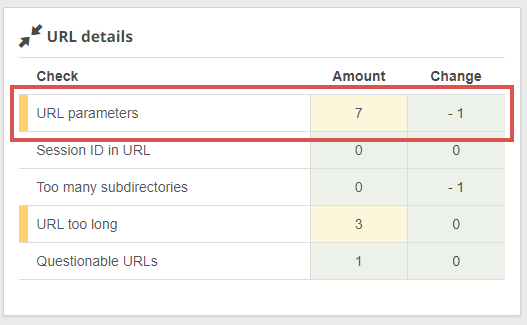
Tip: With Seobility’s Web site Audit, you may simply discover any URLs with parameters in your web site.
Seobility > Onpage > Tech. & Meta > URL particulars
Now you need to have understanding of the right way to deal with various kinds of low-value or duplicate pages to forestall them from draining your crawl funds. Let’s transfer on to the subsequent technique!
3. Optimize sources, similar to CSS and JavaScript recordsdata
As with HTML pages, each CSS and JavaScript file in your web site have to be accessed and crawled by Google, consuming a part of your crawl funds. This course of additionally will increase web page loading time, which might negatively have an effect on your rankings since web page velocity is an official Google rating issue.
Advisable answer: Minize the variety of recordsdata and/or implement a prerendering answer
Hold the variety of recordsdata you employ to a minimal by combining your CSS or JavaScript code into fewer recordsdata, and optimize the recordsdata you have got by eradicating pointless code.
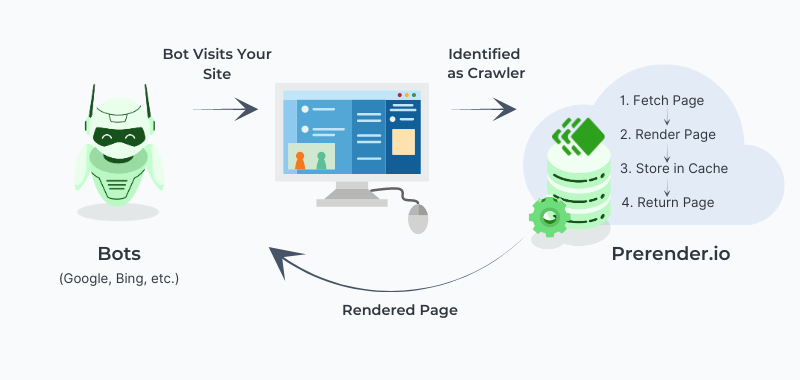
Nevertheless, when you web site makes use of a considerable amount of JavaScript, this is probably not sufficient and also you would possibly need to contemplate implementing a pre-rendering answer.
In easy phrases, prerendering is the method of turning your JavaScript content material into its HTML model, making it 100% index-ready. Consequently, you narrow the indexing time, use much less crawl funds, and get all of your content material and its search engine optimization components completely listed.
Prerender provides a prerendering answer that may considerably speed up your JavaScript web site’s indexing velocity by as much as 260%.
You’ll be able to study extra about prerendering and its advantages to your web site’s JavaScript search engine optimization right here.
4. Keep away from hyperlinks to redirects and redirect loops
If URL A redirects to URL B, Google has to request two URLs out of your net server earlier than it will get to the precise content material it desires to crawl. And you probably have a whole lot of redirects in your website, this will simply add up and drain your crawl funds.
The scenario is even worse with redirect loops. Redirect loops consult with an infinite loop between pages: Web page A > Web page B > Web page C > and again to Web page A, trapping Googlebot and costing your valuable crawl funds.
Advisable answer: Hyperlink on to the vacation spot URL and keep away from redirect chains
As an alternative of sending Google to a web page that redirects to a different URL, you need to at all times hyperlink to the precise vacation spot URL when utilizing inner hyperlinks.
Luckily, Seobility can show all of the redirecting pages in your website, so you may simply regulate the hyperlinks that presently level to redirecting pages:
Seobility > Onpage > Construction > Hyperlinks
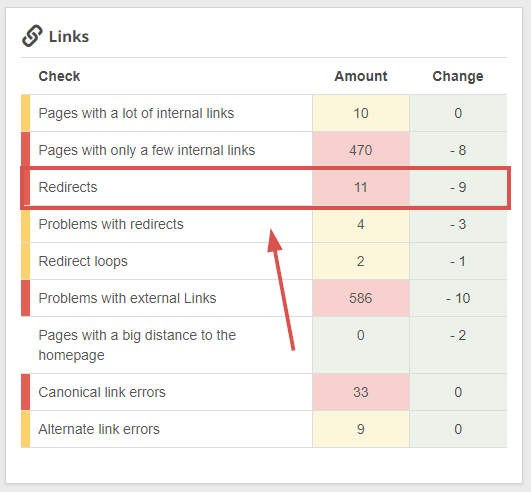
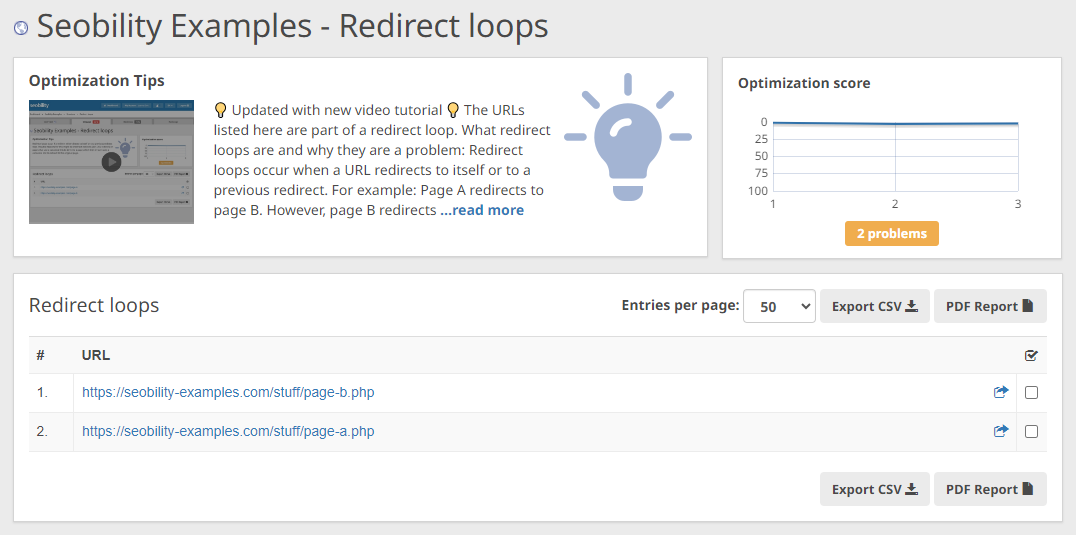
And with the “redirect loops” evaluation, you may see at a look if there are any pages which might be a part of an infinite redirect cycle.
Seobility > Onpage > Construction > Hyperlinks > Redirect loops
5. Keep away from delicate 404 error pages
Internet pages come and go. After they’ve been deleted, typically customers and Google nonetheless request them. When this occurs, the server ought to reply with a “404 Not Discovered” standing code (indicating that the web page doesn’t exist).
Nevertheless, as a consequence of some technical causes (e.g. customized error dealing with or CMS inner system settings) or the technology of dynamic JS content material, the server could return a “200 OK” standing code (indicating that the web page exists). This situation is named a delicate 404 error.
This mishandling indicators Google that the web page does exist and can preserve crawling it till the error is mounted – costing you your helpful crawl funds.
Advisable answer: Configure your server to return an acceptable standing code
Google will let you realize of any delicate 404 errors in your web site in Search Console:
Google Search Console > Web page indexing > Mushy 404s
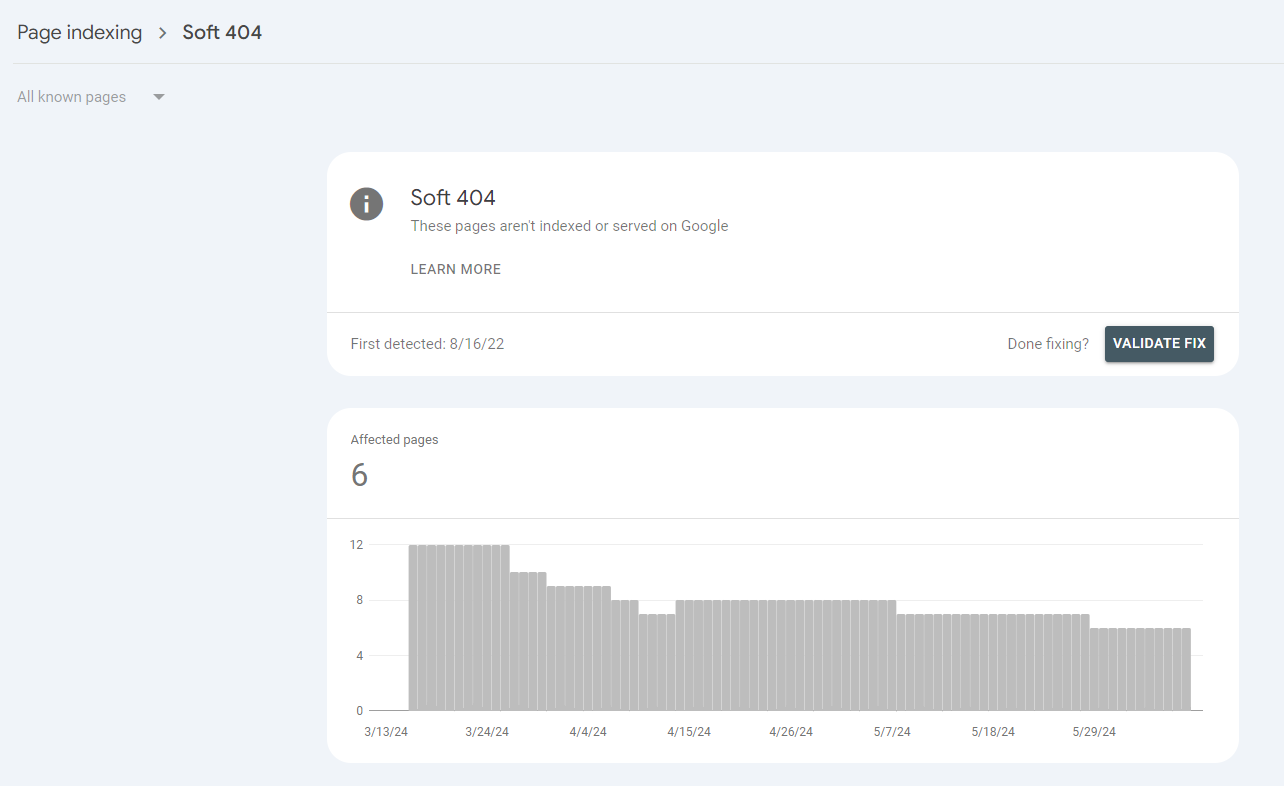
To eliminate delicate 404 errors, you principally have three choices:
- If the content material of the web page not exists, you need to be sure that your server returns a 404 standing code.
- If the content material has been moved to a distinct location, you need to redirect the web page with a 301 redirect and exchange any inner hyperlinks to level to the brand new URL.
- If the web page is incorrectly categorized as a delicate 404 web page (e.g. due to skinny content material), bettering the standard of the web page content material could resolve the error.
For extra particulars, take a look at our wiki article on delicate 404 errors.
6. Make it straightforward for Google to seek out your high-quality content material
To additional maximize your crawl funds, you shouldn’t solely preserve Googlebot away from low-quality or irrelevant content material, but in addition information it towards your high-quality content material. Crucial components that will help you obtain this are:
- XML sitemaps
- Inside hyperlinks
- Flat website structure
Present an XML sitemap
An XML sitemap offers Google with a transparent overview of your web site’s content material and is an effective way to inform Google which pages you need crawled and listed. This hastens crawling and reduces the chance that high-quality and necessary content material will go undetected.
Use inner hyperlinks strategically
Since search engine bots navigate web sites by following inner hyperlinks, you should utilize them strategically to direct crawlers to particular pages. That is particularly useful for pages that you simply need to be crawled extra steadily. For instance, by linking to those pages from pages with robust backlinks and excessive site visitors, you may be sure that they’re crawled extra usually.
We additionally suggest that you simply hyperlink necessary sub-pages broadly all through your website to sign their relevance to Google. Additionally, these pages shouldn’t be too distant out of your homepage.
Try this information on the right way to optimize your web site’s inner hyperlinks for extra particulars on the right way to implement the following tips.
Use a flat website structure
Flat website structure menas that every one subpages of your web site ought to be not more than 4 to five clicks away out of your homepage. This helps Googlebot to grasp the construction of your web site and saves your crawl funds from difficult crawling.
With Seobility, you may simply analyze the press distance of your pages:
Seobility > Onpage > Construction > Web page ranges
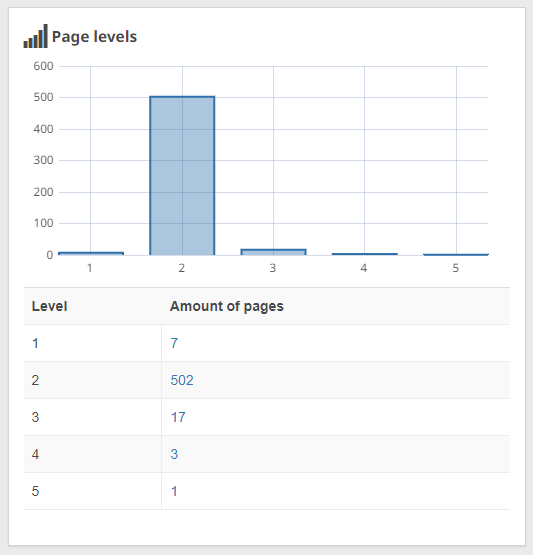
If any of your necessary pages are greater than 5 clicks away out of your homepage, you need to attempt to discover a place to hyperlink to them at the next stage in order that they received’t be neglected by Google.
Two methods to extend your crawl funds
Thus far we’ve targeted on methods to get probably the most out of your current crawl funds however as we’ve talked about to start with, there are additionally methods to extend the full crawl funds that Google assigns to your web site.
As a reminder, there are two primary elements that decide your crawl funds: crawl price and crawl demand. So if you wish to improve your web site’s total crawl funds, these are the 2 important elements you may work on.
Growing the crawl price
Crawl price is extremely dependent in your server efficiency and response time. Normally, the upper your server efficiency and the sooner its response time, the extra seemingly Google is to extend its crawl price.
Nevertheless, it will solely occur if there’s enough crawl demand. Enhancing your server efficiency is ineffective if Google doesn’t need to crawl your content material.
For those who can’t improve your server, there are a number of on-page strategies you may implement to scale back the load in your server. These embrace implementing caching, optimizing and lazy-loading your photos, and enabling GZip compression.
This web page velocity optimization information explains the right way to implement the following tips in addition to many different strategies to enhance your server response instances and web page velocity typically.
Growing crawl demand
When you can’t actively management what number of pages Google desires to crawl, there are some things you are able to do to extend the possibilities that Google will need to spend extra time in your web site:
- Keep away from skinny or spammy content material. As an alternative, give attention to offering high-quality, helpful content material.
- Implement the methods we’ve outlined above to maximise your crawl funds. By guaranteeing that Google solely encounters related, high-quality content material, you create an setting the place the search engine acknowledges the worth of your website and prioritizes crawling it extra steadily. This indicators to Google that your website is price exploring in better depth, finally growing crawl demand.
- Construct robust backlinks, improve consumer engagement, and share your pages on social media. These will assist improve your web site’s reputation and generate real curiosity.
- Hold your content material contemporary, as Google prioritizes probably the most present and high-quality content material for its customers.
At this level, you need to be outfitted with a big arsenal of methods that will help you eliminate any crawl funds issues in your website. Lastly, we’ll go away you with some tips about the right way to monitor the progress of your crawl funds optimization.
Easy methods to monitor your crawl funds optimization progress
Like many search engine optimization duties, crawl funds optimization isn’t a one-day course of. It requires common monitoring and fine-tuning to make sure that Google simply finds the necessary pages of your website.
The next reviews may also help you regulate how your website is being crawled by Google.
Crawl stats in Google Search Console
On this report, you may see the variety of pages crawled per day in your website over the previous 90 days.
Settings > Crawl Stats > Open report
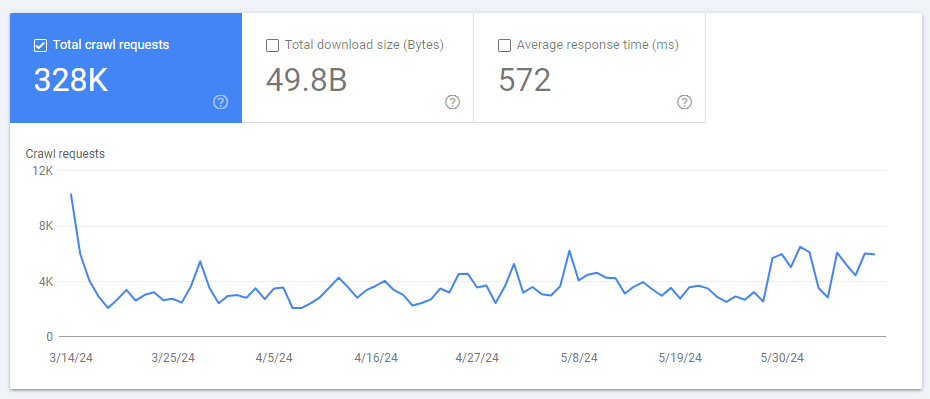
A sudden drop in crawl requests can point out issues which might be stopping Google from efficiently crawling your website. However, in case your optimization efforts are profitable, you need to see a rise in crawl requests.
Nevertheless, you need to be cautious when you see a very sudden spike in crawl requests! This might sign new issues, similar to infinite loops or huge quantities of spam content material created by a hacker assault in your website. In these circumstances, Google must crawl many new URLs.
With the intention to decide the precise explanation for a sudden improve on this metric, it’s a good suggestion to investigate your server log recordsdata.
Log file evaluation
Internet servers use log recordsdata to trace every go to to your web site, storing info like IP deal with, consumer agent, and so on. By analyzing your log recordsdata, you will discover out which pages Googlebot crawls extra steadily and whether or not they’re the best (i.e., related) pages. As well as, you will discover out if there are some pages which might be crucial out of your perspective, however that aren’t being crawled by Google in any respect.
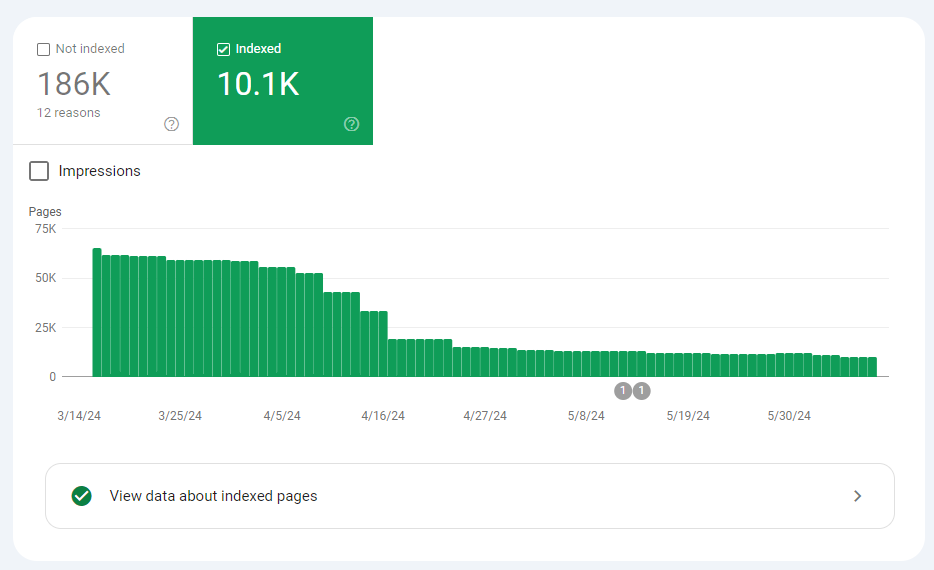
Index protection report
This report in Search Console reveals you what number of pages of your web site are literally listed by Google, and the precise the explanation why the opposite pages should not.
Google Search Console > Indexing > Pages
Optimize your crawl funds for more healthy search engine optimization efficiency
Relying on the dimensions of your web site, crawl funds can play a crucial function within the rating of your content material. With out correct administration, engines like google could wrestle to index your content material, doubtlessly losing your efforts in creating high-quality content material.
Moreover, the affect of poor crawl funds administration is amplified for JavaScript-based web sites, as dynamic JS content material requires extra crawl funds for indexing. Subsequently, relying solely on Google to index your content material can stop you from realizing your website’s true search engine optimization potential.
You probably have any questions, be happy to depart them within the feedback!
PS: Get weblog updates straight to your inbox!

